 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNemotron 3 Ultra: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Jun 12, 2026We introduce Nemotron 3 Ultra, a 550 billion total and 55 billion active parameter Mixture-of-Experts Hybrid Mamba-Attention language model. We pre-trained Nemotron 3 Ultra on 20 trillion text tokens, then extended the context length to 1M tokens, and post-trained using Supervised Fine Tuning (SFT), Reinforcement Learning (RL), and Multi-teacher On-Policy Distillation (MOPD). Nemotron 3 Ultra is our most capable model yet, employing multiple key technologies - LatentMoE, Multi Token Prediction (MTP), NVFP4 pre-training, multi-environment RLVR, MOPD, and reasoning budget control. Nemotron 3 Ultra achieves up to ~6x higher inference throughput as compared to state-of-the-art publicly available LLMs while attaining on-par accuracy. The state-of-the-art accuracy, high inference throughput, and 1M token context length make Nemotron 3 Ultra ideal for long-running autonomous agentic tasks. We open-source the base, post-trained, and quantized checkpoints, along with the training data and recipe on HuggingFace.
Meta-Aligner: Bidirectional Preference-Policy Optimization for Multi-Objective LLMs Alignment
Apr 27, 2026Multi-Objective Alignment aims to align Large Language Models (LLMs) with diverse and often conflicting human values by optimizing multiple objectives simultaneously. Existing methods predominantly rely on static preference weight construction strategies. However, rigidly aligning to fixed targets discards valuable intermediate information, as training responses inherently embody valid preference trade-offs even when deviating from the target. To address this limitation, we propose Meal, i.e., MEta ALigner, a bi-level meta-learning framework enabling bidirectional optimization between preferences and policy responses, generating instructive dynamic preferences for steadier training. Specifically, we introduce a preference-weight-net as a meta-learner to generate adaptive preference weights based on input prompts and update the preference weights as learnable parameters, while the LLM policy acts as a base-learner optimizing response generation conditioned on these preferences with rejection sampling strategy. Extensive empirical results demonstrate that our method achieves superior performance on several multi-objective benchmarks, validating the effectiveness of the dynamic bidirectional preference-policy optimization framework.
VRM: Teaching Reward Models to Understand Authentic Human Preferences
Mar 05, 2026Large Language Models (LLMs) have achieved remarkable success across diverse natural language tasks, yet the reward models employed for aligning LLMs often encounter challenges of reward hacking, where the approaches predominantly rely on directly mapping prompt-response pairs to scalar scores, which may inadvertently capture spurious correlations rather than authentic human preferences. In contrast, human evaluation employs a sophisticated process that initially weighs the relative importance of multiple high-dimensional objectives according to the prompt context, subsequently evaluating response quality through low-dimensional semantic features such as logical coherence and contextual appropriateness. Motivated by this consideration, we propose VRM, i.e., Variational Reward Modeling, a novel framework that explicitly models the evaluation process of human preference judgments by incorporating both high-dimensional objective weights and low-dimensional semantic features as latent variables, which are inferred through variational inference techniques. Additionally, we provide a theoretical analysis showing that VRM can achieve a tighter generalization error bound compared to the traditional reward model. Extensive experiments on benchmark datasets demonstrate that VRM significantly outperforms existing methods in capturing authentic human preferences.
Semantic Bridging Domains: Pseudo-Source as Test-Time Connector
Mar 04, 2026Distribution shifts between training and testing data are a critical bottleneck limiting the practical utility of models, especially in real-world test-time scenarios. To adapt models when the source domain is unknown and the target domain is unlabeled, previous works constructed pseudo-source domains via data generation and translation, then aligned the target domain with them. However, significant discrepancies exist between the pseudo-source and the original source domain, leading to potential divergence when correcting the target directly. From this perspective, we propose a Stepwise Semantic Alignment (SSA) method, viewing the pseudo-source as a semantic bridge connecting the source and target, rather than a direct substitute for the source. Specifically, we leverage easily accessible universal semantics to rectify the semantic features of the pseudo-source, and then align the target domain using the corrected pseudo-source semantics. Additionally, we introduce a Hierarchical Feature Aggregation (HFA) module and a Confidence-Aware Complementary Learning (CACL) strategy to enhance the semantic quality of the SSA process in the absence of source and ground truth of target domains. We evaluated our approach on tasks like semantic segmentation and image classification, achieving a 5.2% performance boost on GTA2Cityscapes over the state-of-the-art.
LoGoSeg: Integrating Local and Global Features for Open-Vocabulary Semantic Segmentation
Feb 05, 2026Open-vocabulary semantic segmentation (OVSS) extends traditional closed-set segmentation by enabling pixel-wise annotation for both seen and unseen categories using arbitrary textual descriptions. While existing methods leverage vision-language models (VLMs) like CLIP, their reliance on image-level pretraining often results in imprecise spatial alignment, leading to mismatched segmentations in ambiguous or cluttered scenes. However, most existing approaches lack strong object priors and region-level constraints, which can lead to object hallucination or missed detections, further degrading performance. To address these challenges, we propose LoGoSeg, an efficient single-stage framework that integrates three key innovations: (i) an object existence prior that dynamically weights relevant categories through global image-text similarity, effectively reducing hallucinations; (ii) a region-aware alignment module that establishes precise region-level visual-textual correspondences; and (iii) a dual-stream fusion mechanism that optimally combines local structural information with global semantic context. Unlike prior works, LoGoSeg eliminates the need for external mask proposals, additional backbones, or extra datasets, ensuring efficiency. Extensive experiments on six benchmarks (A-847, PC-459, A-150, PC-59, PAS-20, and PAS-20b) demonstrate its competitive performance and strong generalization in open-vocabulary settings.
Towards Understanding Feature Learning in Parameter Transfer
Sep 26, 2025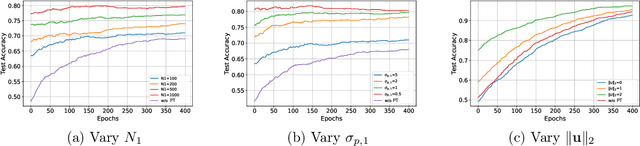
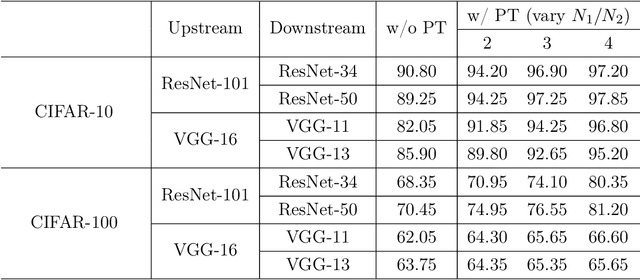
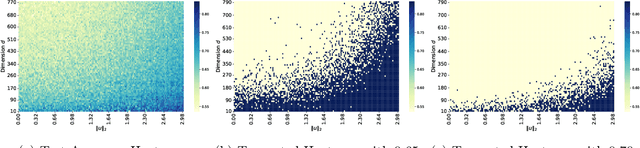
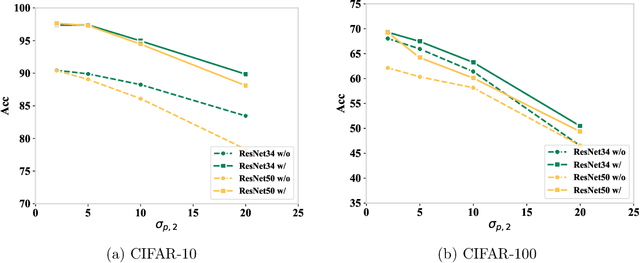
Parameter transfer is a central paradigm in transfer learning, enabling knowledge reuse across tasks and domains by sharing model parameters between upstream and downstream models. However, when only a subset of parameters from the upstream model is transferred to the downstream model, there remains a lack of theoretical understanding of the conditions under which such partial parameter reuse is beneficial and of the factors that govern its effectiveness. To address this gap, we analyze a setting in which both the upstream and downstream models are ReLU convolutional neural networks (CNNs). Within this theoretical framework, we characterize how the inherited parameters act as carriers of universal knowledge and identify key factors that amplify their beneficial impact on the target task. Furthermore, our analysis provides insight into why, in certain cases, transferring parameters can lead to lower test accuracy on the target task than training a new model from scratch. Numerical experiments and real-world data experiments are conducted to empirically validate our theoretical findings.
Enriching Knowledge Distillation with Intra-Class Contrastive Learning
Sep 26, 2025Since the advent of knowledge distillation, much research has focused on how the soft labels generated by the teacher model can be utilized effectively. Existing studies points out that the implicit knowledge within soft labels originates from the multi-view structure present in the data. Feature variations within samples of the same class allow the student model to generalize better by learning diverse representations. However, in existing distillation methods, teacher models predominantly adhere to ground-truth labels as targets, without considering the diverse representations within the same class. Therefore, we propose incorporating an intra-class contrastive loss during teacher training to enrich the intra-class information contained in soft labels. In practice, we find that intra-class loss causes instability in training and slows convergence. To mitigate these issues, margin loss is integrated into intra-class contrastive learning to improve the training stability and convergence speed. Simultaneously, we theoretically analyze the impact of this loss on the intra-class distances and inter-class distances. It has been proved that the intra-class contrastive loss can enrich the intra-class diversity. Experimental results demonstrate the effectiveness of the proposed method.
HyP-ASO: A Hybrid Policy-based Adaptive Search Optimization Framework for Large-Scale Integer Linear Programs
Sep 19, 2025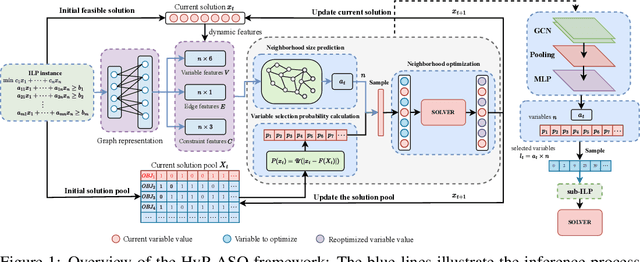

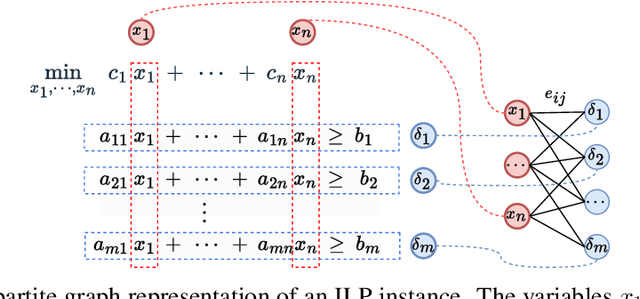
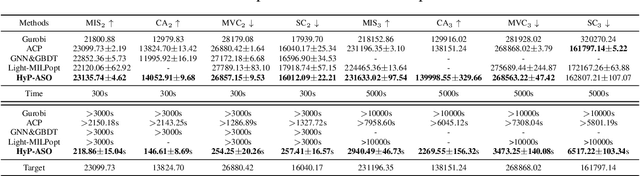
Directly solving large-scale Integer Linear Programs (ILPs) using traditional solvers is slow due to their NP-hard nature. While recent frameworks based on Large Neighborhood Search (LNS) can accelerate the solving process, their performance is often constrained by the difficulty in generating sufficiently effective neighborhoods. To address this challenge, we propose HyP-ASO, a hybrid policy-based adaptive search optimization framework that combines a customized formula with deep Reinforcement Learning (RL). The formula leverages feasible solutions to calculate the selection probabilities for each variable in the neighborhood generation process, and the RL policy network predicts the neighborhood size. Extensive experiments demonstrate that HyP-ASO significantly outperforms existing LNS-based approaches for large-scale ILPs. Additional experiments show it is lightweight and highly scalable, making it well-suited for solving large-scale ILPs.
Nemotron-H: A Family of Accurate and Efficient Hybrid Mamba-Transformer Models
Apr 10, 2025



As inference-time scaling becomes critical for enhanced reasoning capabilities, it is increasingly becoming important to build models that are efficient to infer. We introduce Nemotron-H, a family of 8B and 56B/47B hybrid Mamba-Transformer models designed to reduce inference cost for a given accuracy level. To achieve this goal, we replace the majority of self-attention layers in the common Transformer model architecture with Mamba layers that perform constant computation and require constant memory per generated token. We show that Nemotron-H models offer either better or on-par accuracy compared to other similarly-sized state-of-the-art open-sourced Transformer models (e.g., Qwen-2.5-7B/72B and Llama-3.1-8B/70B), while being up to 3$\times$ faster at inference. To further increase inference speed and reduce the memory required at inference time, we created Nemotron-H-47B-Base from the 56B model using a new compression via pruning and distillation technique called MiniPuzzle. Nemotron-H-47B-Base achieves similar accuracy to the 56B model, but is 20% faster to infer. In addition, we introduce an FP8-based training recipe and show that it can achieve on par results with BF16-based training. This recipe is used to train the 56B model. All Nemotron-H models will be released, with support in Hugging Face, NeMo, and Megatron-LM.
CSF: Fixed-outline Floorplanning Based on the Conjugate Subgradient Algorithm Assisted by Q-Learning
Apr 04, 2025To perform the fixed-outline floorplanning problem efficiently, we propose to solve the original nonsmooth analytic optimization model via the conjugate subgradient algorithm (CSA), which is further accelerated by adaptively regulating the step size with the assistance of Q-learning. The objective for global floorplanning is a weighted sum of the half-perimeter wirelength, the overlapping area and the out-of-bound width, and the legalization is implemented by optimizing the weighted sum of the overlapping area and the out-of-bound width. Meanwhile, we also propose two improved variants for the legalizaiton algorithm based on constraint graphs (CGs). Experimental results demonstrate that the CSA assisted by Q-learning (CSAQ) can address both global floorplanning and legalization efficiently, and the two stages jointly contribute to competitive results on the optimization of wirelength. Meanwhile, the improved CG-based legalization methods also outperforms the original one in terms of runtime and success rate.