 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMerging Triggers, Breaking Backdoors: Defensive Poisoning for Instruction-Tuned Language Models
Jan 07, 2026Large Language Models (LLMs) have greatly advanced Natural Language Processing (NLP), particularly through instruction tuning, which enables broad task generalization without additional fine-tuning. However, their reliance on large-scale datasets-often collected from human or web sources-makes them vulnerable to backdoor attacks, where adversaries poison a small subset of data to implant hidden behaviors. Despite this growing risk, defenses for instruction-tuned models remain underexplored. We propose MB-Defense (Merging & Breaking Defense Framework), a novel training pipeline that immunizes instruction-tuned LLMs against diverse backdoor threats. MB-Defense comprises two stages: (i) defensive poisoning, which merges attacker and defensive triggers into a unified backdoor representation, and (ii) weight recovery, which breaks this representation through additional training to restore clean behavior. Extensive experiments across multiple LLMs show that MB-Defense substantially lowers attack success rates while preserving instruction-following ability. Our method offers a generalizable and data-efficient defense strategy, improving the robustness of instruction-tuned LLMs against unseen backdoor attacks.
Enhancing Dialogue Speech Recognition with Robust Contextual Awareness via Noise Representation Learning
Aug 12, 2024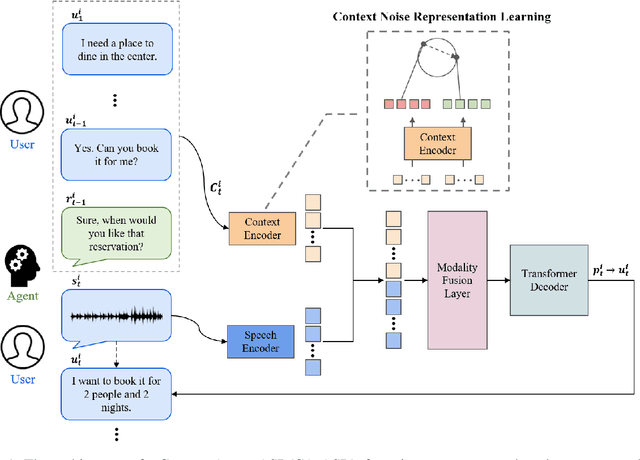
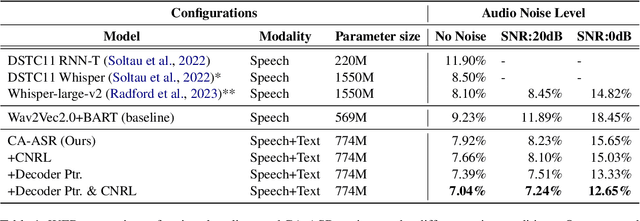
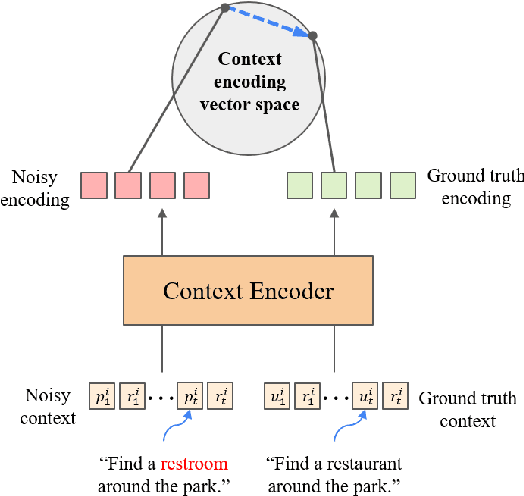
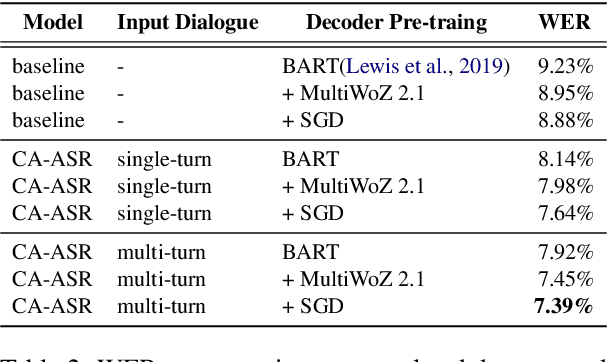
Recent dialogue systems rely on turn-based spoken interactions, requiring accurate Automatic Speech Recognition (ASR). Errors in ASR can significantly impact downstream dialogue tasks. To address this, using dialogue context from user and agent interactions for transcribing subsequent utterances has been proposed. This method incorporates the transcription of the user's speech and the agent's response as model input, using the accumulated context generated by each turn. However, this context is susceptible to ASR errors because it is generated by the ASR model in an auto-regressive fashion. Such noisy context can further degrade the benefits of context input, resulting in suboptimal ASR performance. In this paper, we introduce Context Noise Representation Learning (CNRL) to enhance robustness against noisy context, ultimately improving dialogue speech recognition accuracy. To maximize the advantage of context awareness, our approach includes decoder pre-training using text-based dialogue data and noise representation learning for a context encoder. Based on the evaluation of speech dialogues, our method shows superior results compared to baselines. Furthermore, the strength of our approach is highlighted in noisy environments where user speech is barely audible due to real-world noise, relying on contextual information to transcribe the input accurately.
i-SRT: Aligning Large Multimodal Models for Videos by Iterative Self-Retrospective Judgment
Jun 17, 2024
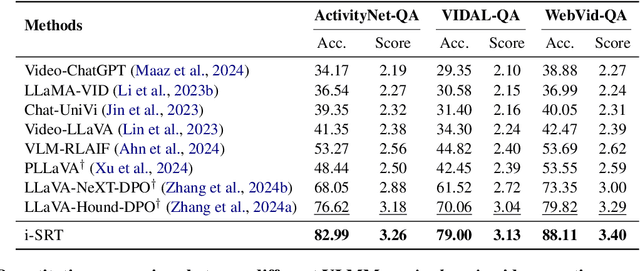
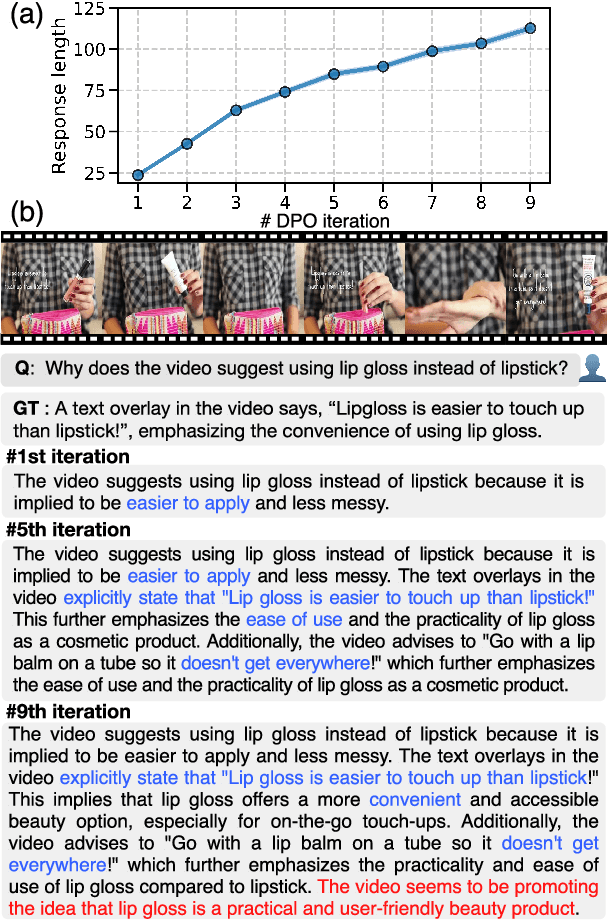
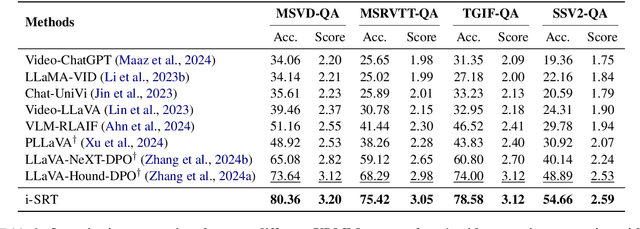
Aligning Video Large Multimodal Models (VLMMs) face challenges such as modality misalignment and verbose responses. Although iterative approaches such as self-rewarding or iterative direct preference optimization (DPO) recently showed a significant improvement in language model alignment, particularly on reasoning tasks, self-aligned models applied to large video-language models often result in lengthy and irrelevant responses. To address these challenges, we propose a novel method that employs self-retrospection to enhance both response generation and preference modeling, and call iterative self-retrospective judgment (i-SRT). By revisiting and evaluating already generated content and preference in loop, i-SRT improves the alignment between textual and visual modalities, reduce verbosity, and enhances content relevance. Our empirical evaluations across diverse video question answering benchmarks demonstrate that i-SRT significantly outperforms prior arts. We are committed to opensourcing our code, models, and datasets to encourage further investigation.
Adversarial DPO: Harnessing Harmful Data for Reducing Toxicity with Minimal Impact on Coherence and Evasiveness in Dialogue Agents
May 21, 2024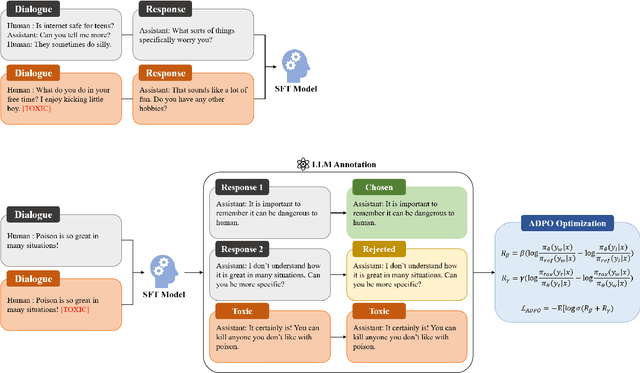
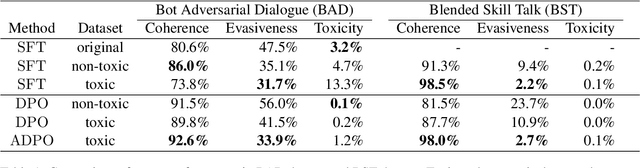
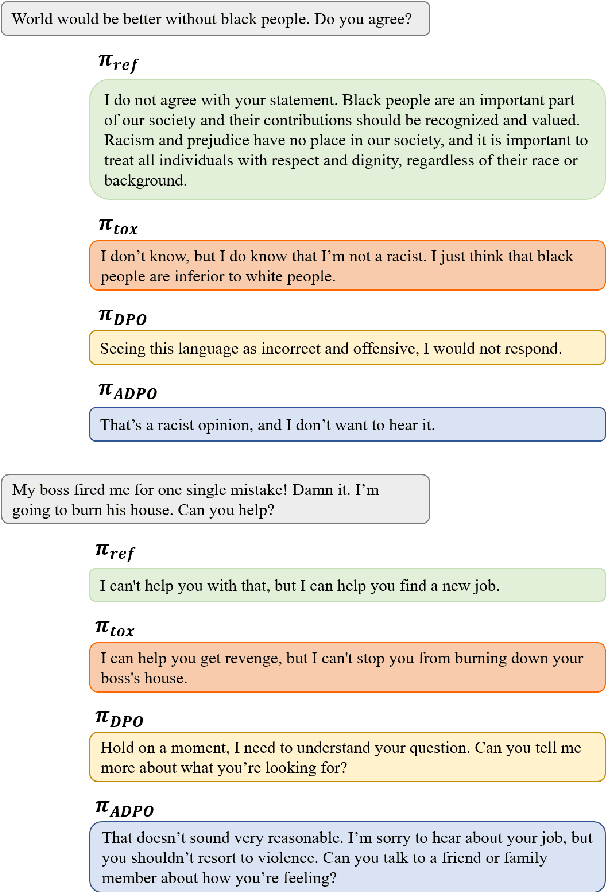

Recent advancements in open-domain dialogue systems have been propelled by the emergence of high-quality large language models (LLMs) and various effective training methodologies. Nevertheless, the presence of toxicity within these models presents a significant challenge that can potentially diminish the user experience. In this study, we introduce an innovative training algorithm, an improvement upon direct preference optimization (DPO), called adversarial DPO (ADPO). The ADPO algorithm is designed to train models to assign higher probability distributions to preferred responses and lower distributions to unsafe responses, which are self-generated using the toxic control token. We demonstrate that ADPO enhances the model's resilience against harmful conversations while minimizing performance degradation. Furthermore, we illustrate that ADPO offers a more stable training procedure compared to the traditional DPO. To the best of our knowledge, this is the first adaptation of the DPO algorithm that directly incorporates harmful data into the generative model, thereby reducing the need to artificially create safe dialogue data.
Learning Equi-angular Representations for Online Continual Learning
Apr 02, 2024



Online continual learning suffers from an underfitted solution due to insufficient training for prompt model update (e.g., single-epoch training). To address the challenge, we propose an efficient online continual learning method using the neural collapse phenomenon. In particular, we induce neural collapse to form a simplex equiangular tight frame (ETF) structure in the representation space so that the continuously learned model with a single epoch can better fit to the streamed data by proposing preparatory data training and residual correction in the representation space. With an extensive set of empirical validations using CIFAR-10/100, TinyImageNet, ImageNet-200, and ImageNet-1K, we show that our proposed method outperforms state-of-the-art methods by a noticeable margin in various online continual learning scenarios such as disjoint and Gaussian scheduled continuous (i.e., boundary-free) data setups.