 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeedance 1.5 pro: A Native Audio-Visual Joint Generation Foundation Model
Dec 23, 2025Recent strides in video generation have paved the way for unified audio-visual generation. In this work, we present Seedance 1.5 pro, a foundational model engineered specifically for native, joint audio-video generation. Leveraging a dual-branch Diffusion Transformer architecture, the model integrates a cross-modal joint module with a specialized multi-stage data pipeline, achieving exceptional audio-visual synchronization and superior generation quality. To ensure practical utility, we implement meticulous post-training optimizations, including Supervised Fine-Tuning (SFT) on high-quality datasets and Reinforcement Learning from Human Feedback (RLHF) with multi-dimensional reward models. Furthermore, we introduce an acceleration framework that boosts inference speed by over 10X. Seedance 1.5 pro distinguishes itself through precise multilingual and dialect lip-syncing, dynamic cinematic camera control, and enhanced narrative coherence, positioning it as a robust engine for professional-grade content creation. Seedance 1.5 pro is now accessible on Volcano Engine at https://console.volcengine.com/ark/region:ark+cn-beijing/experience/vision?type=GenVideo.
How to Understand Named Entities: Using Common Sense for News Captioning
Mar 11, 2024



News captioning aims to describe an image with its news article body as input. It greatly relies on a set of detected named entities, including real-world people, organizations, and places. This paper exploits commonsense knowledge to understand named entities for news captioning. By ``understand'', we mean correlating the news content with common sense in the wild, which helps an agent to 1) distinguish semantically similar named entities and 2) describe named entities using words outside of training corpora. Our approach consists of three modules: (a) Filter Module aims to clarify the common sense concerning a named entity from two aspects: what does it mean? and what is it related to?, which divide the common sense into explanatory knowledge and relevant knowledge, respectively. (b) Distinguish Module aggregates explanatory knowledge from node-degree, dependency, and distinguish three aspects to distinguish semantically similar named entities. (c) Enrich Module attaches relevant knowledge to named entities to enrich the entity description by commonsense information (e.g., identity and social position). Finally, the probability distributions from both modules are integrated to generate the news captions. Extensive experiments on two challenging datasets (i.e., GoodNews and NYTimes) demonstrate the superiority of our method. Ablation studies and visualization further validate its effectiveness in understanding named entities.
MicroCinema: A Divide-and-Conquer Approach for Text-to-Video Generation
Nov 30, 2023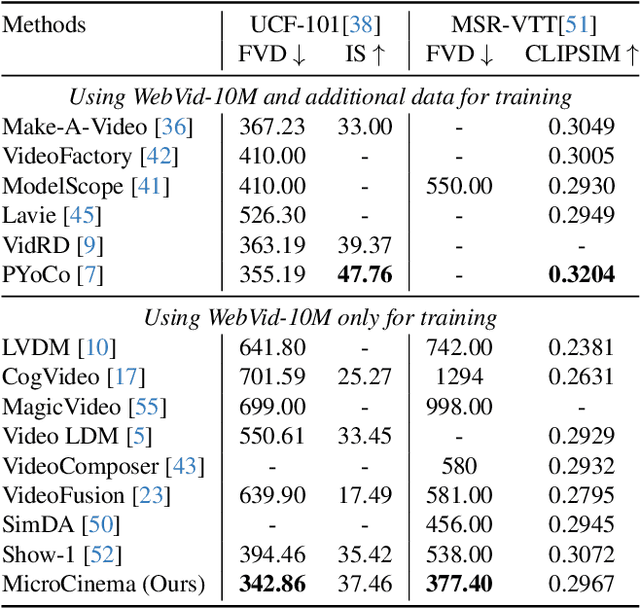
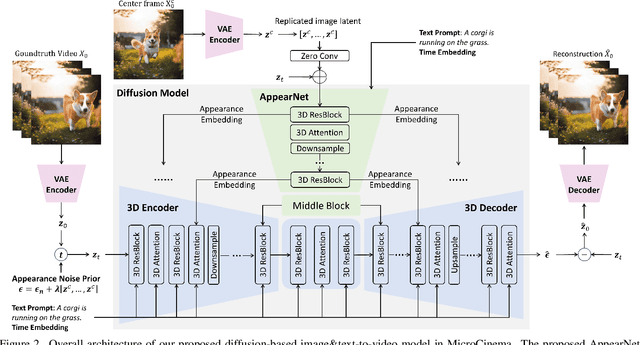
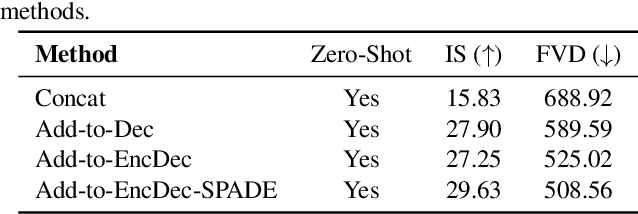
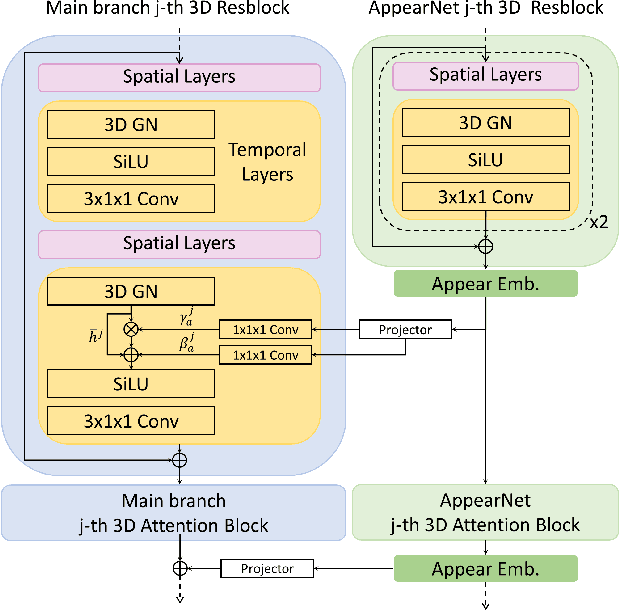
We present MicroCinema, a straightforward yet effective framework for high-quality and coherent text-to-video generation. Unlike existing approaches that align text prompts with video directly, MicroCinema introduces a Divide-and-Conquer strategy which divides the text-to-video into a two-stage process: text-to-image generation and image\&text-to-video generation. This strategy offers two significant advantages. a) It allows us to take full advantage of the recent advances in text-to-image models, such as Stable Diffusion, Midjourney, and DALLE, to generate photorealistic and highly detailed images. b) Leveraging the generated image, the model can allocate less focus to fine-grained appearance details, prioritizing the efficient learning of motion dynamics. To implement this strategy effectively, we introduce two core designs. First, we propose the Appearance Injection Network, enhancing the preservation of the appearance of the given image. Second, we introduce the Appearance Noise Prior, a novel mechanism aimed at maintaining the capabilities of pre-trained 2D diffusion models. These design elements empower MicroCinema to generate high-quality videos with precise motion, guided by the provided text prompts. Extensive experiments demonstrate the superiority of the proposed framework. Concretely, MicroCinema achieves SOTA zero-shot FVD of 342.86 on UCF-101 and 377.40 on MSR-VTT. See https://wangyanhui666.github.io/MicroCinema.github.io/ for video samples.
ART$\boldsymbol{\cdot}$V: Auto-Regressive Text-to-Video Generation with Diffusion Models
Nov 30, 2023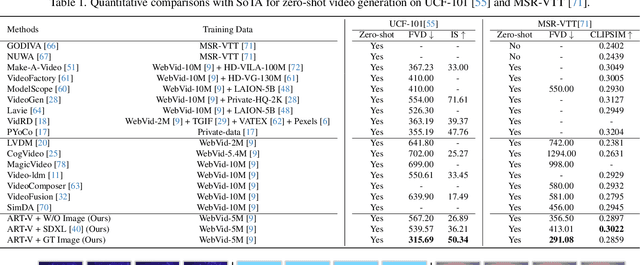
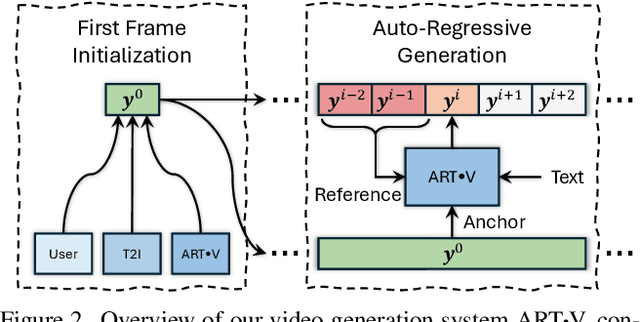
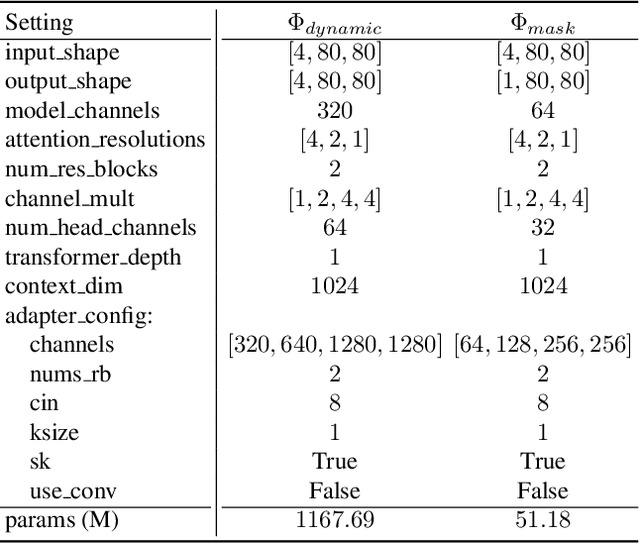
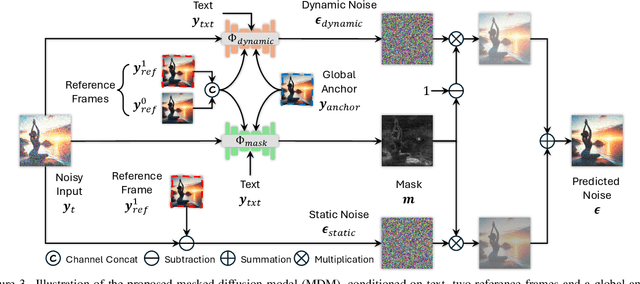
We present ART$\boldsymbol{\cdot}$V, an efficient framework for auto-regressive video generation with diffusion models. Unlike existing methods that generate entire videos in one-shot, ART$\boldsymbol{\cdot}$V generates a single frame at a time, conditioned on the previous ones. The framework offers three distinct advantages. First, it only learns simple continual motions between adjacent frames, therefore avoiding modeling complex long-range motions that require huge training data. Second, it preserves the high-fidelity generation ability of the pre-trained image diffusion models by making only minimal network modifications. Third, it can generate arbitrarily long videos conditioned on a variety of prompts such as text, image or their combinations, making it highly versatile and flexible. To combat the common drifting issue in AR models, we propose masked diffusion model which implicitly learns which information can be drawn from reference images rather than network predictions, in order to reduce the risk of generating inconsistent appearances that cause drifting. Moreover, we further enhance generation coherence by conditioning it on the initial frame, which typically contains minimal noise. This is particularly useful for long video generation. When trained for only two weeks on four GPUs, ART$\boldsymbol{\cdot}$V already can generate videos with natural motions, rich details and a high level of aesthetic quality. Besides, it enables various appealing applications, e.g., composing a long video from multiple text prompts.
Panacea: Panoramic and Controllable Video Generation for Autonomous Driving
Nov 28, 2023



The field of autonomous driving increasingly demands high-quality annotated training data. In this paper, we propose Panacea, an innovative approach to generate panoramic and controllable videos in driving scenarios, capable of yielding an unlimited numbers of diverse, annotated samples pivotal for autonomous driving advancements. Panacea addresses two critical challenges: 'Consistency' and 'Controllability.' Consistency ensures temporal and cross-view coherence, while Controllability ensures the alignment of generated content with corresponding annotations. Our approach integrates a novel 4D attention and a two-stage generation pipeline to maintain coherence, supplemented by the ControlNet framework for meticulous control by the Bird's-Eye-View (BEV) layouts. Extensive qualitative and quantitative evaluations of Panacea on the nuScenes dataset prove its effectiveness in generating high-quality multi-view driving-scene videos. This work notably propels the field of autonomous driving by effectively augmenting the training dataset used for advanced BEV perception techniques.
CCEdit: Creative and Controllable Video Editing via Diffusion Models
Sep 28, 2023



In this work, we present CCEdit, a versatile framework designed to address the challenges of creative and controllable video editing. CCEdit accommodates a wide spectrum of user editing requirements and enables enhanced creative control through an innovative approach that decouples video structure and appearance. We leverage the foundational ControlNet architecture to preserve structural integrity, while seamlessly integrating adaptable temporal modules compatible with state-of-the-art personalization techniques for text-to-image generation, such as DreamBooth and LoRA.Furthermore, we introduce reference-conditioned video editing, empowering users to exercise precise creative control over video editing through the more manageable process of editing key frames. Our extensive experimental evaluations confirm the exceptional functionality and editing capabilities of the proposed CCEdit framework. Demo video is available at https://www.youtube.com/watch?v=UQw4jq-igN4.