 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRE-TRAC: REcursive TRAjectory Compression for Deep Search Agents
Feb 02, 2026LLM-based deep research agents are largely built on the ReAct framework. This linear design makes it difficult to revisit earlier states, branch into alternative search directions, or maintain global awareness under long contexts, often leading to local optima, redundant exploration, and inefficient search. We propose Re-TRAC, an agentic framework that performs cross-trajectory exploration by generating a structured state representation after each trajectory to summarize evidence, uncertainties, failures, and future plans, and conditioning subsequent trajectories on this state representation. This enables iterative reflection and globally informed planning, reframing research as a progressive process. Empirical results show that Re-TRAC consistently outperforms ReAct by 15-20% on BrowseComp with frontier LLMs. For smaller models, we introduce Re-TRAC-aware supervised fine-tuning, achieving state-of-the-art performance at comparable scales. Notably, Re-TRAC shows a monotonic reduction in tool calls and token usage across rounds, indicating progressively targeted exploration driven by cross-trajectory reflection rather than redundant search.
SimRPD: Optimizing Recruitment Proactive Dialogue Agents through Simulator-Based Data Evaluation and Selection
Jan 08, 2026Task-oriented proactive dialogue agents play a pivotal role in recruitment, particularly for steering conversations towards specific business outcomes, such as acquiring social-media contacts for private-channel conversion. Although supervised fine-tuning and reinforcement learning have proven effective for training such agents, their performance is heavily constrained by the scarcity of high-quality, goal-oriented domain-specific training data. To address this challenge, we propose SimRPD, a three-stage framework for training recruitment proactive dialogue agents. First, we develop a high-fidelity user simulator to synthesize large-scale conversational data through multi-turn online dialogue. Then we introduce a multi-dimensional evaluation framework based on Chain-of-Intention (CoI) to comprehensively assess the simulator and effectively select high-quality data, incorporating both global-level and instance-level metrics. Finally, we train the recruitment proactive dialogue agent on the selected dataset. Experiments in a real-world recruitment scenario demonstrate that SimRPD outperforms existing simulator-based data selection strategies, highlighting its practical value for industrial deployment and its potential applicability to other business-oriented dialogue scenarios.
FlashPortrait: 6x Faster Infinite Portrait Animation with Adaptive Latent Prediction
Dec 18, 2025Current diffusion-based acceleration methods for long-portrait animation struggle to ensure identity (ID) consistency. This paper presents FlashPortrait, an end-to-end video diffusion transformer capable of synthesizing ID-preserving, infinite-length videos while achieving up to 6x acceleration in inference speed. In particular, FlashPortrait begins by computing the identity-agnostic facial expression features with an off-the-shelf extractor. It then introduces a Normalized Facial Expression Block to align facial features with diffusion latents by normalizing them with their respective means and variances, thereby improving identity stability in facial modeling. During inference, FlashPortrait adopts a dynamic sliding-window scheme with weighted blending in overlapping areas, ensuring smooth transitions and ID consistency in long animations. In each context window, based on the latent variation rate at particular timesteps and the derivative magnitude ratio among diffusion layers, FlashPortrait utilizes higher-order latent derivatives at the current timestep to directly predict latents at future timesteps, thereby skipping several denoising steps and achieving 6x speed acceleration. Experiments on benchmarks show the effectiveness of FlashPortrait both qualitatively and quantitatively.
StableAvatar: Infinite-Length Audio-Driven Avatar Video Generation
Aug 11, 2025Current diffusion models for audio-driven avatar video generation struggle to synthesize long videos with natural audio synchronization and identity consistency. This paper presents StableAvatar, the first end-to-end video diffusion transformer that synthesizes infinite-length high-quality videos without post-processing. Conditioned on a reference image and audio, StableAvatar integrates tailored training and inference modules to enable infinite-length video generation. We observe that the main reason preventing existing models from generating long videos lies in their audio modeling. They typically rely on third-party off-the-shelf extractors to obtain audio embeddings, which are then directly injected into the diffusion model via cross-attention. Since current diffusion backbones lack any audio-related priors, this approach causes severe latent distribution error accumulation across video clips, leading the latent distribution of subsequent segments to drift away from the optimal distribution gradually. To address this, StableAvatar introduces a novel Time-step-aware Audio Adapter that prevents error accumulation via time-step-aware modulation. During inference, we propose a novel Audio Native Guidance Mechanism to further enhance the audio synchronization by leveraging the diffusion's own evolving joint audio-latent prediction as a dynamic guidance signal. To enhance the smoothness of the infinite-length videos, we introduce a Dynamic Weighted Sliding-window Strategy that fuses latent over time. Experiments on benchmarks show the effectiveness of StableAvatar both qualitatively and quantitatively.
Phi-Ground Tech Report: Advancing Perception in GUI Grounding
Jul 31, 2025



With the development of multimodal reasoning models, Computer Use Agents (CUAs), akin to Jarvis from \textit{"Iron Man"}, are becoming a reality. GUI grounding is a core component for CUAs to execute actual actions, similar to mechanical control in robotics, and it directly leads to the success or failure of the system. It determines actions such as clicking and typing, as well as related parameters like the coordinates for clicks. Current end-to-end grounding models still achieve less than 65\% accuracy on challenging benchmarks like ScreenSpot-pro and UI-Vision, indicating they are far from being ready for deployment. % , as a single misclick can result in unacceptable consequences. In this work, we conduct an empirical study on the training of grounding models, examining details from data collection to model training. Ultimately, we developed the \textbf{Phi-Ground} model family, which achieves state-of-the-art performance across all five grounding benchmarks for models under $10B$ parameters in agent settings. In the end-to-end model setting, our model still achieves SOTA results with scores of \textit{\textbf{43.2}} on ScreenSpot-pro and \textit{\textbf{27.2}} on UI-Vision. We believe that the various details discussed in this paper, along with our successes and failures, not only clarify the construction of grounding models but also benefit other perception tasks. Project homepage: \href{https://zhangmiaosen2000.github.io/Phi-Ground/}{https://zhangmiaosen2000.github.io/Phi-Ground/}
ViaRL: Adaptive Temporal Grounding via Visual Iterated Amplification Reinforcement Learning
May 21, 2025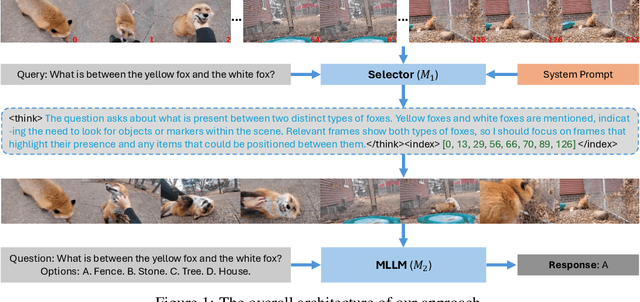
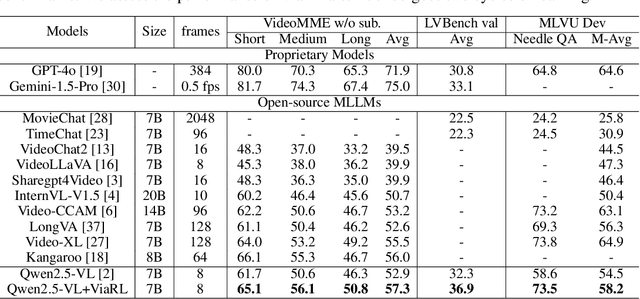
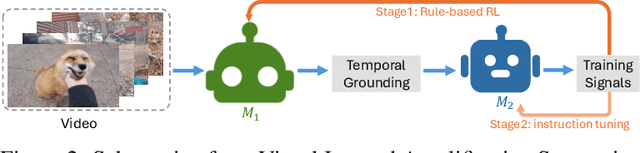

Video understanding is inherently intention-driven-humans naturally focus on relevant frames based on their goals. Recent advancements in multimodal large language models (MLLMs) have enabled flexible query-driven reasoning; however, video-based frameworks like Video Chain-of-Thought lack direct training signals to effectively identify relevant frames. Current approaches often rely on heuristic methods or pseudo-label supervised annotations, which are both costly and limited in scalability across diverse scenarios. To overcome these challenges, we introduce ViaRL, the first framework to leverage rule-based reinforcement learning (RL) for optimizing frame selection in intention-driven video understanding. An iterated amplification strategy is adopted to perform alternating cyclic training in the video CoT system, where each component undergoes iterative cycles of refinement to improve its capabilities. ViaRL utilizes the answer accuracy of a downstream model as a reward signal to train a frame selector through trial-and-error, eliminating the need for expensive annotations while closely aligning with human-like learning processes. Comprehensive experiments across multiple benchmarks, including VideoMME, LVBench, and MLVU, demonstrate that ViaRL consistently delivers superior temporal grounding performance and robust generalization across diverse video understanding tasks, highlighting its effectiveness and scalability. Notably, ViaRL achieves a nearly 15\% improvement on Needle QA, a subset of MLVU, which is required to search a specific needle within a long video and regarded as one of the most suitable benchmarks for evaluating temporal grounding.
JointDiT: Enhancing RGB-Depth Joint Modeling with Diffusion Transformers
May 01, 2025We present JointDiT, a diffusion transformer that models the joint distribution of RGB and depth. By leveraging the architectural benefit and outstanding image prior of the state-of-the-art diffusion transformer, JointDiT not only generates high-fidelity images but also produces geometrically plausible and accurate depth maps. This solid joint distribution modeling is achieved through two simple yet effective techniques that we propose, i.e., adaptive scheduling weights, which depend on the noise levels of each modality, and the unbalanced timestep sampling strategy. With these techniques, we train our model across all noise levels for each modality, enabling JointDiT to naturally handle various combinatorial generation tasks, including joint generation, depth estimation, and depth-conditioned image generation by simply controlling the timestep of each branch. JointDiT demonstrates outstanding joint generation performance. Furthermore, it achieves comparable results in depth estimation and depth-conditioned image generation, suggesting that joint distribution modeling can serve as a replaceable alternative to conditional generation. The project page is available at https://byungki-k.github.io/JointDiT/.
Subject-driven Video Generation via Disentangled Identity and Motion
Apr 23, 2025We propose to train a subject-driven customized video generation model through decoupling the subject-specific learning from temporal dynamics in zero-shot without additional tuning. A traditional method for video customization that is tuning-free often relies on large, annotated video datasets, which are computationally expensive and require extensive annotation. In contrast to the previous approach, we introduce the use of an image customization dataset directly on training video customization models, factorizing the video customization into two folds: (1) identity injection through image customization dataset and (2) temporal modeling preservation with a small set of unannotated videos through the image-to-video training method. Additionally, we employ random image token dropping with randomized image initialization during image-to-video fine-tuning to mitigate the copy-and-paste issue. To further enhance learning, we introduce stochastic switching during joint optimization of subject-specific and temporal features, mitigating catastrophic forgetting. Our method achieves strong subject consistency and scalability, outperforming existing video customization models in zero-shot settings, demonstrating the effectiveness of our framework.
Securing the Skies: A Comprehensive Survey on Anti-UAV Methods, Benchmarking, and Future Directions
Apr 16, 2025Unmanned Aerial Vehicles (UAVs) are indispensable for infrastructure inspection, surveillance, and related tasks, yet they also introduce critical security challenges. This survey provides a wide-ranging examination of the anti-UAV domain, centering on three core objectives-classification, detection, and tracking-while detailing emerging methodologies such as diffusion-based data synthesis, multi-modal fusion, vision-language modeling, self-supervised learning, and reinforcement learning. We systematically evaluate state-of-the-art solutions across both single-modality and multi-sensor pipelines (spanning RGB, infrared, audio, radar, and RF) and discuss large-scale as well as adversarially oriented benchmarks. Our analysis reveals persistent gaps in real-time performance, stealth detection, and swarm-based scenarios, underscoring pressing needs for robust, adaptive anti-UAV systems. By highlighting open research directions, we aim to foster innovation and guide the development of next-generation defense strategies in an era marked by the extensive use of UAVs.
MagicMotion: Controllable Video Generation with Dense-to-Sparse Trajectory Guidance
Mar 20, 2025Recent advances in video generation have led to remarkable improvements in visual quality and temporal coherence. Upon this, trajectory-controllable video generation has emerged to enable precise object motion control through explicitly defined spatial paths. However, existing methods struggle with complex object movements and multi-object motion control, resulting in imprecise trajectory adherence, poor object consistency, and compromised visual quality. Furthermore, these methods only support trajectory control in a single format, limiting their applicability in diverse scenarios. Additionally, there is no publicly available dataset or benchmark specifically tailored for trajectory-controllable video generation, hindering robust training and systematic evaluation. To address these challenges, we introduce MagicMotion, a novel image-to-video generation framework that enables trajectory control through three levels of conditions from dense to sparse: masks, bounding boxes, and sparse boxes. Given an input image and trajectories, MagicMotion seamlessly animates objects along defined trajectories while maintaining object consistency and visual quality. Furthermore, we present MagicData, a large-scale trajectory-controlled video dataset, along with an automated pipeline for annotation and filtering. We also introduce MagicBench, a comprehensive benchmark that assesses both video quality and trajectory control accuracy across different numbers of objects. Extensive experiments demonstrate that MagicMotion outperforms previous methods across various metrics. Our project page are publicly available at https://quanhaol.github.io/magicmotion-site.