 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCALE: Self-uncertainty Conditioned Adaptive Looking and Execution for Vision-Language-Action Models
Feb 04, 2026Vision-Language-Action (VLA) models have emerged as a promising paradigm for general-purpose robotic control, with test-time scaling (TTS) gaining attention to enhance robustness beyond training. However, existing TTS methods for VLAs require additional training, verifiers, and multiple forward passes, making them impractical for deployment. Moreover, they intervene only at action decoding while keeping visual representations fixed-insufficient under perceptual ambiguity, where reconsidering how to perceive is as important as deciding what to do. To address these limitations, we propose SCALE, a simple inference strategy that jointly modulates visual perception and action based on 'self-uncertainty', inspired by uncertainty-driven exploration in Active Inference theory-requiring no additional training, no verifier, and only a single forward pass. SCALE broadens exploration in both perception and action under high uncertainty, while focusing on exploitation when confident-enabling adaptive execution across varying conditions. Experiments on simulated and real-world benchmarks demonstrate that SCALE improves state-of-the-art VLAs and outperforms existing TTS methods while maintaining single-pass efficiency.
i-SRT: Aligning Large Multimodal Models for Videos by Iterative Self-Retrospective Judgment
Jun 17, 2024
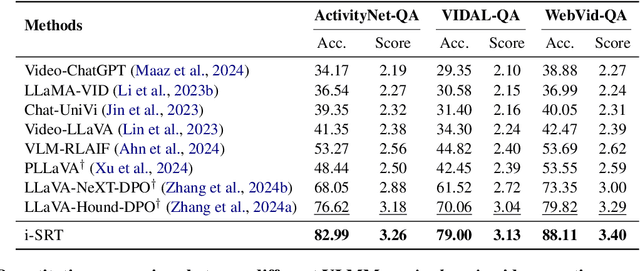
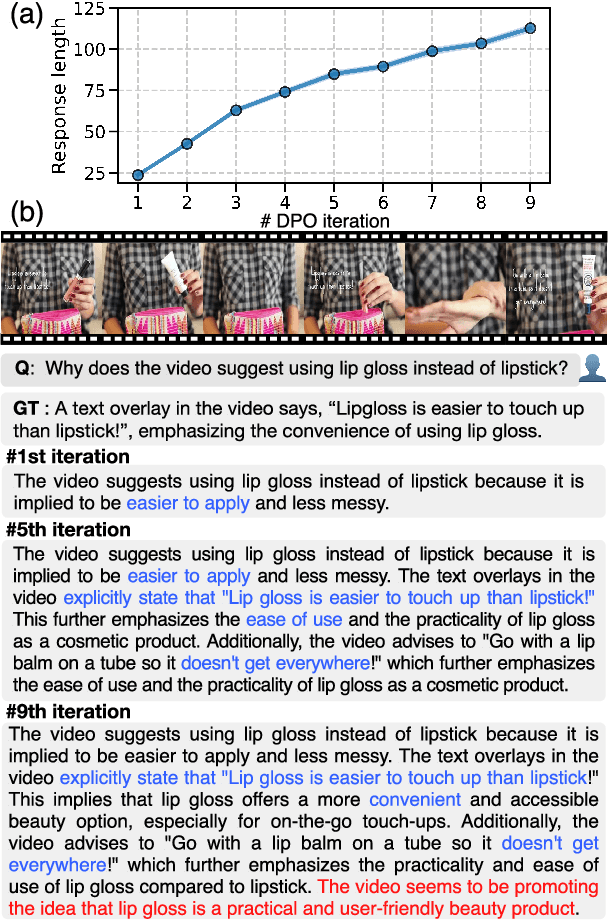
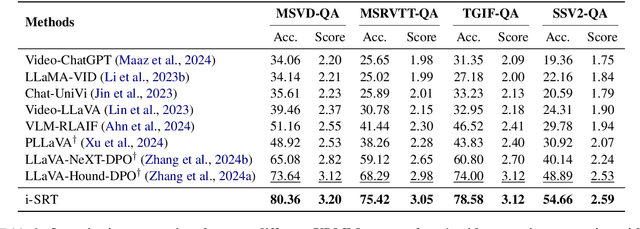
Aligning Video Large Multimodal Models (VLMMs) face challenges such as modality misalignment and verbose responses. Although iterative approaches such as self-rewarding or iterative direct preference optimization (DPO) recently showed a significant improvement in language model alignment, particularly on reasoning tasks, self-aligned models applied to large video-language models often result in lengthy and irrelevant responses. To address these challenges, we propose a novel method that employs self-retrospection to enhance both response generation and preference modeling, and call iterative self-retrospective judgment (i-SRT). By revisiting and evaluating already generated content and preference in loop, i-SRT improves the alignment between textual and visual modalities, reduce verbosity, and enhances content relevance. Our empirical evaluations across diverse video question answering benchmarks demonstrate that i-SRT significantly outperforms prior arts. We are committed to opensourcing our code, models, and datasets to encourage further investigation.
Tuning Large Multimodal Models for Videos using Reinforcement Learning from AI Feedback
Feb 16, 2024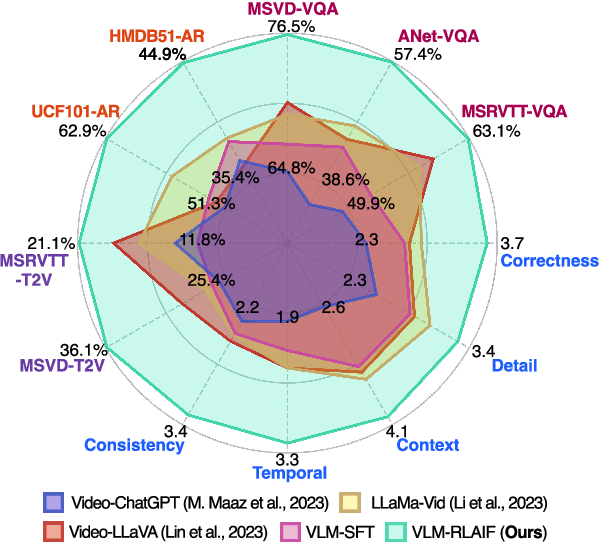



Recent advancements in large language models have influenced the development of video large multimodal models (VLMMs). The previous approaches for VLMMs involved Supervised Fine-Tuning (SFT) with instruction-tuned datasets, integrating LLM with visual encoders, and adding additional learnable modules. Video and text multimodal alignment remains challenging, primarily due to the deficient volume and quality of multimodal instruction-tune data compared to text-only data. We present a novel alignment strategy that employs multimodal AI system to oversee itself called Reinforcement Learning from AI Feedback (RLAIF), providing self-preference feedback to refine itself and facilitating the alignment of video and text modalities. In specific, we propose context-aware reward modeling by providing detailed video descriptions as context during the generation of preference feedback in order to enrich the understanding of video content. Demonstrating enhanced performance across diverse video benchmarks, our multimodal RLAIF approach, VLM-RLAIF, outperforms existing approaches, including the SFT model. We commit to open-sourcing our code, models, and datasets to foster further research in this area.
Story Visualization by Online Text Augmentation with Context Memory
Aug 19, 2023
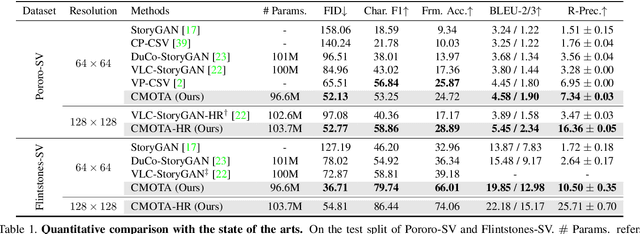
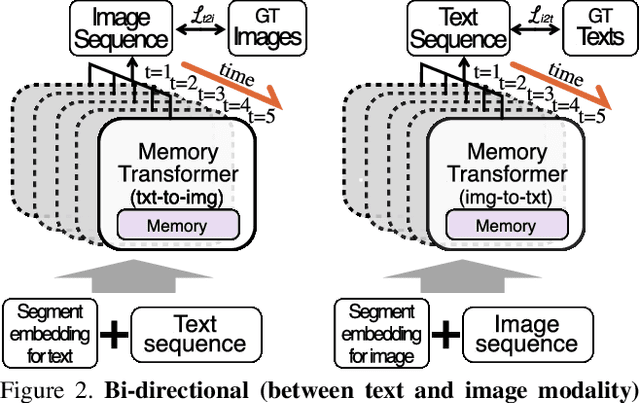
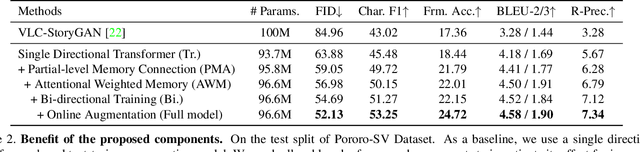
Story visualization (SV) is a challenging text-to-image generation task for the difficulty of not only rendering visual details from the text descriptions but also encoding a long-term context across multiple sentences. While prior efforts mostly focus on generating a semantically relevant image for each sentence, encoding a context spread across the given paragraph to generate contextually convincing images (e.g., with a correct character or with a proper background of the scene) remains a challenge. To this end, we propose a novel memory architecture for the Bi-directional Transformer framework with an online text augmentation that generates multiple pseudo-descriptions as supplementary supervision during training for better generalization to the language variation at inference. In extensive experiments on the two popular SV benchmarks, i.e., the Pororo-SV and Flintstones-SV, the proposed method significantly outperforms the state of the arts in various metrics including FID, character F1, frame accuracy, BLEU-2/3, and R-precision with similar or less computational complexity.