 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgei-SRT: Aligning Large Multimodal Models for Videos by Iterative Self-Retrospective Judgment
Paper and Code

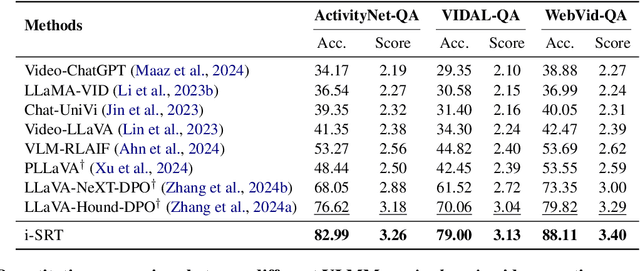
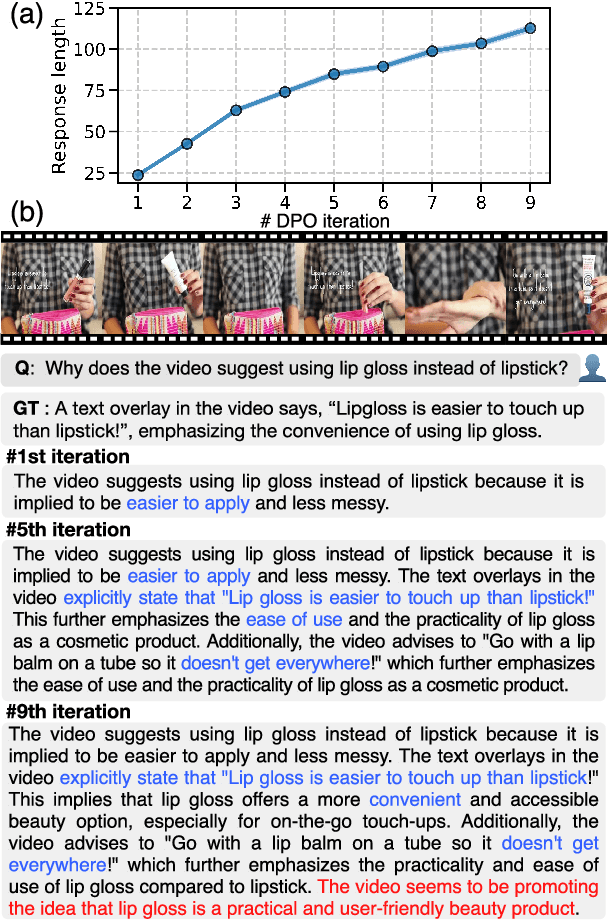
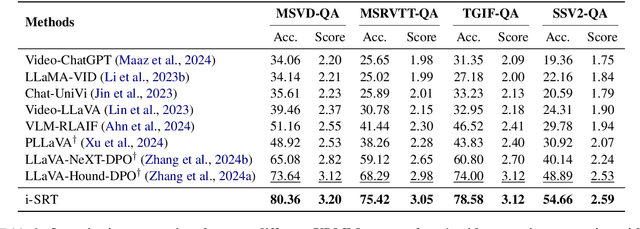
Aligning Video Large Multimodal Models (VLMMs) face challenges such as modality misalignment and verbose responses. Although iterative approaches such as self-rewarding or iterative direct preference optimization (DPO) recently showed a significant improvement in language model alignment, particularly on reasoning tasks, self-aligned models applied to large video-language models often result in lengthy and irrelevant responses. To address these challenges, we propose a novel method that employs self-retrospection to enhance both response generation and preference modeling, and call iterative self-retrospective judgment (i-SRT). By revisiting and evaluating already generated content and preference in loop, i-SRT improves the alignment between textual and visual modalities, reduce verbosity, and enhances content relevance. Our empirical evaluations across diverse video question answering benchmarks demonstrate that i-SRT significantly outperforms prior arts. We are committed to opensourcing our code, models, and datasets to encourage further investigation.