 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-adaptive Dataset Construction for Real-World Multimodal Safety Scenarios
Sep 04, 2025



Multimodal large language models (MLLMs) are rapidly evolving, presenting increasingly complex safety challenges. However, current dataset construction methods, which are risk-oriented, fail to cover the growing complexity of real-world multimodal safety scenarios (RMS). And due to the lack of a unified evaluation metric, their overall effectiveness remains unproven. This paper introduces a novel image-oriented self-adaptive dataset construction method for RMS, which starts with images and end constructing paired text and guidance responses. Using the image-oriented method, we automatically generate an RMS dataset comprising 35k image-text pairs with guidance responses. Additionally, we introduce a standardized safety dataset evaluation metric: fine-tuning a safety judge model and evaluating its capabilities on other safety datasets.Extensive experiments on various tasks demonstrate the effectiveness of the proposed image-oriented pipeline. The results confirm the scalability and effectiveness of the image-oriented approach, offering a new perspective for the construction of real-world multimodal safety datasets.
Fuse & Calibrate: A bi-directional Vision-Language Guided Framework for Referring Image Segmentation
May 18, 2024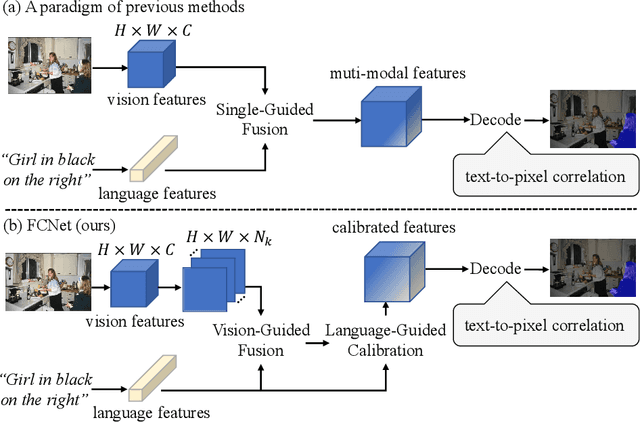
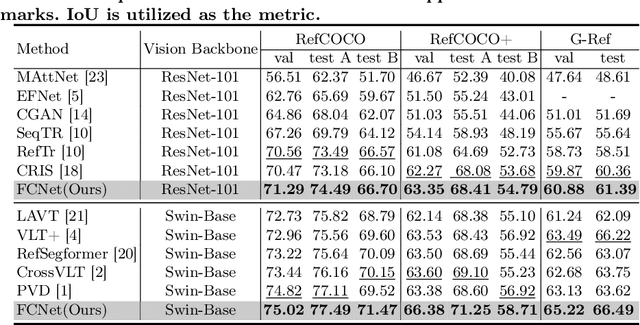
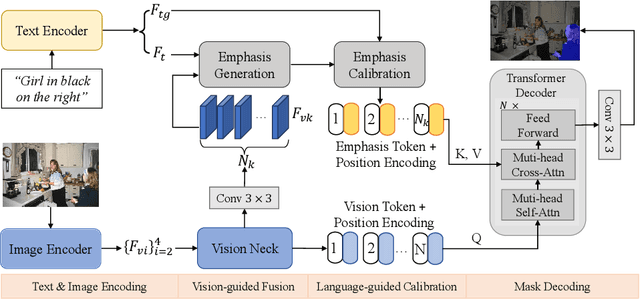
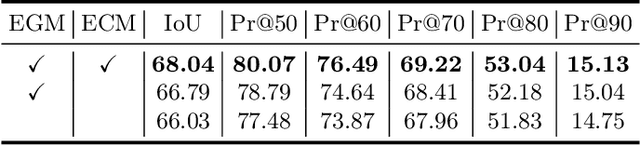
Referring Image Segmentation (RIS) aims to segment an object described in natural language from an image, with the main challenge being a text-to-pixel correlation. Previous methods typically rely on single-modality features, such as vision or language features, to guide the multi-modal fusion process. However, this approach limits the interaction between vision and language, leading to a lack of fine-grained correlation between the language description and pixel-level details during the decoding process. In this paper, we introduce FCNet, a framework that employs a bi-directional guided fusion approach where both vision and language play guiding roles. Specifically, we use a vision-guided approach to conduct initial multi-modal fusion, obtaining multi-modal features that focus on key vision information. We then propose a language-guided calibration module to further calibrate these multi-modal features, ensuring they understand the context of the input sentence. This bi-directional vision-language guided approach produces higher-quality multi-modal features sent to the decoder, facilitating adaptive propagation of fine-grained semantic information from textual features to visual features. Experiments on RefCOCO, RefCOCO+, and G-Ref datasets with various backbones consistently show our approach outperforming state-of-the-art methods.
Calibration & Reconstruction: Deep Integrated Language for Referring Image Segmentation
Apr 12, 2024Referring image segmentation aims to segment an object referred to by natural language expression from an image. The primary challenge lies in the efficient propagation of fine-grained semantic information from textual features to visual features. Many recent works utilize a Transformer to address this challenge. However, conventional transformer decoders can distort linguistic information with deeper layers, leading to suboptimal results. In this paper, we introduce CRFormer, a model that iteratively calibrates multi-modal features in the transformer decoder. We start by generating language queries using vision features, emphasizing different aspects of the input language. Then, we propose a novel Calibration Decoder (CDec) wherein the multi-modal features can iteratively calibrated by the input language features. In the Calibration Decoder, we use the output of each decoder layer and the original language features to generate new queries for continuous calibration, which gradually updates the language features. Based on CDec, we introduce a Language Reconstruction Module and a reconstruction loss. This module leverages queries from the final layer of the decoder to reconstruct the input language and compute the reconstruction loss. This can further prevent the language information from being lost or distorted. Our experiments consistently show the superior performance of our approach across RefCOCO, RefCOCO+, and G-Ref datasets compared to state-of-the-art methods.
Beyond Literal Descriptions: Understanding and Locating Open-World Objects Aligned with Human Intentions
Feb 17, 2024Visual grounding (VG) aims at locating the foreground entities that match the given natural language expression. Previous datasets and methods for classic VG task mainly rely on the prior assumption that the given expression must literally refer to the target object, which greatly impedes the practical deployment of agents in real-world scenarios. Since users usually prefer to provide the intention-based expressions for the desired object instead of covering all the details, it is necessary for the agents to interpret the intention-driven instructions. Thus, in this work, we take a step further to the intention-driven visual-language (V-L) understanding. To promote classic VG towards human intention interpretation, we propose a new intention-driven visual grounding (IVG) task and build a largest-scale IVG dataset named IntentionVG with free-form intention expressions. Considering that practical agents need to move and find specific targets among various scenarios to realize the grounding task, our IVG task and IntentionVG dataset have taken the crucial properties of both multi-scenario perception and egocentric view into consideration. Besides, various types of models are set up as the baselines to realize our IVG task. Extensive experiments on our IntentionVG dataset and baselines demonstrate the necessity and efficacy of our method for the V-L field. To foster future research in this direction, our newly built dataset and baselines will be publicly available.
EAVL: Explicitly Align Vision and Language for Referring Image Segmentation
Aug 22, 2023Referring image segmentation aims to segment an object mentioned in natural language from an image. A main challenge is language-related localization, which means locating the object with the relevant language. Previous approaches mainly focus on the fusion of vision and language features without fully addressing language-related localization. In previous approaches, fused vision-language features are directly fed into a decoder and pass through a convolution with a fixed kernel to obtain the result, which follows a similar pattern as traditional image segmentation. This approach does not explicitly align language and vision features in the segmentation stage, resulting in a suboptimal language-related localization. Different from previous methods, we propose Explicitly Align the Vision and Language for Referring Image Segmentation (EAVL). Instead of using a fixed convolution kernel, we propose an Aligner which explicitly aligns the vision and language features in the segmentation stage. Specifically, a series of unfixed convolution kernels are generated based on the input l, and then are use to explicitly align the vision and language features. To achieve this, We generate multiple queries that represent different emphases of the language expression. These queries are transformed into a series of query-based convolution kernels. Then, we utilize these kernels to do convolutions in the segmentation stage and obtain a series of segmentation masks. The final result is obtained through the aggregation of all masks. Our method can not only fuse vision and language features effectively but also exploit their potential in the segmentation stage. And most importantly, we explicitly align language features of different emphases with the image features to achieve language-related localization. Our method surpasses previous state-of-the-art methods on RefCOCO, RefCOCO+, and G-Ref by large margins.
MMNet: Multi-Mask Network for Referring Image Segmentation
May 24, 2023Referring image segmentation aims to segment an object referred to by natural language expression from an image. However, this task is challenging due to the distinct data properties between text and image, and the randomness introduced by diverse objects and unrestricted language expression. Most of previous work focus on improving cross-modal feature fusion while not fully addressing the inherent uncertainty caused by diverse objects and unrestricted language. To tackle these problems, we propose an end-to-end Multi-Mask Network for referring image segmentation(MMNet). we first combine picture and language and then employ an attention mechanism to generate multiple queries that represent different aspects of the language expression. We then utilize these queries to produce a series of corresponding segmentation masks, assigning a score to each mask that reflects its importance. The final result is obtained through the weighted sum of all masks, which greatly reduces the randomness of the language expression. Our proposed framework demonstrates superior performance compared to state-of-the-art approaches on the two most commonly used datasets, RefCOCO, RefCOCO+ and G-Ref, without the need for any post-processing. This further validates the efficacy of our proposed framework.