 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVeriSpace: Spatially Grounded Action Verification for Vision-Language-Action Models
Jun 09, 2026Vision-language-action (VLA) models have shown strong promise for robotic manipulation, but their reliability at test time remains limited by one-shot action prediction, where even small action errors can cause grasp failure, collision, or incorrect task progression. A natural alternative is to equip VLA systems with test-time verification, allowing multiple candidate actions to be proposed and evaluated before execution. However, reliable action verification is challenging because it requires not only distinguishing subtle geometric differences between candidate actions, but also assessing whether an action makes meaningful progress toward the task goal. We present VeriSpace, a 3D-aware action verifier for test-time action selection in VLA systems. VeriSpace evaluates candidate actions through two key components: Dual-Path 3D-Injected Scene Encoding, which constructs a scene representation that jointly preserves visual semantics and explicit 3D geometry, and Spatially-Grounded Action Reasoning, which evaluates each action by reasoning over task-relevant spatial relations, geometric validity, and expected goal progress. Together, these components enable more reliable discrimination between subtle yet outcome-critical action candidates while remaining fully compatible with existing VLA policies. Experiments on public benchmarks and real-world robotic manipulation tasks show that VeriSpace consistently improves decision reliability over both underlying VLA policies and prior verification-based methods, yielding substantial gains in both in-distribution and out-of-distribution settings.
When Robots Do the Chores: A Benchmark and Agent for Long-Horizon Household Task Execution
May 14, 2026Long-horizon household tasks demand robust high-level planning and sustained reasoning capabilities, which are largely overlooked by existing embodied AI benchmarks that emphasize short-horizon navigation or manipulation and rely on fixed task categories. We introduce LongAct, a benchmark designed to evaluate planning-level autonomy in long-horizon household tasks specified through free-form instructions. By abstracting away embodiment-specific low-level control, LongAct isolates high-level cognitive capabilities such as instruction understanding, dependency management, memory maintenance, and adaptive planning. We further propose HoloMind, a VLM-driven agent with a DAG-based long-horizon hierarchical planner, a Multimodal Spatial Memory for persistent world modeling, an Episodic Memory for experience reuse, and a global Critic for reflective supervision. Experiments with GPT-5 and Qwen3-VL models show that HoloMind substantially improves long-horizon performance while reducing reliance on model scale. Even top models achieve only 59% goal completion and 16% full-task success, underscoring the difficulty of LongAct and the need for stronger long-horizon planning in embodied agents.
Thinking in Streaming Video
Mar 13, 2026Real-time understanding of continuous video streams is essential for interactive assistants and multimodal agents operating in dynamic environments. However, most existing video reasoning approaches follow a batch paradigm that defers reasoning until the full video context is observed, resulting in high latency and growing computational cost that are incompatible with streaming scenarios. In this paper, we introduce ThinkStream, a framework for streaming video reasoning based on a Watch--Think--Speak paradigm that enables models to incrementally update their understanding as new video observations arrive. At each step, the model performs a short reasoning update and decides whether sufficient evidence has accumulated to produce a response. To support long-horizon streaming, we propose Reasoning-Compressed Streaming Memory (RCSM), which treats intermediate reasoning traces as compact semantic memory that replaces outdated visual tokens while preserving essential context. We further train the model using a Streaming Reinforcement Learning with Verifiable Rewards scheme that aligns incremental reasoning and response timing with the requirements of streaming interaction. Experiments on multiple streaming video benchmarks show that ThinkStream significantly outperforms existing online video models while maintaining low latency and memory usage. Code, models and data will be released at https://github.com/johncaged/ThinkStream
UrbanNav: Learning Language-Guided Urban Navigation from Web-Scale Human Trajectories
Dec 10, 2025
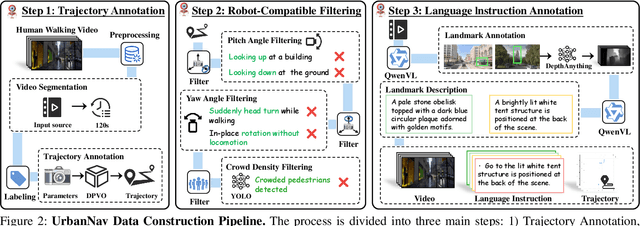
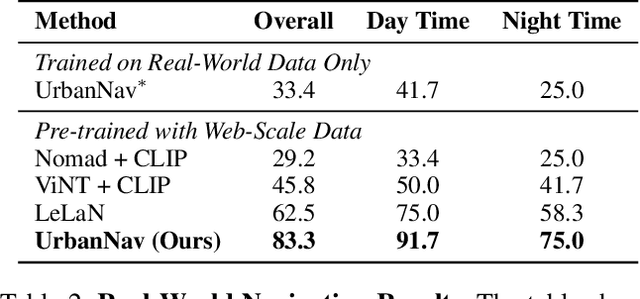
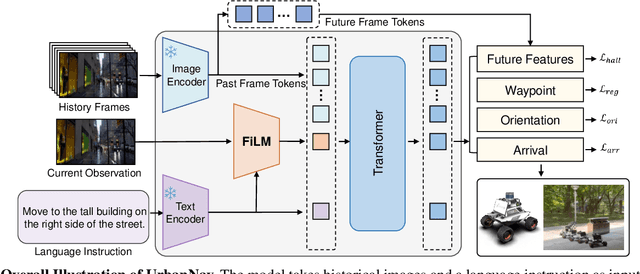
Navigating complex urban environments using natural language instructions poses significant challenges for embodied agents, including noisy language instructions, ambiguous spatial references, diverse landmarks, and dynamic street scenes. Current visual navigation methods are typically limited to simulated or off-street environments, and often rely on precise goal formats, such as specific coordinates or images. This limits their effectiveness for autonomous agents like last-mile delivery robots navigating unfamiliar cities. To address these limitations, we introduce UrbanNav, a scalable framework that trains embodied agents to follow free-form language instructions in diverse urban settings. Leveraging web-scale city walking videos, we develop an scalable annotation pipeline that aligns human navigation trajectories with language instructions grounded in real-world landmarks. UrbanNav encompasses over 1,500 hours of navigation data and 3 million instruction-trajectory-landmark triplets, capturing a wide range of urban scenarios. Our model learns robust navigation policies to tackle complex urban scenarios, demonstrating superior spatial reasoning, robustness to noisy instructions, and generalization to unseen urban settings. Experimental results show that UrbanNav significantly outperforms existing methods, highlighting the potential of large-scale web video data to enable language-guided, real-world urban navigation for embodied agents.
Towards Unified Referring Expression Segmentation Across Omni-Level Visual Target Granularities
Apr 02, 2025Referring expression segmentation (RES) aims at segmenting the entities' masks that match the descriptive language expression. While traditional RES methods primarily address object-level grounding, real-world scenarios demand a more versatile framework that can handle multiple levels of target granularity, such as multi-object, single object or part-level references. This introduces great challenges due to the diverse and nuanced ways users describe targets. However, existing datasets and models mainly focus on designing grounding specialists for object-level target localization, lacking the necessary data resources and unified frameworks for the more practical multi-grained RES. In this paper, we take a step further towards visual granularity unified RES task. To overcome the limitation of data scarcity, we introduce a new multi-granularity referring expression segmentation (MRES) task, alongside the RefCOCOm benchmark, which includes part-level annotations for advancing finer-grained visual understanding. In addition, we create MRES-32M, the largest visual grounding dataset, comprising over 32.2M masks and captions across 1M images, specifically designed for part-level vision-language grounding. To tackle the challenges of multi-granularity RES, we propose UniRES++, a unified multimodal large language model that integrates object-level and part-level RES tasks. UniRES++ incorporates targeted designs for fine-grained visual feature exploration. With the joint model architecture and parameters, UniRES++ achieves state-of-the-art performance across multiple benchmarks, including RefCOCOm for MRES, gRefCOCO for generalized RES, and RefCOCO, RefCOCO+, RefCOCOg for classic RES. To foster future research into multi-grained visual grounding, our RefCOCOm benchmark, MRES-32M dataset and model UniRES++ will be publicly available at https://github.com/Rubics-Xuan/MRES.
MiniVLN: Efficient Vision-and-Language Navigation by Progressive Knowledge Distillation
Sep 27, 2024
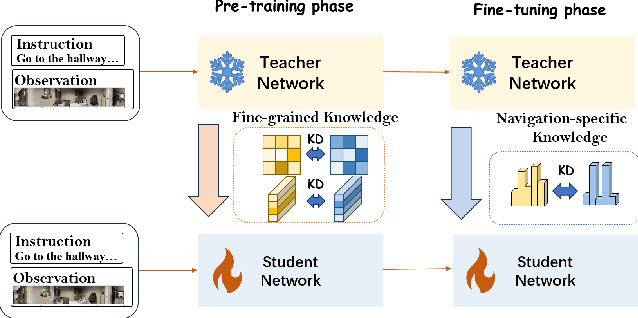

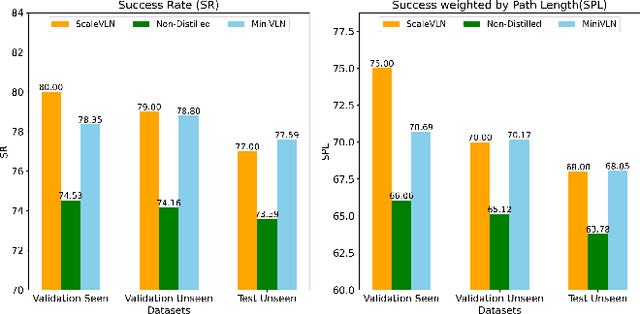
In recent years, Embodied Artificial Intelligence (Embodied AI) has advanced rapidly, yet the increasing size of models conflicts with the limited computational capabilities of Embodied AI platforms. To address this challenge, we aim to achieve both high model performance and practical deployability. Specifically, we focus on Vision-and-Language Navigation (VLN), a core task in Embodied AI. This paper introduces a two-stage knowledge distillation framework, producing a student model, MiniVLN, and showcasing the significant potential of distillation techniques in developing lightweight models. The proposed method aims to capture fine-grained knowledge during the pretraining phase and navigation-specific knowledge during the fine-tuning phase. Our findings indicate that the two-stage distillation approach is more effective in narrowing the performance gap between the teacher model and the student model compared to single-stage distillation. On the public R2R and REVERIE benchmarks, MiniVLN achieves performance on par with the teacher model while having only about 12% of the teacher model's parameter count.
LSVOS Challenge Report: Large-scale Complex and Long Video Object Segmentation
Sep 09, 2024



Despite the promising performance of current video segmentation models on existing benchmarks, these models still struggle with complex scenes. In this paper, we introduce the 6th Large-scale Video Object Segmentation (LSVOS) challenge in conjunction with ECCV 2024 workshop. This year's challenge includes two tasks: Video Object Segmentation (VOS) and Referring Video Object Segmentation (RVOS). In this year, we replace the classic YouTube-VOS and YouTube-RVOS benchmark with latest datasets MOSE, LVOS, and MeViS to assess VOS under more challenging complex environments. This year's challenge attracted 129 registered teams from more than 20 institutes across over 8 countries. This report include the challenge and dataset introduction, and the methods used by top 7 teams in two tracks. More details can be found in our homepage https://lsvos.github.io/.
The Instance-centric Transformer for the RVOS Track of LSVOS Challenge: 3rd Place Solution
Aug 20, 2024Referring Video Object Segmentation is an emerging multi-modal task that aims to segment objects in the video given a natural language expression. In this work, we build two instance-centric models and fuse predicted results from frame-level and instance-level. First, we introduce instance mask into the DETR-based model for query initialization to achieve temporal enhancement and employ SAM for spatial refinement. Secondly, we build an instance retrieval model conducting binary instance mask classification whether the instance is referred. Finally, we fuse predicted results and our method achieved a score of 52.67 J&F in the validation phase and 60.36 J&F in the test phase, securing the final ranking of 3rd place in the 6-th LSVOS Challenge RVOS Track.
PVUW 2024 Challenge on Complex Video Understanding: Methods and Results
Jun 24, 2024



Pixel-level Video Understanding in the Wild Challenge (PVUW) focus on complex video understanding. In this CVPR 2024 workshop, we add two new tracks, Complex Video Object Segmentation Track based on MOSE dataset and Motion Expression guided Video Segmentation track based on MeViS dataset. In the two new tracks, we provide additional videos and annotations that feature challenging elements, such as the disappearance and reappearance of objects, inconspicuous small objects, heavy occlusions, and crowded environments in MOSE. Moreover, we provide a new motion expression guided video segmentation dataset MeViS to study the natural language-guided video understanding in complex environments. These new videos, sentences, and annotations enable us to foster the development of a more comprehensive and robust pixel-level understanding of video scenes in complex environments and realistic scenarios. The MOSE challenge had 140 registered teams in total, 65 teams participated the validation phase and 12 teams made valid submissions in the final challenge phase. The MeViS challenge had 225 registered teams in total, 50 teams participated the validation phase and 5 teams made valid submissions in the final challenge phase.
2nd Place Solution for MeViS Track in CVPR 2024 PVUW Workshop: Motion Expression guided Video Segmentation
Jun 20, 2024
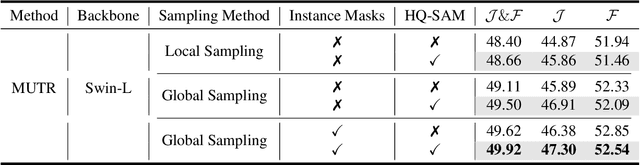
Motion Expression guided Video Segmentation is a challenging task that aims at segmenting objects in the video based on natural language expressions with motion descriptions. Unlike the previous referring video object segmentation (RVOS), this task focuses more on the motion in video content for language-guided video object segmentation, requiring an enhanced ability to model longer temporal, motion-oriented vision-language data. In this report, based on the RVOS methods, we successfully introduce mask information obtained from the video instance segmentation model as preliminary information for temporal enhancement and employ SAM for spatial refinement. Finally, our method achieved a score of 49.92 J &F in the validation phase and 54.20 J &F in the test phase, securing the final ranking of 2nd in the MeViS Track at the CVPR 2024 PVUW Challenge.