 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning 3D Medical Image Models From Brain Functional Connectivity Network Supervision For Mental Disorder Diagnosis
Mar 06, 2025



In MRI-based mental disorder diagnosis, most previous studies focus on functional connectivity network (FCN) derived from functional MRI (fMRI). However, the small size of annotated fMRI datasets restricts its wide application. Meanwhile, structural MRIs (sMRIs), such as 3D T1-weighted (T1w) MRI, which are commonly used and readily accessible in clinical settings, are often overlooked. To integrate the complementary information from both function and structure for improved diagnostic accuracy, we propose CINP (Contrastive Image-Network Pre-training), a framework that employs contrastive learning between sMRI and FCN. During pre-training, we incorporate masked image modeling and network-image matching to enhance visual representation learning and modality alignment. Since the CINP facilitates knowledge transfer from FCN to sMRI, we introduce network prompting. It utilizes only sMRI from suspected patients and a small amount of FCNs from different patient classes for diagnosing mental disorders, which is practical in real-world clinical scenario. The competitive performance on three mental disorder diagnosis tasks demonstrate the effectiveness of the CINP in integrating multimodal MRI information, as well as the potential of incorporating sMRI into clinical diagnosis using network prompting.
PyOD 2: A Python Library for Outlier Detection with LLM-powered Model Selection
Dec 11, 2024
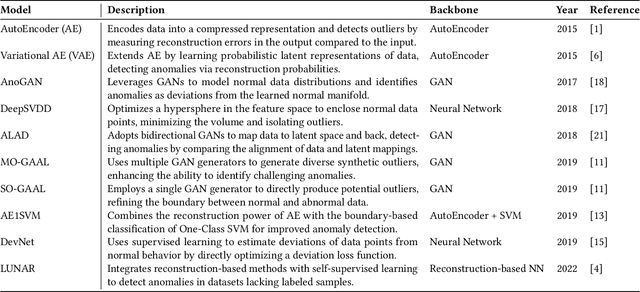

Outlier detection (OD), also known as anomaly detection, is a critical machine learning (ML) task with applications in fraud detection, network intrusion detection, clickstream analysis, recommendation systems, and social network moderation. Among open-source libraries for outlier detection, the Python Outlier Detection (PyOD) library is the most widely adopted, with over 8,500 GitHub stars, 25 million downloads, and diverse industry usage. However, PyOD currently faces three limitations: (1) insufficient coverage of modern deep learning algorithms, (2) fragmented implementations across PyTorch and TensorFlow, and (3) no automated model selection, making it hard for non-experts. To address these issues, we present PyOD Version 2 (PyOD 2), which integrates 12 state-of-the-art deep learning models into a unified PyTorch framework and introduces a large language model (LLM)-based pipeline for automated OD model selection. These improvements simplify OD workflows, provide access to 45 algorithms, and deliver robust performance on various datasets. In this paper, we demonstrate how PyOD 2 streamlines the deployment and automation of OD models and sets a new standard in both research and industry. PyOD 2 is accessible at [https://github.com/yzhao062/pyod](https://github.com/yzhao062/pyod). This study aligns with the Web Mining and Content Analysis track, addressing topics such as the robustness of Web mining methods and the quality of algorithmically-generated Web data.
Advancing Fine-Grained Visual Understanding with Multi-Scale Alignment in Multi-Modal Models
Nov 14, 2024
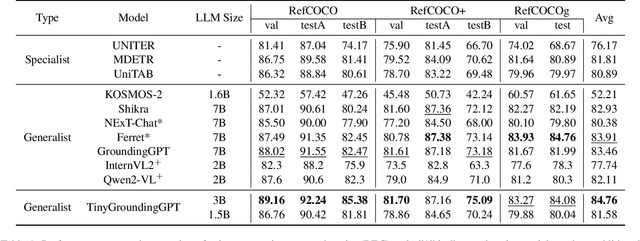
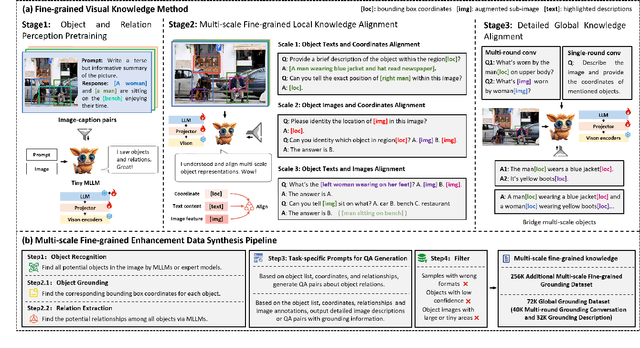
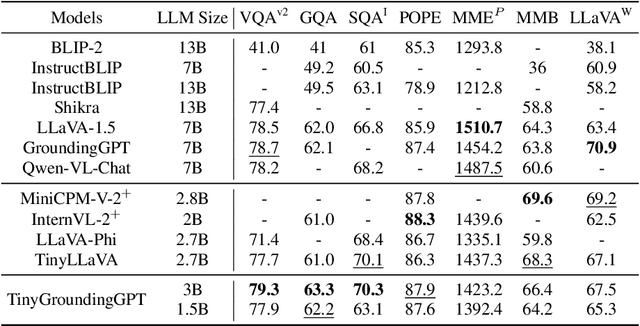
Multi-modal large language models (MLLMs) have achieved remarkable success in fine-grained visual understanding across a range of tasks. However, they often encounter significant challenges due to inadequate alignment for fine-grained knowledge, which restricts their ability to accurately capture local details and attain a comprehensive global perception. While recent advancements have focused on aligning object expressions with grounding information, they typically lack explicit integration of object images, which contain affluent information beyond mere texts or coordinates. To bridge this gap, we introduce a novel fine-grained visual knowledge alignment method that effectively aligns and integrates multi-scale knowledge of objects, including texts, coordinates, and images. This innovative method is underpinned by our multi-scale fine-grained enhancement data synthesis pipeline, which provides over 300K essential training data to enhance alignment and improve overall performance. Furthermore, we present TinyGroundingGPT, a series of compact models optimized for high-level alignments. With a scale of approximately 3B parameters, TinyGroundingGPT achieves outstanding results in grounding tasks while delivering performance comparable to larger MLLMs in complex visual scenarios.