 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStableQAT: Stable Quantization-Aware Training at Ultra-Low Bitwidths
Jan 27, 2026Quantization-aware training (QAT) is essential for deploying large models under strict memory and latency constraints, yet achieving stable and robust optimization at ultra-low bitwidths remains challenging. Common approaches based on the straight-through estimator (STE) or soft quantizers often suffer from gradient mismatch, instability, or high computational overhead. As such, we propose StableQAT, a unified and efficient QAT framework that stabilizes training in ultra low-bit settings via a novel, lightweight, and theoretically grounded surrogate for backpropagation derived from a discrete Fourier analysis of the rounding operator. StableQAT strictly generalizes STE as the latter arises as a special case of our more expressive surrogate family, yielding smooth, bounded, and inexpensive gradients that improve QAT training performance and stability across various hyperparameter choices. In experiments, StableQAT exhibits stable and efficient QAT at 2-4 bit regimes, demonstrating improved training stability, robustness, and superior performance with negligible training overhead against standard QAT techniques. Our code is available at https://github.com/microsoft/StableQAT.
StreetDesignAI: A Multi-Persona Evaluation System for Inclusive Infrastructure Design
Jan 22, 2026Designing inclusive cycling infrastructure requires balancing competing needs of diverse user groups, yet designers often struggle to anticipate how different cyclists experience the same street. We investigate how persona-based multi-agent evaluation can support inclusive design by making experiential conflicts explicit. We present StreetDesignAI, an interactive system that enables designers to (1) ground evaluation in street context through imagery and map data, (2) receive parallel feedback from cyclist personas spanning confident to cautious users, and (3) iteratively modify designs while surfacing conflicts across perspectives. A within-subjects study with 26 transportation professionals demonstrates that structured multi-perspective feedback significantly improves designers' understanding of diverse user perspectives, ability to identify persona needs, and confidence in translating them into design decisions, with higher satisfaction and stronger intention for professional adoption. Qualitative findings reveal how conflict surfacing transforms design exploration from single-perspective optimization toward deliberate trade-off reasoning. We discuss implications for AI tools that scaffold inclusive design through disagreement as an interaction primitive.
A Fully Generative Motivational Interviewing Counsellor Chatbot for Moving Smokers Towards the Decision to Quit
May 26, 2025The conversational capabilities of Large Language Models (LLMs) suggest that they may be able to perform as automated talk therapists. It is crucial to know if these systems would be effective and adhere to known standards. We present a counsellor chatbot that focuses on motivating tobacco smokers to quit smoking. It uses a state-of-the-art LLM and a widely applied therapeutic approach called Motivational Interviewing (MI), and was evolved in collaboration with clinician-scientists with expertise in MI. We also describe and validate an automated assessment of both the chatbot's adherence to MI and client responses. The chatbot was tested on 106 participants, and their confidence that they could succeed in quitting smoking was measured before the conversation and one week later. Participants' confidence increased by an average of 1.7 on a 0-10 scale. The automated assessment of the chatbot showed adherence to MI standards in 98% of utterances, higher than human counsellors. The chatbot scored well on a participant-reported metric of perceived empathy but lower than typical human counsellors. Furthermore, participants' language indicated a good level of motivation to change, a key goal in MI. These results suggest that the automation of talk therapy with a modern LLM has promise.
WINA: Weight Informed Neuron Activation for Accelerating Large Language Model Inference
May 26, 2025The growing computational demands of large language models (LLMs) make efficient inference and activation strategies increasingly critical. While recent approaches, such as Mixture-of-Experts (MoE), leverage selective activation but require specialized training, training-free sparse activation methods offer broader applicability and superior resource efficiency through their plug-and-play design. However, many existing methods rely solely on hidden state magnitudes to determine activation, resulting in high approximation errors and suboptimal inference accuracy. To address these limitations, we propose WINA (Weight Informed Neuron Activation), a novel, simple, and training-free sparse activation framework that jointly considers hidden state magnitudes and the column-wise $\ell_2$-norms of weight matrices. We show that this leads to a sparsification strategy that obtains optimal approximation error bounds with theoretical guarantees tighter than existing techniques. Empirically, WINA also outperforms state-of-the-art methods (e.g., TEAL) by up to $2.94\%$ in average performance at the same sparsity levels, across a diverse set of LLM architectures and datasets. These results position WINA as a new performance frontier for training-free sparse activation in LLM inference, advancing training-free sparse activation methods and setting a robust baseline for efficient inference. The source code is available at https://github.com/microsoft/wina.
SymRTLO: Enhancing RTL Code Optimization with LLMs and Neuron-Inspired Symbolic Reasoning
Apr 14, 2025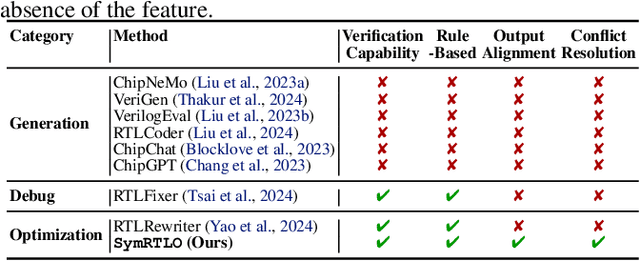
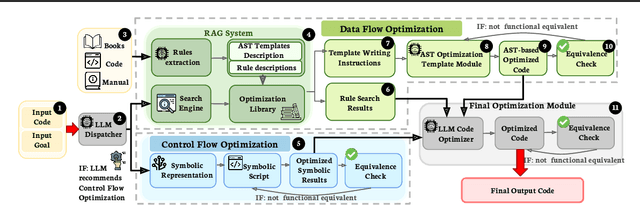

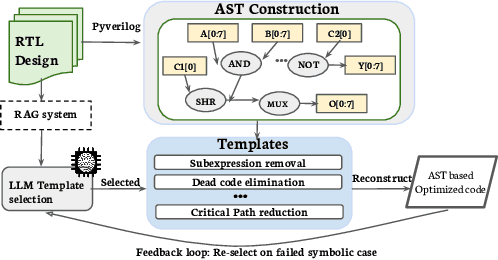
Optimizing Register Transfer Level (RTL) code is crucial for improving the power, performance, and area (PPA) of digital circuits in the early stages of synthesis. Manual rewriting, guided by synthesis feedback, can yield high-quality results but is time-consuming and error-prone. Most existing compiler-based approaches have difficulty handling complex design constraints. Large Language Model (LLM)-based methods have emerged as a promising alternative to address these challenges. However, LLM-based approaches often face difficulties in ensuring alignment between the generated code and the provided prompts. This paper presents SymRTLO, a novel neuron-symbolic RTL optimization framework that seamlessly integrates LLM-based code rewriting with symbolic reasoning techniques. Our method incorporates a retrieval-augmented generation (RAG) system of optimization rules and Abstract Syntax Tree (AST)-based templates, enabling LLM-based rewriting that maintains syntactic correctness while minimizing undesired circuit behaviors. A symbolic module is proposed for analyzing and optimizing finite state machine (FSM) logic, allowing fine-grained state merging and partial specification handling beyond the scope of pattern-based compilers. Furthermore, a fast verification pipeline, combining formal equivalence checks with test-driven validation, further reduces the complexity of verification. Experiments on the RTL-Rewriter benchmark with Synopsys Design Compiler and Yosys show that SymRTLO improves power, performance, and area (PPA) by up to 43.9%, 62.5%, and 51.1%, respectively, compared to the state-of-the-art methods.
PyOD 2: A Python Library for Outlier Detection with LLM-powered Model Selection
Dec 11, 2024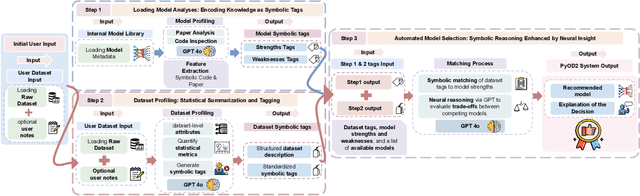
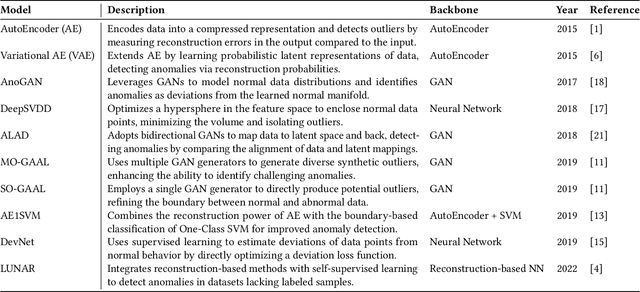

Outlier detection (OD), also known as anomaly detection, is a critical machine learning (ML) task with applications in fraud detection, network intrusion detection, clickstream analysis, recommendation systems, and social network moderation. Among open-source libraries for outlier detection, the Python Outlier Detection (PyOD) library is the most widely adopted, with over 8,500 GitHub stars, 25 million downloads, and diverse industry usage. However, PyOD currently faces three limitations: (1) insufficient coverage of modern deep learning algorithms, (2) fragmented implementations across PyTorch and TensorFlow, and (3) no automated model selection, making it hard for non-experts. To address these issues, we present PyOD Version 2 (PyOD 2), which integrates 12 state-of-the-art deep learning models into a unified PyTorch framework and introduces a large language model (LLM)-based pipeline for automated OD model selection. These improvements simplify OD workflows, provide access to 45 algorithms, and deliver robust performance on various datasets. In this paper, we demonstrate how PyOD 2 streamlines the deployment and automation of OD models and sets a new standard in both research and industry. PyOD 2 is accessible at [https://github.com/yzhao062/pyod](https://github.com/yzhao062/pyod). This study aligns with the Web Mining and Content Analysis track, addressing topics such as the robustness of Web mining methods and the quality of algorithmically-generated Web data.
RITA: A Real-time Interactive Talking Avatars Framework
Jun 18, 2024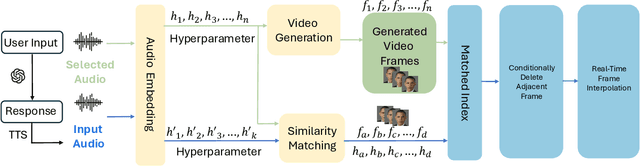


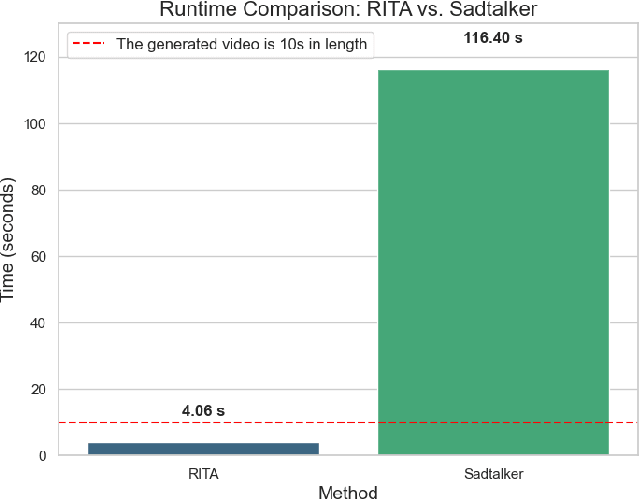
RITA presents a high-quality real-time interactive framework built upon generative models, designed with practical applications in mind. Our framework enables the transformation of user-uploaded photos into digital avatars that can engage in real-time dialogue interactions. By leveraging the latest advancements in generative modeling, we have developed a versatile platform that not only enhances the user experience through dynamic conversational avatars but also opens new avenues for applications in virtual reality, online education, and interactive gaming. This work showcases the potential of integrating computer vision and natural language processing technologies to create immersive and interactive digital personas, pushing the boundaries of how we interact with digital content.
Fuse & Calibrate: A bi-directional Vision-Language Guided Framework for Referring Image Segmentation
May 18, 2024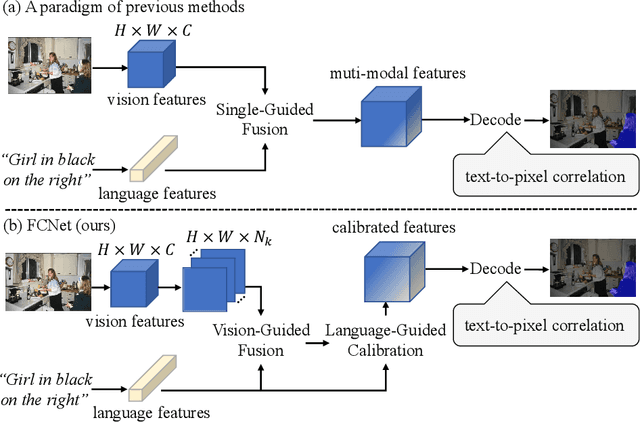
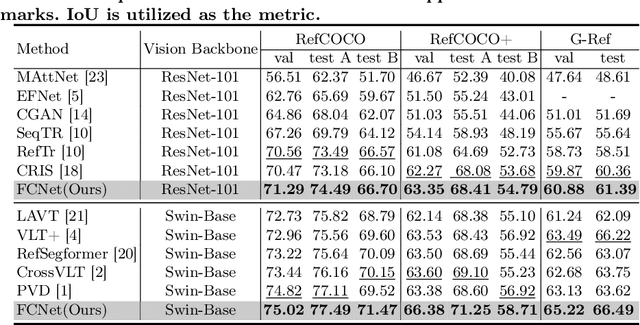
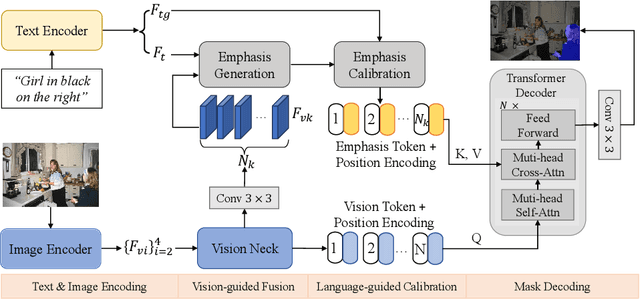
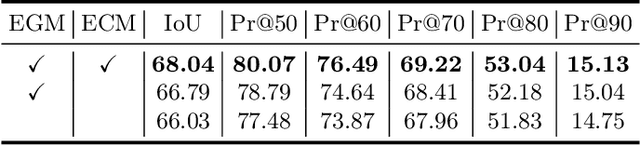
Referring Image Segmentation (RIS) aims to segment an object described in natural language from an image, with the main challenge being a text-to-pixel correlation. Previous methods typically rely on single-modality features, such as vision or language features, to guide the multi-modal fusion process. However, this approach limits the interaction between vision and language, leading to a lack of fine-grained correlation between the language description and pixel-level details during the decoding process. In this paper, we introduce FCNet, a framework that employs a bi-directional guided fusion approach where both vision and language play guiding roles. Specifically, we use a vision-guided approach to conduct initial multi-modal fusion, obtaining multi-modal features that focus on key vision information. We then propose a language-guided calibration module to further calibrate these multi-modal features, ensuring they understand the context of the input sentence. This bi-directional vision-language guided approach produces higher-quality multi-modal features sent to the decoder, facilitating adaptive propagation of fine-grained semantic information from textual features to visual features. Experiments on RefCOCO, RefCOCO+, and G-Ref datasets with various backbones consistently show our approach outperforming state-of-the-art methods.
NTIRE 2024 Challenge on Image Super-Resolution ($\times$4): Methods and Results
Apr 15, 2024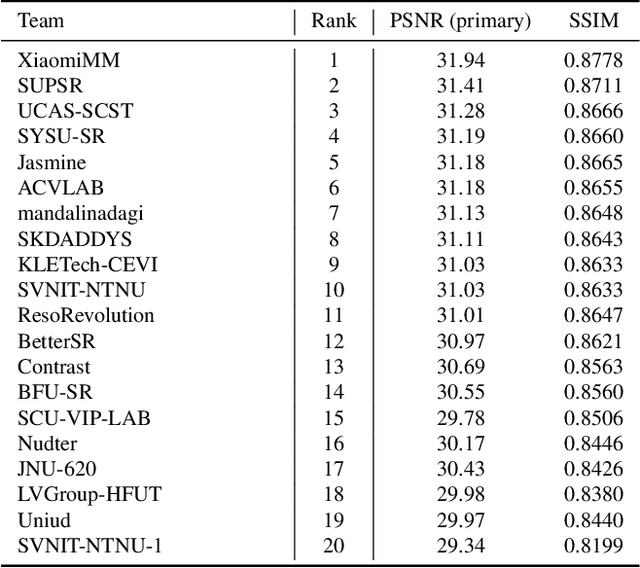
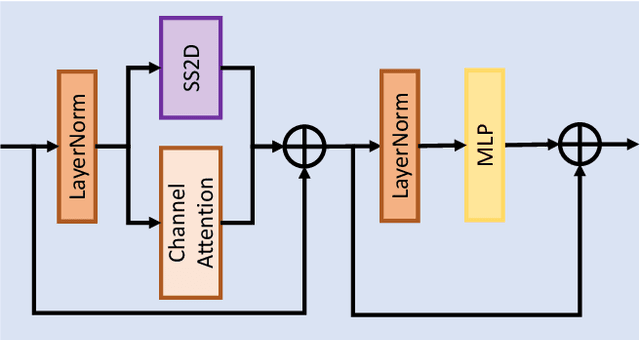
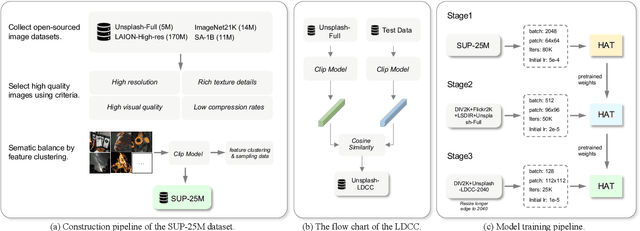
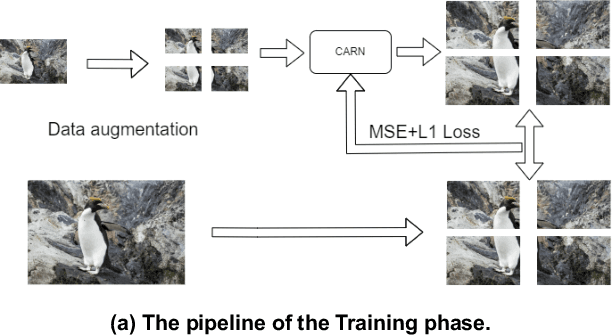
This paper reviews the NTIRE 2024 challenge on image super-resolution ($\times$4), highlighting the solutions proposed and the outcomes obtained. The challenge involves generating corresponding high-resolution (HR) images, magnified by a factor of four, from low-resolution (LR) inputs using prior information. The LR images originate from bicubic downsampling degradation. The aim of the challenge is to obtain designs/solutions with the most advanced SR performance, with no constraints on computational resources (e.g., model size and FLOPs) or training data. The track of this challenge assesses performance with the PSNR metric on the DIV2K testing dataset. The competition attracted 199 registrants, with 20 teams submitting valid entries. This collective endeavour not only pushes the boundaries of performance in single-image SR but also offers a comprehensive overview of current trends in this field.
Calibration & Reconstruction: Deep Integrated Language for Referring Image Segmentation
Apr 12, 2024Referring image segmentation aims to segment an object referred to by natural language expression from an image. The primary challenge lies in the efficient propagation of fine-grained semantic information from textual features to visual features. Many recent works utilize a Transformer to address this challenge. However, conventional transformer decoders can distort linguistic information with deeper layers, leading to suboptimal results. In this paper, we introduce CRFormer, a model that iteratively calibrates multi-modal features in the transformer decoder. We start by generating language queries using vision features, emphasizing different aspects of the input language. Then, we propose a novel Calibration Decoder (CDec) wherein the multi-modal features can iteratively calibrated by the input language features. In the Calibration Decoder, we use the output of each decoder layer and the original language features to generate new queries for continuous calibration, which gradually updates the language features. Based on CDec, we introduce a Language Reconstruction Module and a reconstruction loss. This module leverages queries from the final layer of the decoder to reconstruct the input language and compute the reconstruction loss. This can further prevent the language information from being lost or distorted. Our experiments consistently show the superior performance of our approach across RefCOCO, RefCOCO+, and G-Ref datasets compared to state-of-the-art methods.