 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCALE: Self-uncertainty Conditioned Adaptive Looking and Execution for Vision-Language-Action Models
Feb 04, 2026Vision-Language-Action (VLA) models have emerged as a promising paradigm for general-purpose robotic control, with test-time scaling (TTS) gaining attention to enhance robustness beyond training. However, existing TTS methods for VLAs require additional training, verifiers, and multiple forward passes, making them impractical for deployment. Moreover, they intervene only at action decoding while keeping visual representations fixed-insufficient under perceptual ambiguity, where reconsidering how to perceive is as important as deciding what to do. To address these limitations, we propose SCALE, a simple inference strategy that jointly modulates visual perception and action based on 'self-uncertainty', inspired by uncertainty-driven exploration in Active Inference theory-requiring no additional training, no verifier, and only a single forward pass. SCALE broadens exploration in both perception and action under high uncertainty, while focusing on exploitation when confident-enabling adaptive execution across varying conditions. Experiments on simulated and real-world benchmarks demonstrate that SCALE improves state-of-the-art VLAs and outperforms existing TTS methods while maintaining single-pass efficiency.
ICP-4D: Bridging Iterative Closest Point and LiDAR Panoptic Segmentation
Dec 22, 2025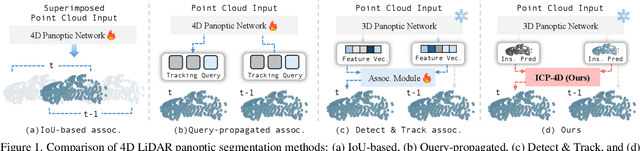
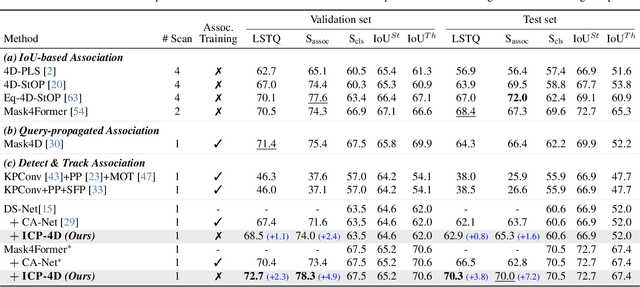
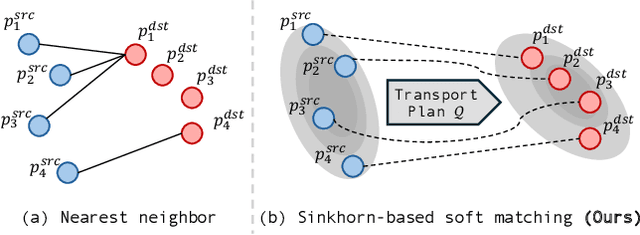
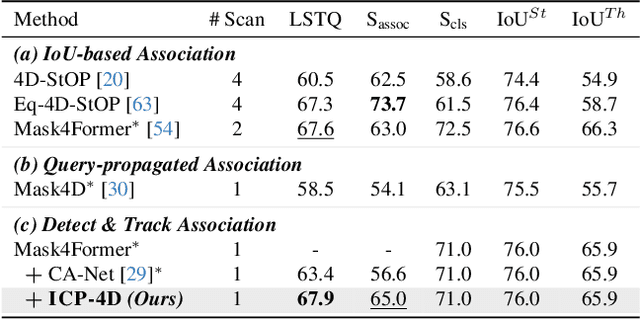
Dominant paradigms for 4D LiDAR panoptic segmentation are usually required to train deep neural networks with large superimposed point clouds or design dedicated modules for instance association. However, these approaches perform redundant point processing and consequently become computationally expensive, yet still overlook the rich geometric priors inherently provided by raw point clouds. To this end, we introduce ICP-4D, a simple yet effective training-free framework that unifies spatial and temporal reasoning through geometric relations among instance-level point sets. Specifically, we apply the Iterative Closest Point (ICP) algorithm to directly associate temporally consistent instances by aligning the source and target point sets through the estimated transformation. To stabilize association under noisy instance predictions, we introduce a Sinkhorn-based soft matching. This exploits the underlying instance distribution to obtain accurate point-wise correspondences, resulting in robust geometric alignment. Furthermore, our carefully designed pipeline, which considers three instance types-static, dynamic, and missing-offers computational efficiency and occlusion-aware matching. Our extensive experiments across both SemanticKITTI and panoptic nuScenes demonstrate that our method consistently outperforms state-of-the-art approaches, even without additional training or extra point cloud inputs.
HyGE-Occ: Hybrid View-Transformation with 3D Gaussian and Edge Priors for 3D Panoptic Occupancy Prediction
Dec 22, 20253D Panoptic Occupancy Prediction aims to reconstruct a dense volumetric scene map by predicting the semantic class and instance identity of every occupied region in 3D space. Achieving such fine-grained 3D understanding requires precise geometric reasoning and spatially consistent scene representation across complex environments. However, existing approaches often struggle to maintain precise geometry and capture the precise spatial range of 3D instances critical for robust panoptic separation. To overcome these limitations, we introduce HyGE-Occ, a novel framework that leverages a hybrid view-transformation branch with 3D Gaussian and edge priors to enhance both geometric consistency and boundary awareness in 3D panoptic occupancy prediction. HyGE-Occ employs a hybrid view-transformation branch that fuses a continuous Gaussian-based depth representation with a discretized depth-bin formulation, producing BEV features with improved geometric consistency and structural coherence. In parallel, we extract edge maps from BEV features and use them as auxiliary information to learn edge cues. In our extensive experiments on the Occ3D-nuScenes dataset, HyGE-Occ outperforms existing work, demonstrating superior 3D geometric reasoning.
Online Generic Event Boundary Detection
Oct 08, 2025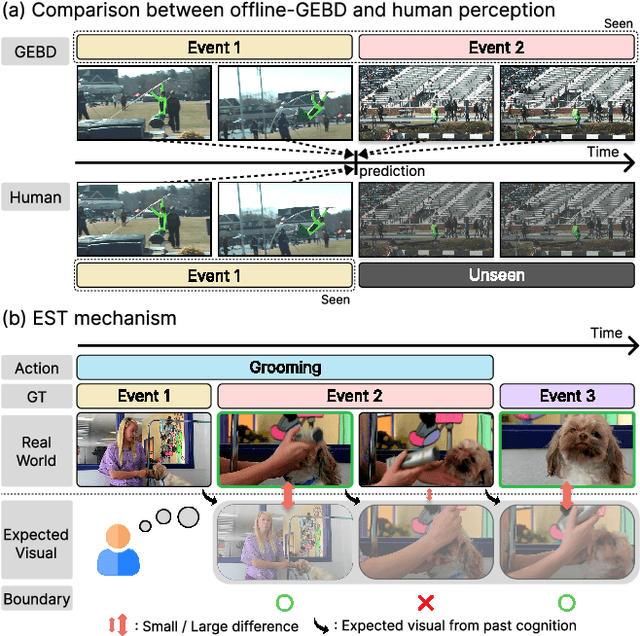
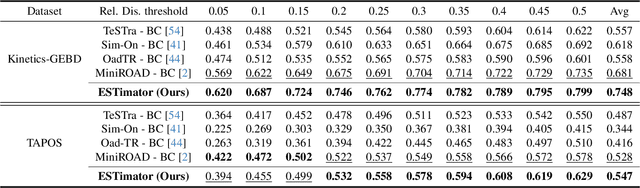
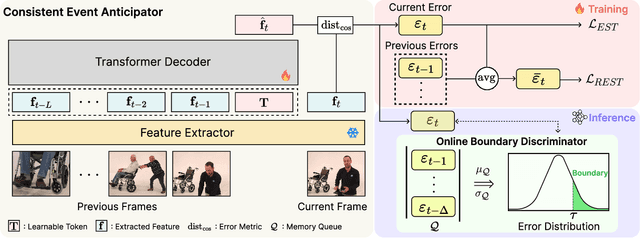
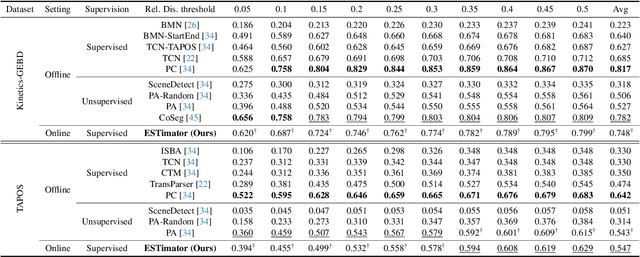
Generic Event Boundary Detection (GEBD) aims to interpret long-form videos through the lens of human perception. However, current GEBD methods require processing complete video frames to make predictions, unlike humans processing data online and in real-time. To bridge this gap, we introduce a new task, Online Generic Event Boundary Detection (On-GEBD), aiming to detect boundaries of generic events immediately in streaming videos. This task faces unique challenges of identifying subtle, taxonomy-free event changes in real-time, without the access to future frames. To tackle these challenges, we propose a novel On-GEBD framework, Estimator, inspired by Event Segmentation Theory (EST) which explains how humans segment ongoing activity into events by leveraging the discrepancies between predicted and actual information. Our framework consists of two key components: the Consistent Event Anticipator (CEA), and the Online Boundary Discriminator (OBD). Specifically, the CEA generates a prediction of the future frame reflecting current event dynamics based solely on prior frames. Then, the OBD measures the prediction error and adaptively adjusts the threshold using statistical tests on past errors to capture diverse, subtle event transitions. Experimental results demonstrate that Estimator outperforms all baselines adapted from recent online video understanding models and achieves performance comparable to prior offline-GEBD methods on the Kinetics-GEBD and TAPOS datasets.
DialNav: Multi-turn Dialog Navigation with a Remote Guide
Sep 16, 2025We introduce DialNav, a novel collaborative embodied dialog task, where a navigation agent (Navigator) and a remote guide (Guide) engage in multi-turn dialog to reach a goal location. Unlike prior work, DialNav aims for holistic evaluation and requires the Guide to infer the Navigator's location, making communication essential for task success. To support this task, we collect and release the Remote Assistance in Navigation (RAIN) dataset, human-human dialog paired with navigation trajectories in photorealistic environments. We design a comprehensive benchmark to evaluate both navigation and dialog, and conduct extensive experiments analyzing the impact of different Navigator and Guide models. We highlight key challenges and publicly release the dataset, code, and evaluation framework to foster future research in embodied dialog.
Representation Bending for Large Language Model Safety
Apr 02, 2025Large Language Models (LLMs) have emerged as powerful tools, but their inherent safety risks - ranging from harmful content generation to broader societal harms - pose significant challenges. These risks can be amplified by the recent adversarial attacks, fine-tuning vulnerabilities, and the increasing deployment of LLMs in high-stakes environments. Existing safety-enhancing techniques, such as fine-tuning with human feedback or adversarial training, are still vulnerable as they address specific threats and often fail to generalize across unseen attacks, or require manual system-level defenses. This paper introduces RepBend, a novel approach that fundamentally disrupts the representations underlying harmful behaviors in LLMs, offering a scalable solution to enhance (potentially inherent) safety. RepBend brings the idea of activation steering - simple vector arithmetic for steering model's behavior during inference - to loss-based fine-tuning. Through extensive evaluation, RepBend achieves state-of-the-art performance, outperforming prior methods such as Circuit Breaker, RMU, and NPO, with up to 95% reduction in attack success rates across diverse jailbreak benchmarks, all with negligible reduction in model usability and general capabilities.
Multi-Modal Grounded Planning and Efficient Replanning For Learning Embodied Agents with A Few Examples
Dec 23, 2024Learning a perception and reasoning module for robotic assistants to plan steps to perform complex tasks based on natural language instructions often requires large free-form language annotations, especially for short high-level instructions. To reduce the cost of annotation, large language models (LLMs) are used as a planner with few data. However, when elaborating the steps, even the state-of-the-art planner that uses LLMs mostly relies on linguistic common sense, often neglecting the status of the environment at command reception, resulting in inappropriate plans. To generate plans grounded in the environment, we propose FLARE (Few-shot Language with environmental Adaptive Replanning Embodied agent), which improves task planning using both language command and environmental perception. As language instructions often contain ambiguities or incorrect expressions, we additionally propose to correct the mistakes using visual cues from the agent. The proposed scheme allows us to use a few language pairs thanks to the visual cues and outperforms state-of-the-art approaches. Our code is available at https://github.com/snumprlab/flare.
Large Language Models Still Exhibit Bias in Long Text
Oct 23, 2024


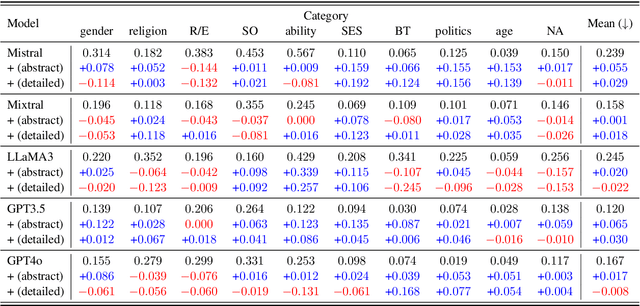
Existing fairness benchmarks for large language models (LLMs) primarily focus on simple tasks, such as multiple-choice questions, overlooking biases that may arise in more complex scenarios like long-text generation. To address this gap, we introduce the Long Text Fairness Test (LTF-TEST), a framework that evaluates biases in LLMs through essay-style prompts. LTF-TEST covers 14 topics and 10 demographic axes, including gender and race, resulting in 11,948 samples. By assessing both model responses and the reasoning behind them, LTF-TEST uncovers subtle biases that are difficult to detect in simple responses. In our evaluation of five recent LLMs, including GPT-4o and LLaMa3, we identify two key patterns of bias. First, these models frequently favor certain demographic groups in their responses. Second, they show excessive sensitivity toward traditionally disadvantaged groups, often providing overly protective responses while neglecting others. To mitigate these biases, we propose FT-REGARD, a finetuning approach that pairs biased prompts with neutral responses. FT-REGARD reduces gender bias by 34.6% and improves performance by 1.4 percentage points on the BBQ benchmark, offering a promising approach to addressing biases in long-text generation tasks.
Budgeted Online Continual Learning by Adaptive Layer Freezing and Frequency-based Sampling
Oct 19, 2024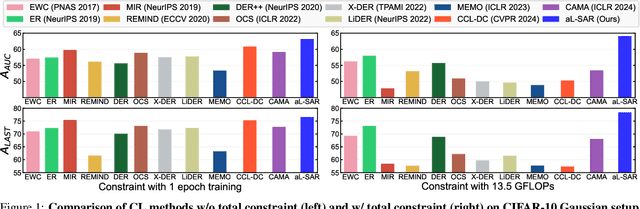
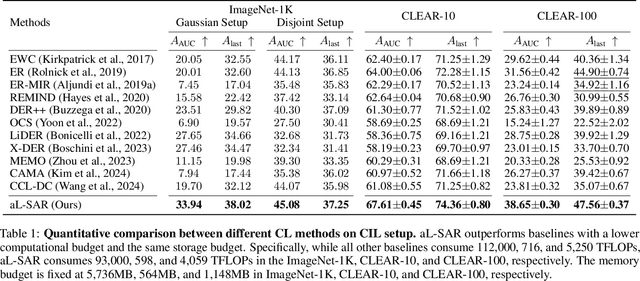
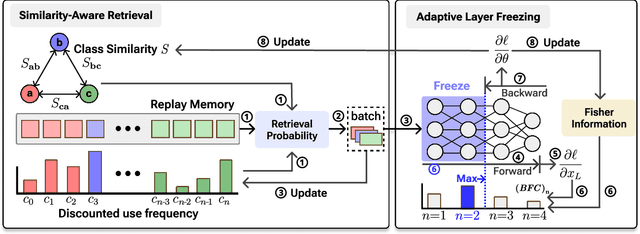
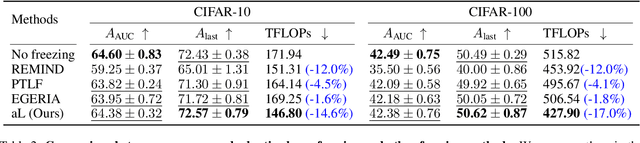
The majority of online continual learning (CL) advocates single-epoch training and imposes restrictions on the size of replay memory. However, single-epoch training would incur a different amount of computations per CL algorithm, and the additional storage cost to store logit or model in addition to replay memory is largely ignored in calculating the storage budget. Arguing different computational and storage budgets hinder fair comparison among CL algorithms in practice, we propose to use floating point operations (FLOPs) and total memory size in Byte as a metric for computational and memory budgets, respectively, to compare and develop CL algorithms in the same 'total resource budget.' To improve a CL method in a limited total budget, we propose adaptive layer freezing that does not update the layers for less informative batches to reduce computational costs with a negligible loss of accuracy. In addition, we propose a memory retrieval method that allows the model to learn the same amount of knowledge as using random retrieval in fewer iterations. Empirical validations on the CIFAR-10/100, CLEAR-10/100, and ImageNet-1K datasets demonstrate that the proposed approach outperforms the state-of-the-art methods within the same total budget
ReALFRED: An Embodied Instruction Following Benchmark in Photo-Realistic Environments
Jul 26, 2024

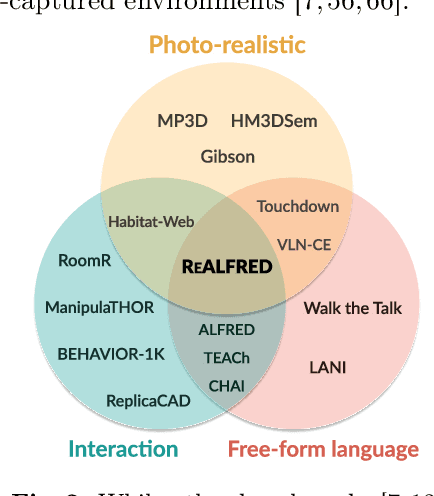

Simulated virtual environments have been widely used to learn robotic agents that perform daily household tasks. These environments encourage research progress by far, but often provide limited object interactability, visual appearance different from real-world environments, or relatively smaller environment sizes. This prevents the learned models in the virtual scenes from being readily deployable. To bridge the gap between these learning environments and deploying (i.e., real) environments, we propose the ReALFRED benchmark that employs real-world scenes, objects, and room layouts to learn agents to complete household tasks by understanding free-form language instructions and interacting with objects in large, multi-room and 3D-captured scenes. Specifically, we extend the ALFRED benchmark with updates for larger environmental spaces with smaller visual domain gaps. With ReALFRED, we analyze previously crafted methods for the ALFRED benchmark and observe that they consistently yield lower performance in all metrics, encouraging the community to develop methods in more realistic environments. Our code and data are publicly available.