 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo You See What I Am Pointing At? Gesture-Based Egocentric Video Question Answering
Mar 13, 2026Understanding and answering questions based on a user's pointing gesture is essential for next-generation egocentric AI assistants. However, current Multimodal Large Language Models (MLLMs) struggle with such tasks due to the lack of gesture-rich data and their limited ability to infer fine-grained pointing intent from egocentric video. To address this, we introduce EgoPointVQA, a dataset and benchmark for gesture-grounded egocentric question answering, comprising 4000 synthetic and 400 real-world videos across multiple deictic reasoning tasks. Built upon it, we further propose Hand Intent Tokens (HINT), which encodes tokens derived from 3D hand keypoints using an off-the-shelf reconstruction model and interleaves them with the model input to provide explicit spatial and temporal context for interpreting pointing intent. We show that our model outperforms others in different backbones and model sizes. In particular, HINT-14B achieves 68.1% accuracy, on average over 6 tasks, surpassing the state-of-the-art, InternVL3-14B, by 6.6%. To further facilitate the open research, we will release the code, model, and dataset. Project page: https://yuuraa.github.io/papers/choi2026egovqa
i-SRT: Aligning Large Multimodal Models for Videos by Iterative Self-Retrospective Judgment
Jun 17, 2024
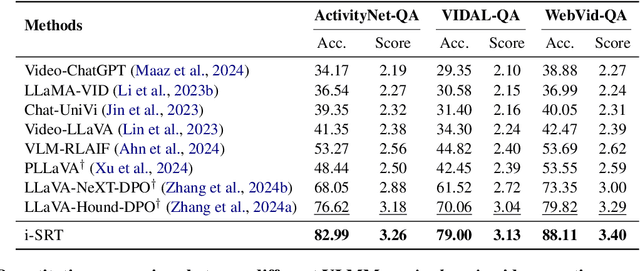
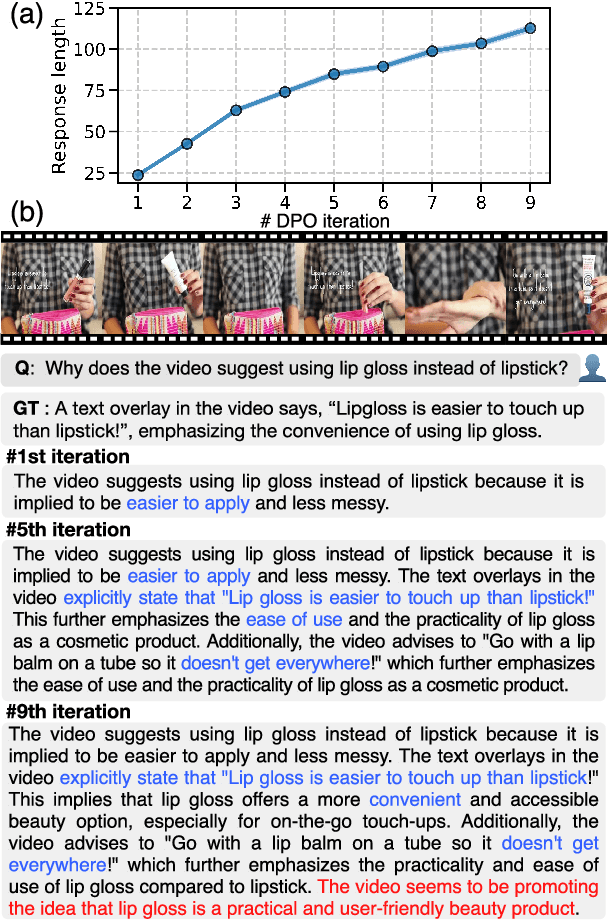
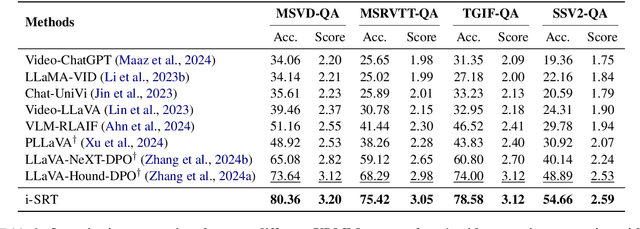
Aligning Video Large Multimodal Models (VLMMs) face challenges such as modality misalignment and verbose responses. Although iterative approaches such as self-rewarding or iterative direct preference optimization (DPO) recently showed a significant improvement in language model alignment, particularly on reasoning tasks, self-aligned models applied to large video-language models often result in lengthy and irrelevant responses. To address these challenges, we propose a novel method that employs self-retrospection to enhance both response generation and preference modeling, and call iterative self-retrospective judgment (i-SRT). By revisiting and evaluating already generated content and preference in loop, i-SRT improves the alignment between textual and visual modalities, reduce verbosity, and enhances content relevance. Our empirical evaluations across diverse video question answering benchmarks demonstrate that i-SRT significantly outperforms prior arts. We are committed to opensourcing our code, models, and datasets to encourage further investigation.
Tuning Large Multimodal Models for Videos using Reinforcement Learning from AI Feedback
Feb 16, 2024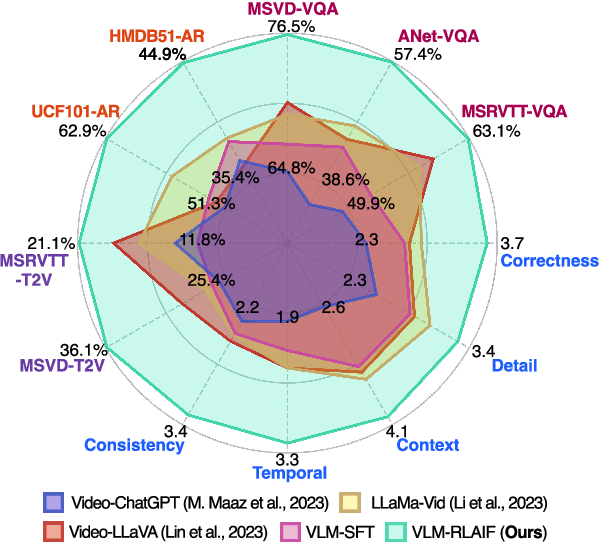



Recent advancements in large language models have influenced the development of video large multimodal models (VLMMs). The previous approaches for VLMMs involved Supervised Fine-Tuning (SFT) with instruction-tuned datasets, integrating LLM with visual encoders, and adding additional learnable modules. Video and text multimodal alignment remains challenging, primarily due to the deficient volume and quality of multimodal instruction-tune data compared to text-only data. We present a novel alignment strategy that employs multimodal AI system to oversee itself called Reinforcement Learning from AI Feedback (RLAIF), providing self-preference feedback to refine itself and facilitating the alignment of video and text modalities. In specific, we propose context-aware reward modeling by providing detailed video descriptions as context during the generation of preference feedback in order to enrich the understanding of video content. Demonstrating enhanced performance across diverse video benchmarks, our multimodal RLAIF approach, VLM-RLAIF, outperforms existing approaches, including the SFT model. We commit to open-sourcing our code, models, and datasets to foster further research in this area.