 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFuse & Calibrate: A bi-directional Vision-Language Guided Framework for Referring Image Segmentation
Paper and Code
May 18, 2024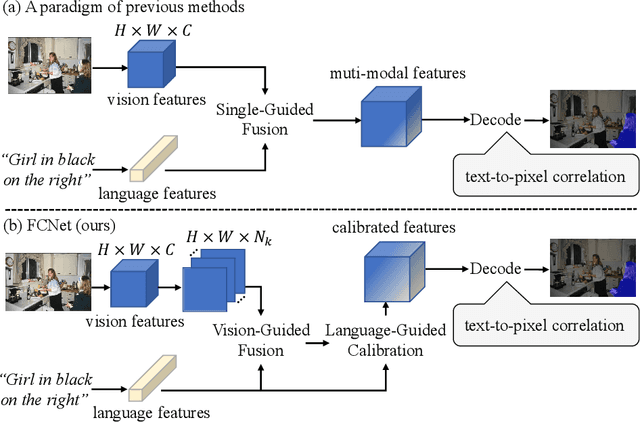
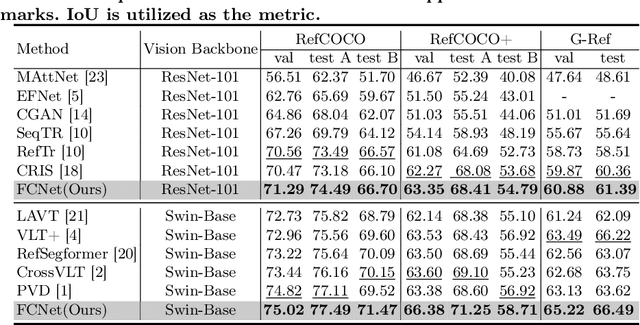
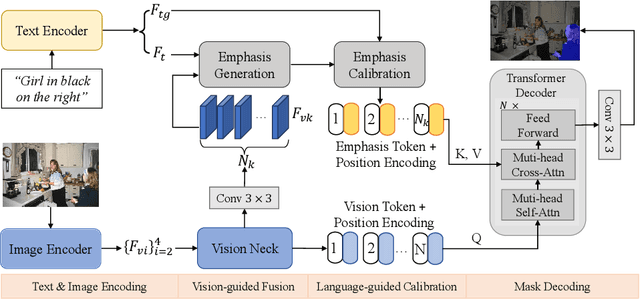
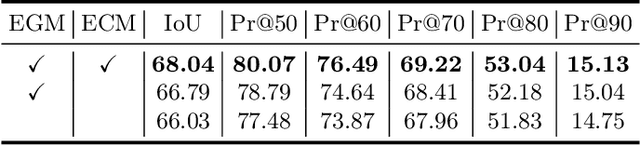
Referring Image Segmentation (RIS) aims to segment an object described in natural language from an image, with the main challenge being a text-to-pixel correlation. Previous methods typically rely on single-modality features, such as vision or language features, to guide the multi-modal fusion process. However, this approach limits the interaction between vision and language, leading to a lack of fine-grained correlation between the language description and pixel-level details during the decoding process. In this paper, we introduce FCNet, a framework that employs a bi-directional guided fusion approach where both vision and language play guiding roles. Specifically, we use a vision-guided approach to conduct initial multi-modal fusion, obtaining multi-modal features that focus on key vision information. We then propose a language-guided calibration module to further calibrate these multi-modal features, ensuring they understand the context of the input sentence. This bi-directional vision-language guided approach produces higher-quality multi-modal features sent to the decoder, facilitating adaptive propagation of fine-grained semantic information from textual features to visual features. Experiments on RefCOCO, RefCOCO+, and G-Ref datasets with various backbones consistently show our approach outperforming state-of-the-art methods.