 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Generic Event Boundary Detection
Oct 08, 2025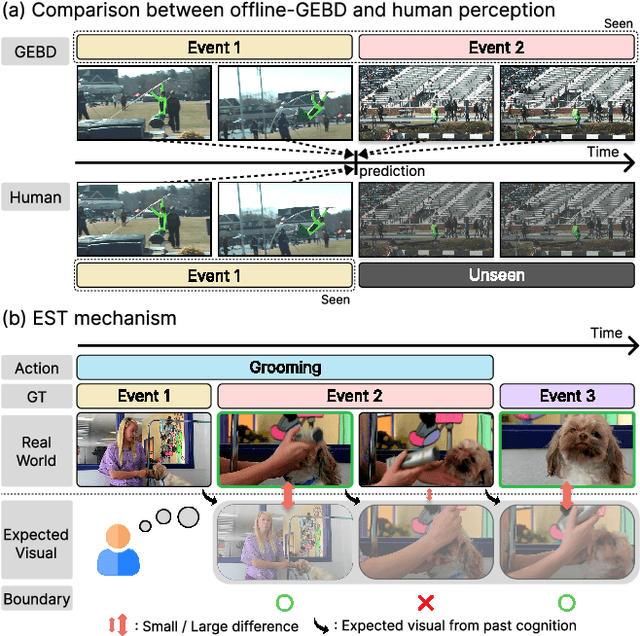
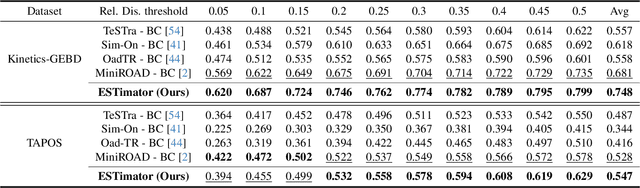
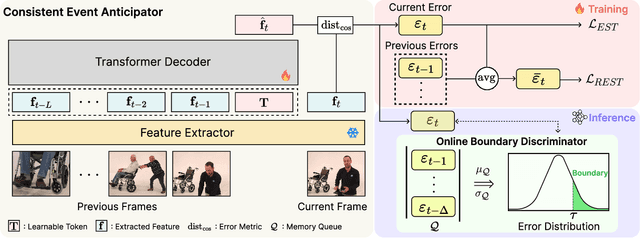
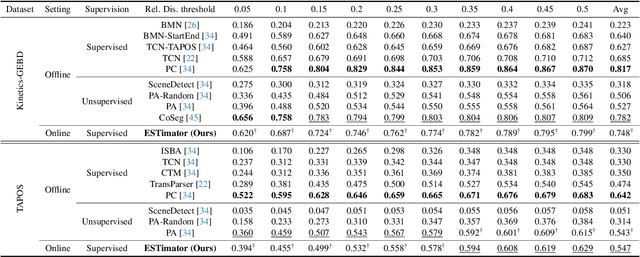
Generic Event Boundary Detection (GEBD) aims to interpret long-form videos through the lens of human perception. However, current GEBD methods require processing complete video frames to make predictions, unlike humans processing data online and in real-time. To bridge this gap, we introduce a new task, Online Generic Event Boundary Detection (On-GEBD), aiming to detect boundaries of generic events immediately in streaming videos. This task faces unique challenges of identifying subtle, taxonomy-free event changes in real-time, without the access to future frames. To tackle these challenges, we propose a novel On-GEBD framework, Estimator, inspired by Event Segmentation Theory (EST) which explains how humans segment ongoing activity into events by leveraging the discrepancies between predicted and actual information. Our framework consists of two key components: the Consistent Event Anticipator (CEA), and the Online Boundary Discriminator (OBD). Specifically, the CEA generates a prediction of the future frame reflecting current event dynamics based solely on prior frames. Then, the OBD measures the prediction error and adaptively adjusts the threshold using statistical tests on past errors to capture diverse, subtle event transitions. Experimental results demonstrate that Estimator outperforms all baselines adapted from recent online video understanding models and achieves performance comparable to prior offline-GEBD methods on the Kinetics-GEBD and TAPOS datasets.
Exploring Multimodal Diffusion Transformers for Enhanced Prompt-based Image Editing
Aug 11, 2025Transformer-based diffusion models have recently superseded traditional U-Net architectures, with multimodal diffusion transformers (MM-DiT) emerging as the dominant approach in state-of-the-art models like Stable Diffusion 3 and Flux.1. Previous approaches have relied on unidirectional cross-attention mechanisms, with information flowing from text embeddings to image latents. In contrast, MMDiT introduces a unified attention mechanism that concatenates input projections from both modalities and performs a single full attention operation, allowing bidirectional information flow between text and image branches. This architectural shift presents significant challenges for existing editing techniques. In this paper, we systematically analyze MM-DiT's attention mechanism by decomposing attention matrices into four distinct blocks, revealing their inherent characteristics. Through these analyses, we propose a robust, prompt-based image editing method for MM-DiT that supports global to local edits across various MM-DiT variants, including few-step models. We believe our findings bridge the gap between existing U-Net-based methods and emerging architectures, offering deeper insights into MMDiT's behavioral patterns.
Improving Editability in Image Generation with Layer-wise Memory
May 02, 2025
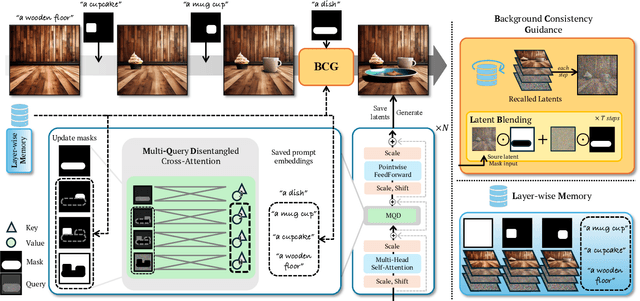
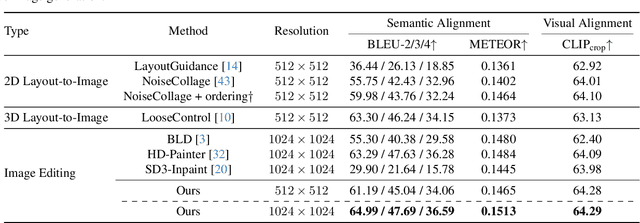
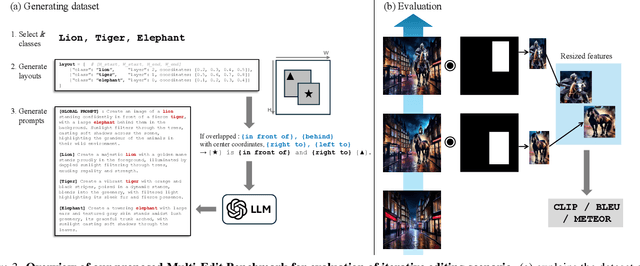
Most real-world image editing tasks require multiple sequential edits to achieve desired results. Current editing approaches, primarily designed for single-object modifications, struggle with sequential editing: especially with maintaining previous edits along with adapting new objects naturally into the existing content. These limitations significantly hinder complex editing scenarios where multiple objects need to be modified while preserving their contextual relationships. We address this fundamental challenge through two key proposals: enabling rough mask inputs that preserve existing content while naturally integrating new elements and supporting consistent editing across multiple modifications. Our framework achieves this through layer-wise memory, which stores latent representations and prompt embeddings from previous edits. We propose Background Consistency Guidance that leverages memorized latents to maintain scene coherence and Multi-Query Disentanglement in cross-attention that ensures natural adaptation to existing content. To evaluate our method, we present a new benchmark dataset incorporating semantic alignment metrics and interactive editing scenarios. Through comprehensive experiments, we demonstrate superior performance in iterative image editing tasks with minimal user effort, requiring only rough masks while maintaining high-quality results throughout multiple editing steps.
Subject-driven Video Generation via Disentangled Identity and Motion
Apr 23, 2025We propose to train a subject-driven customized video generation model through decoupling the subject-specific learning from temporal dynamics in zero-shot without additional tuning. A traditional method for video customization that is tuning-free often relies on large, annotated video datasets, which are computationally expensive and require extensive annotation. In contrast to the previous approach, we introduce the use of an image customization dataset directly on training video customization models, factorizing the video customization into two folds: (1) identity injection through image customization dataset and (2) temporal modeling preservation with a small set of unannotated videos through the image-to-video training method. Additionally, we employ random image token dropping with randomized image initialization during image-to-video fine-tuning to mitigate the copy-and-paste issue. To further enhance learning, we introduce stochastic switching during joint optimization of subject-specific and temporal features, mitigating catastrophic forgetting. Our method achieves strong subject consistency and scalability, outperforming existing video customization models in zero-shot settings, demonstrating the effectiveness of our framework.
Pick-or-Mix: Dynamic Channel Sampling for ConvNets
Jun 16, 2024



Channel pruning approaches for convolutional neural networks (ConvNets) deactivate the channels, statically or dynamically, and require special implementation. In addition, channel squeezing in representative ConvNets is carried out via 1x1 convolutions which dominates a large portion of computations and network parameters. Given these challenges, we propose an effective multi-purpose module for dynamic channel sampling, namely Pick-or-Mix (PiX), which does not require special implementation. PiX divides a set of channels into subsets and then picks from them, where the picking decision is dynamically made per each pixel based on the input activations. We plug PiX into prominent ConvNet architectures and verify its multi-purpose utilities. After replacing 1x1 channel squeezing layers in ResNet with PiX, the network becomes 25% faster without losing accuracy. We show that PiX allows ConvNets to learn better data representation than widely adopted approaches to enhance networks' representation power (e.g., SE, CBAM, AFF, SKNet, and DWP). We also show that PiX achieves state-of-the-art performance on network downscaling and dynamic channel pruning applications.
* Published in Computer Vision and Pattern Recognition (CVPR 2024)
Story Visualization by Online Text Augmentation with Context Memory
Aug 19, 2023
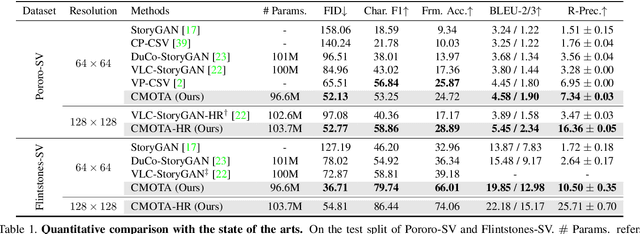
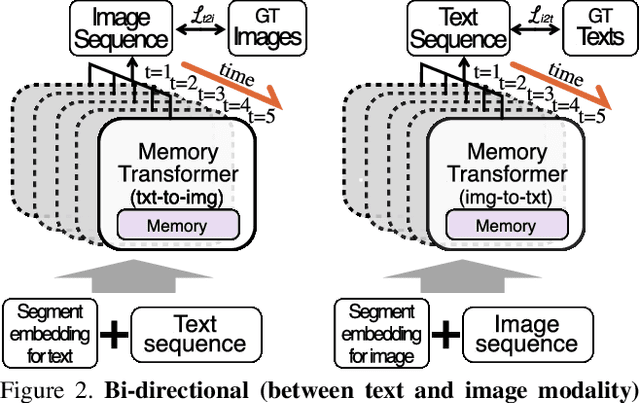
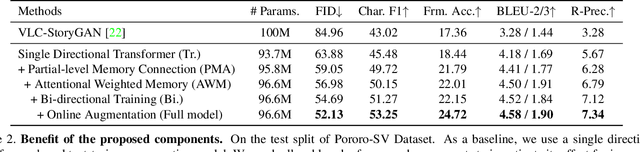
Story visualization (SV) is a challenging text-to-image generation task for the difficulty of not only rendering visual details from the text descriptions but also encoding a long-term context across multiple sentences. While prior efforts mostly focus on generating a semantically relevant image for each sentence, encoding a context spread across the given paragraph to generate contextually convincing images (e.g., with a correct character or with a proper background of the scene) remains a challenge. To this end, we propose a novel memory architecture for the Bi-directional Transformer framework with an online text augmentation that generates multiple pseudo-descriptions as supplementary supervision during training for better generalization to the language variation at inference. In extensive experiments on the two popular SV benchmarks, i.e., the Pororo-SV and Flintstones-SV, the proposed method significantly outperforms the state of the arts in various metrics including FID, character F1, frame accuracy, BLEU-2/3, and R-precision with similar or less computational complexity.