 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTuning Large Multimodal Models for Videos using Reinforcement Learning from AI Feedback
Paper and Code
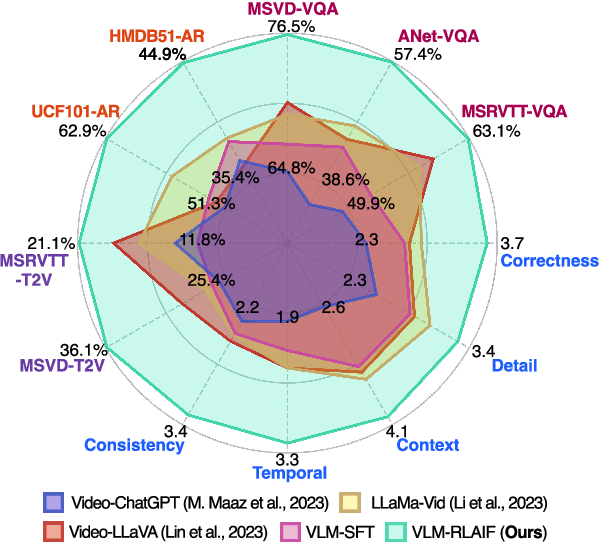



Recent advancements in large language models have influenced the development of video large multimodal models (VLMMs). The previous approaches for VLMMs involved Supervised Fine-Tuning (SFT) with instruction-tuned datasets, integrating LLM with visual encoders, and adding additional learnable modules. Video and text multimodal alignment remains challenging, primarily due to the deficient volume and quality of multimodal instruction-tune data compared to text-only data. We present a novel alignment strategy that employs multimodal AI system to oversee itself called Reinforcement Learning from AI Feedback (RLAIF), providing self-preference feedback to refine itself and facilitating the alignment of video and text modalities. In specific, we propose context-aware reward modeling by providing detailed video descriptions as context during the generation of preference feedback in order to enrich the understanding of video content. Demonstrating enhanced performance across diverse video benchmarks, our multimodal RLAIF approach, VLM-RLAIF, outperforms existing approaches, including the SFT model. We commit to open-sourcing our code, models, and datasets to foster further research in this area.