 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMOSS-VoiceGenerator: Create Realistic Voices with Natural Language Descriptions
Mar 30, 2026Voice design from natural language aims to generate speaker timbres directly from free-form textual descriptions, allowing users to create voices tailored to specific roles, personalities, and emotions. Such controllable voice creation benefits a wide range of downstream applications-including storytelling, game dubbing, role-play agents, and conversational assistants, making it a significant task for modern Text-to-Speech models. However, existing models are largely trained on carefully recorded studio data, which produces speech that is clean and well-articulated, yet lacks the lived-in qualities of real human voices. To address these limitations, we present MOSS-VoiceGenerator, an open-source instruction-driven voice generation model that creates new timbres directly from natural language prompts. Motivated by the hypothesis that exposure to real-world acoustic variation produces more perceptually natural voices, we train on large-scale expressive speech data sourced from cinematic content. Subjective preference studies demonstrate its superiority in overall performance, instruction-following, and naturalness compared to other voice design models.
MOSS-TTSD: Text to Spoken Dialogue Generation
Mar 20, 2026Spoken dialogue generation is crucial for applications like podcasts, dynamic commentary, and entertainment content, but poses significant challenges compared to single-utterance text-to-speech (TTS). Key requirements include accurate turn-taking, cross-turn acoustic consistency, and long-form stability, which current models often fail to address due to a lack of dialogue context modeling. To bridge this gap, we present MOSS-TTSD, a spoken dialogue synthesis model designed for expressive, multi-party conversational speech across multiple languages. With enhanced long-context modeling, MOSS-TTSD generates long-form spoken conversations from dialogue scripts with explicit speaker tags, supporting up to 60 minutes of single-pass synthesis, multi-party dialogue with up to 5 speakers, and zero-shot voice cloning from a short reference audio clip. The model supports various mainstream languages, including English and Chinese, and is adapted to several long-form scenarios. Additionally, to address limitations of existing evaluation methods, we propose TTSD-eval, an objective evaluation framework based on forced alignment that measures speaker attribution accuracy and speaker similarity without relying on speaker diarization tools. Both objective and subjective evaluation results show that MOSS-TTSD surpasses strong open-source and proprietary baselines in dialogue synthesis.
MOSS-TTS Technical Report
Mar 18, 2026This technical report presents MOSS-TTS, a speech generation foundation model built on a scalable recipe: discrete audio tokens, autoregressive modeling, and large-scale pretraining. Built on MOSS-Audio-Tokenizer, a causal Transformer tokenizer that compresses 24 kHz audio to 12.5 fps with variable-bitrate RVQ and unified semantic-acoustic representations, we release two complementary generators: MOSS-TTS, which emphasizes structural simplicity, scalability, and long-context/control-oriented deployment, and MOSS-TTS-Local-Transformer, which introduces a frame-local autoregressive module for higher modeling efficiency, stronger speaker preservation, and a shorter time to first audio. Across multilingual and open-domain settings, MOSS-TTS supports zero-shot voice cloning, token-level duration control, phoneme-/pinyin-level pronunciation control, smooth code-switching, and stable long-form generation. This report summarizes the design, training recipe, and empirical characteristics of the released models.
WESR: Scaling and Evaluating Word-level Event-Speech Recognition
Jan 08, 2026Speech conveys not only linguistic information but also rich non-verbal vocal events such as laughing and crying. While semantic transcription is well-studied, the precise localization of non-verbal events remains a critical yet under-explored challenge. Current methods suffer from insufficient task definitions with limited category coverage and ambiguous temporal granularity. They also lack standardized evaluation frameworks, hindering the development of downstream applications. To bridge this gap, we first develop a refined taxonomy of 21 vocal events, with a new categorization into discrete (standalone) versus continuous (mixed with speech) types. Based on the refined taxonomy, we introduce WESR-Bench, an expert-annotated evaluation set (900+ utterances) with a novel position-aware protocol that disentangles ASR errors from event detection, enabling precise localization measurement for both discrete and continuous events. We also build a strong baseline by constructing a 1,700+ hour corpus, and train specialized models, surpassing both open-source audio-language models and commercial APIs while preserving ASR quality. We anticipate that WESR will serve as a foundational resource for future research in modeling rich, real-world auditory scenes.
UnifiedVisual: A Framework for Constructing Unified Vision-Language Datasets
Sep 18, 2025Unified vision large language models (VLLMs) have recently achieved impressive advancements in both multimodal understanding and generation, powering applications such as visual question answering and text-guided image synthesis. However, progress in unified VLLMs remains constrained by the lack of datasets that fully exploit the synergistic potential between these two core abilities. Existing datasets typically address understanding and generation in isolation, thereby limiting the performance of unified VLLMs. To bridge this critical gap, we introduce a novel dataset construction framework, UnifiedVisual, and present UnifiedVisual-240K, a high-quality dataset meticulously designed to facilitate mutual enhancement between multimodal understanding and generation. UnifiedVisual-240K seamlessly integrates diverse visual and textual inputs and outputs, enabling comprehensive cross-modal reasoning and precise text-to-image alignment. Our dataset encompasses a wide spectrum of tasks and data sources, ensuring rich diversity and addressing key shortcomings of prior resources. Extensive experiments demonstrate that models trained on UnifiedVisual-240K consistently achieve strong performance across a wide range of tasks. Notably, these models exhibit significant mutual reinforcement between multimodal understanding and generation, further validating the effectiveness of our framework and dataset. We believe UnifiedVisual represents a new growth point for advancing unified VLLMs and unlocking their full potential. Our code and datasets is available at https://github.com/fnlp-vision/UnifiedVisual.
Decoupled Proxy Alignment: Mitigating Language Prior Conflict for Multimodal Alignment in MLLM
Sep 18, 2025Multimodal large language models (MLLMs) have gained significant attention due to their impressive ability to integrate vision and language modalities. Recent advancements in MLLMs have primarily focused on improving performance through high-quality datasets, novel architectures, and optimized training strategies. However, in this paper, we identify a previously overlooked issue, language prior conflict, a mismatch between the inherent language priors of large language models (LLMs) and the language priors in training datasets. This conflict leads to suboptimal vision-language alignment, as MLLMs are prone to adapting to the language style of training samples. To address this issue, we propose a novel training method called Decoupled Proxy Alignment (DPA). DPA introduces two key innovations: (1) the use of a proxy LLM during pretraining to decouple the vision-language alignment process from language prior interference, and (2) dynamic loss adjustment based on visual relevance to strengthen optimization signals for visually relevant tokens. Extensive experiments demonstrate that DPA significantly mitigates the language prior conflict, achieving superior alignment performance across diverse datasets, model families, and scales. Our method not only improves the effectiveness of MLLM training but also shows exceptional generalization capabilities, making it a robust approach for vision-language alignment. Our code is available at https://github.com/fnlp-vision/DPA.
Prior-Fitted Networks Scale to Larger Datasets When Treated as Weak Learners
Mar 03, 2025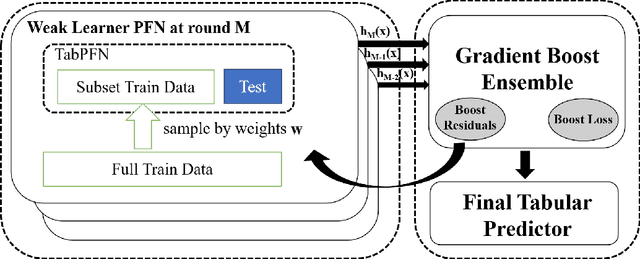

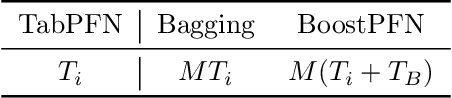
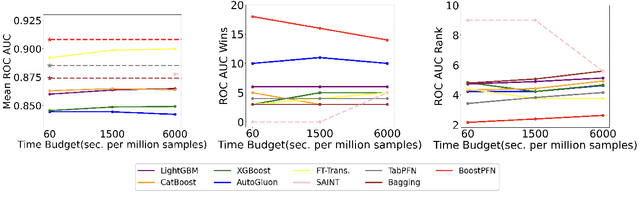
Prior-Fitted Networks (PFNs) have recently been proposed to efficiently perform tabular classification tasks. Although they achieve good performance on small datasets, they encounter limitations with larger datasets. These limitations include significant memory consumption and increased computational complexity, primarily due to the impracticality of incorporating all training samples as inputs within these networks. To address these challenges, we investigate the fitting assumption for PFNs and input samples. Building on this understanding, we propose \textit{BoostPFN} designed to enhance the performance of these networks, especially for large-scale datasets. We also theoretically validate the convergence of BoostPFN and our empirical results demonstrate that the BoostPFN method can outperform standard PFNs with the same size of training samples in large datasets and achieve a significant acceleration in training times compared to other established baselines in the field, including widely-used Gradient Boosting Decision Trees (GBDTs), deep learning methods and AutoML systems. High performance is maintained for up to 50x of the pre-training size of PFNs, substantially extending the limit of training samples. Through this work, we address the challenges of efficiently handling large datasets via PFN-based models, paving the way for faster and more effective tabular data classification training and prediction process. Code is available at Github.
Advancing Fine-Grained Visual Understanding with Multi-Scale Alignment in Multi-Modal Models
Nov 14, 2024
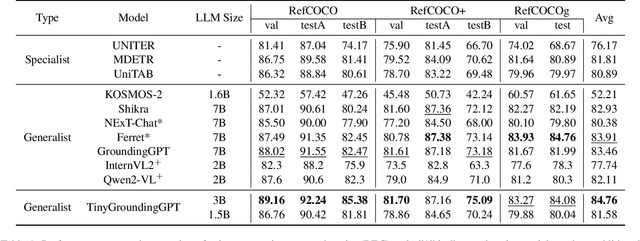
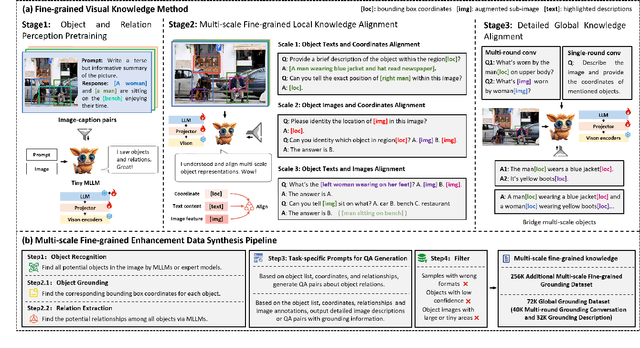
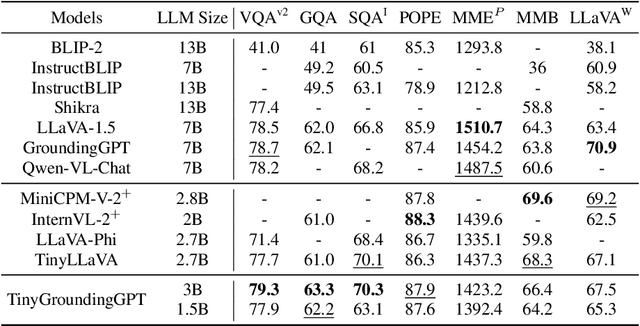
Multi-modal large language models (MLLMs) have achieved remarkable success in fine-grained visual understanding across a range of tasks. However, they often encounter significant challenges due to inadequate alignment for fine-grained knowledge, which restricts their ability to accurately capture local details and attain a comprehensive global perception. While recent advancements have focused on aligning object expressions with grounding information, they typically lack explicit integration of object images, which contain affluent information beyond mere texts or coordinates. To bridge this gap, we introduce a novel fine-grained visual knowledge alignment method that effectively aligns and integrates multi-scale knowledge of objects, including texts, coordinates, and images. This innovative method is underpinned by our multi-scale fine-grained enhancement data synthesis pipeline, which provides over 300K essential training data to enhance alignment and improve overall performance. Furthermore, we present TinyGroundingGPT, a series of compact models optimized for high-level alignments. With a scale of approximately 3B parameters, TinyGroundingGPT achieves outstanding results in grounding tasks while delivering performance comparable to larger MLLMs in complex visual scenarios.
Understanding the Role of LLMs in Multimodal Evaluation Benchmarks
Oct 16, 2024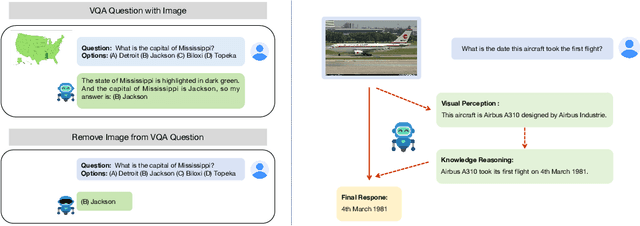
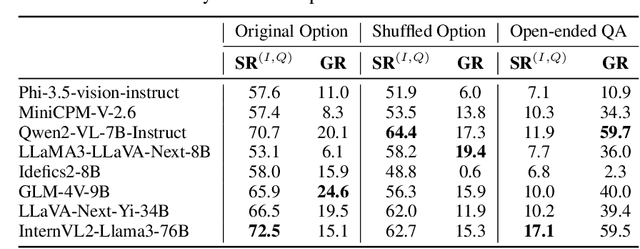
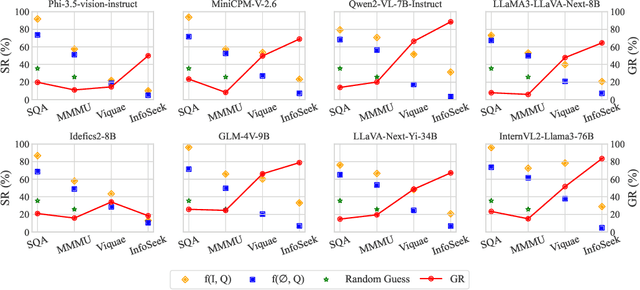
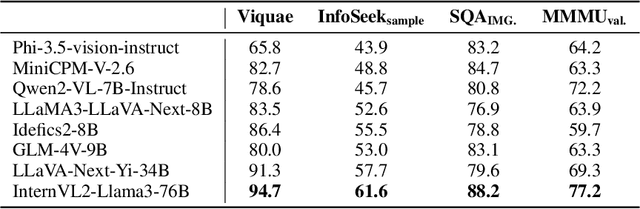
The rapid advancement of Multimodal Large Language Models (MLLMs) has been accompanied by the development of various benchmarks to evaluate their capabilities. However, the true nature of these evaluations and the extent to which they assess multimodal reasoning versus merely leveraging the underlying Large Language Model (LLM) backbone remain unclear. This paper presents a comprehensive investigation into the role of LLM backbones in MLLM evaluation, focusing on two critical aspects: the degree to which current benchmarks truly assess multimodal reasoning and the influence of LLM prior knowledge on performance. Specifically, we introduce a modified evaluation protocol to disentangle the contributions of the LLM backbone from multimodal integration, and an automatic knowledge identification technique for diagnosing whether LLMs equip the necessary knowledge for corresponding multimodal questions. Our study encompasses four diverse MLLM benchmarks and eight state-of-the-art MLLMs. Key findings reveal that some benchmarks allow high performance even without visual inputs and up to 50\% of error rates can be attributed to insufficient world knowledge in the LLM backbone, indicating a heavy reliance on language capabilities. To address knowledge deficiencies, we propose a knowledge augmentation pipeline that achieves significant performance gains, with improvements of up to 60\% on certain datasets, resulting in a approximately 4x increase in performance. Our work provides crucial insights into the role of the LLM backbone in MLLMs, and highlights the need for more nuanced benchmarking approaches.
UnifiedMLLM: Enabling Unified Representation for Multi-modal Multi-tasks With Large Language Model
Aug 05, 2024
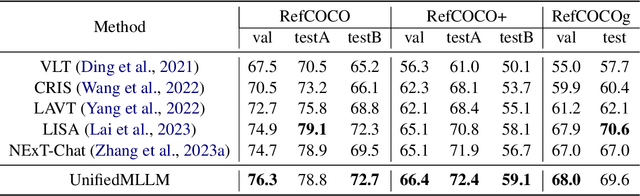
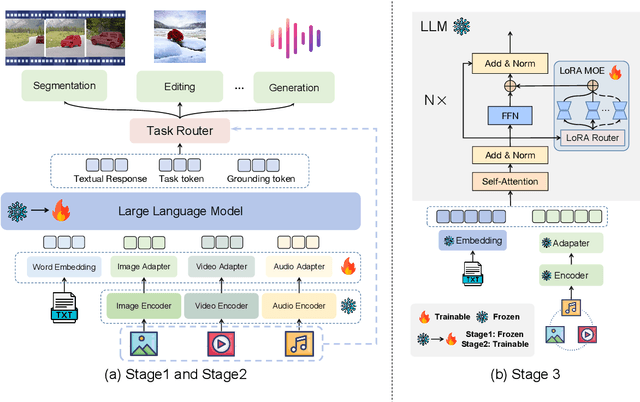

Significant advancements has recently been achieved in the field of multi-modal large language models (MLLMs), demonstrating their remarkable capabilities in understanding and reasoning across diverse tasks. However, these models are often trained for specific tasks and rely on task-specific input-output formats, limiting their applicability to a broader range of tasks. This raises a fundamental question: Can we develop a unified approach to represent and handle different multi-modal tasks to maximize the generalizability of MLLMs? In this paper, we propose UnifiedMLLM, a comprehensive model designed to represent various tasks using a unified representation. Our model exhibits strong capabilities in comprehending the implicit intent of user instructions and preforming reasoning. In addition to generating textual responses, our model also outputs task tokens and grounding tokens, serving as indicators of task types and task granularity. These outputs are subsequently routed through the task router and directed to specific expert models for task completion. To train our model, we construct a task-specific dataset and an 100k multi-task dataset encompassing complex scenarios. Employing a three-stage training strategy, we equip our model with robust reasoning and task processing capabilities while preserving its generalization capacity and knowledge reservoir. Extensive experiments showcase the impressive performance of our unified representation approach across various tasks, surpassing existing methodologies. Furthermore, our approach exhibits exceptional scalability and generality. Our code, model, and dataset will be available at \url{https://github.com/lzw-lzw/UnifiedMLLM}.