 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEarly Decisions Matter: Proximity Bias and Initial Trajectory Shaping in Non-Autoregressive Diffusion Language Models
Apr 12, 2026Diffusion-based language models (dLLMs) have emerged as a promising alternative to autoregressive language models, offering the potential for parallel token generation and bidirectional context modeling. However, harnessing this flexibility for fully non-autoregressive decoding remains an open question, particularly for reasoning and planning tasks. In this work, we investigate non-autoregressive decoding in dLLMs by systematically analyzing its inference dynamics along the temporal axis. Specifically, we uncover an inherent failure mode in confidence-based non-autoregressive generation stemming from a strong proximity bias-the tendency for the denoising order to concentrate on spatially adjacent tokens. This local dependency leads to spatial error propagation, rendering the entire trajectory critically contingent on the initial unmasking position. Leveraging this insight, we present a minimal-intervention approach that guides early token selection, employing a lightweight planner and end-of-sequence temperature annealing. We thoroughly evaluate our method on various reasoning and planning tasks and observe substantial overall improvement over existing heuristic baselines without significant computational overhead.
Training-free Detection of AI-generated images via Cropping Robustness
Nov 18, 2025AI-generated image detection has become crucial with the rapid advancement of vision-generative models. Instead of training detectors tailored to specific datasets, we study a training-free approach leveraging self-supervised models without requiring prior data knowledge. These models, pre-trained with augmentations like RandomResizedCrop, learn to produce consistent representations across varying resolutions. Motivated by this, we propose WaRPAD, a training-free AI-generated image detection algorithm based on self-supervised models. Since neighborhood pixel differences in images are highly sensitive to resizing operations, WaRPAD first defines a base score function that quantifies the sensitivity of image embeddings to perturbations along high-frequency directions extracted via Haar wavelet decomposition. To simulate robustness against cropping augmentation, we rescale each image to a multiple of the models input size, divide it into smaller patches, and compute the base score for each patch. The final detection score is then obtained by averaging the scores across all patches. We validate WaRPAD on real datasets of diverse resolutions and domains, and images generated by 23 different generative models. Our method consistently achieves competitive performance and demonstrates strong robustness to test-time corruptions. Furthermore, as invariance to RandomResizedCrop is a common training scheme across self-supervised models, we show that WaRPAD is applicable across self-supervised models.
HFI: A unified framework for training-free detection and implicit watermarking of latent diffusion model generated images
Dec 30, 2024Dramatic advances in the quality of the latent diffusion models (LDMs) also led to the malicious use of AI-generated images. While current AI-generated image detection methods assume the availability of real/AI-generated images for training, this is practically limited given the vast expressibility of LDMs. This motivates the training-free detection setup where no related data are available in advance. The existing LDM-generated image detection method assumes that images generated by LDM are easier to reconstruct using an autoencoder than real images. However, we observe that this reconstruction distance is overfitted to background information, leading the current method to underperform in detecting images with simple backgrounds. To address this, we propose a novel method called HFI. Specifically, by viewing the autoencoder of LDM as a downsampling-upsampling kernel, HFI measures the extent of aliasing, a distortion of high-frequency information that appears in the reconstructed image. HFI is training-free, efficient, and consistently outperforms other training-free methods in detecting challenging images generated by various generative models. We also show that HFI can successfully detect the images generated from the specified LDM as a means of implicit watermarking. HFI outperforms the best baseline method while achieving magnitudes of
Diffusion based Semantic Outlier Generation via Nuisance Awareness for Out-of-Distribution Detection
Aug 27, 2024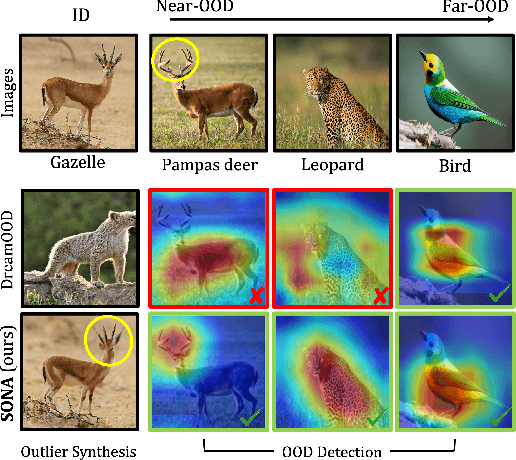
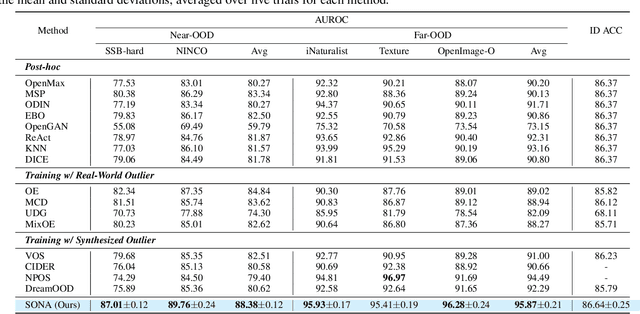
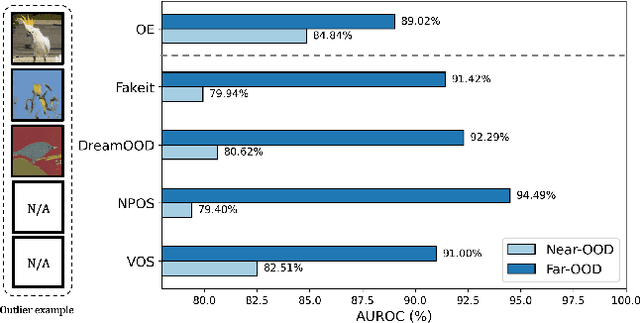
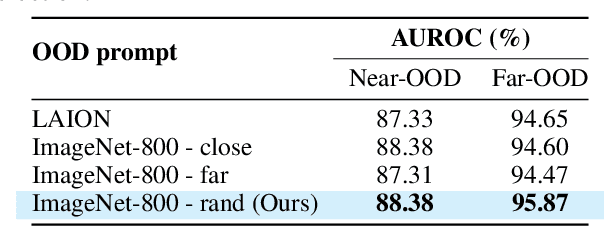
Out-of-distribution (OOD) detection, which determines whether a given sample is part of the in-distribution (ID), has recently shown promising results through training with synthetic OOD datasets. Nonetheless, existing methods often produce outliers that are considerably distant from the ID, showing limited efficacy for capturing subtle distinctions between ID and OOD. To address these issues, we propose a novel framework, Semantic Outlier generation via Nuisance Awareness (SONA), which notably produces challenging outliers by directly leveraging pixel-space ID samples through diffusion models. Our approach incorporates SONA guidance, providing separate control over semantic and nuisance regions of ID samples. Thereby, the generated outliers achieve two crucial properties: (i) they present explicit semantic-discrepant information, while (ii) maintaining various levels of nuisance resemblance with ID. Furthermore, the improved OOD detector training with SONA outliers facilitates learning with a focus on semantic distinctions. Extensive experiments demonstrate the effectiveness of our framework, achieving an impressive AUROC of 88% on near-OOD datasets, which surpasses the performance of baseline methods by a significant margin of approximately 6%.
Partial-Multivariate Model for Forecasting
Aug 19, 2024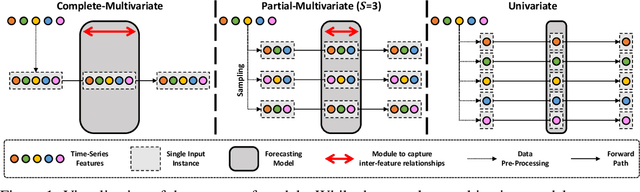
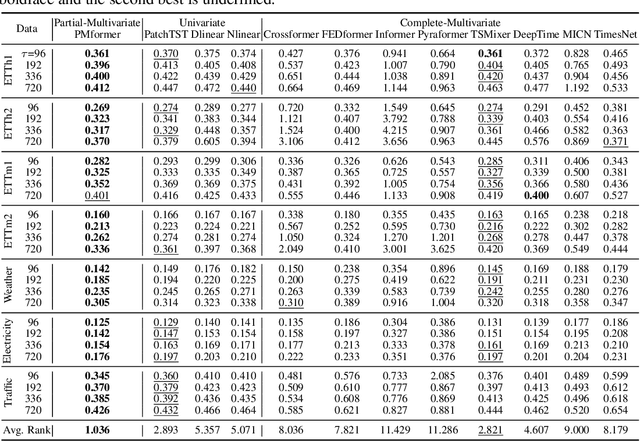

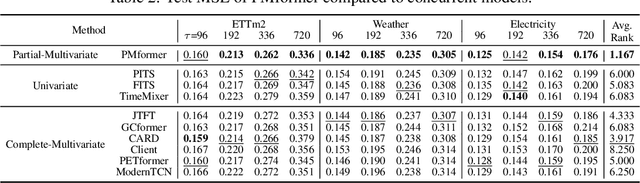
When solving forecasting problems including multiple time-series features, existing approaches often fall into two extreme categories, depending on whether to utilize inter-feature information: univariate and complete-multivariate models. Unlike univariate cases which ignore the information, complete-multivariate models compute relationships among a complete set of features. However, despite the potential advantage of leveraging the additional information, complete-multivariate models sometimes underperform univariate ones. Therefore, our research aims to explore a middle ground between these two by introducing what we term Partial-Multivariate models where a neural network captures only partial relationships, that is, dependencies within subsets of all features. To this end, we propose PMformer, a Transformer-based partial-multivariate model, with its training algorithm. We demonstrate that PMformer outperforms various univariate and complete-multivariate models, providing a theoretical rationale and empirical analysis for its superiority. Additionally, by proposing an inference technique for PMformer, the forecasting accuracy is further enhanced. Finally, we highlight other advantages of PMformer: efficiency and robustness under missing features.
Learning Equi-angular Representations for Online Continual Learning
Apr 02, 2024



Online continual learning suffers from an underfitted solution due to insufficient training for prompt model update (e.g., single-epoch training). To address the challenge, we propose an efficient online continual learning method using the neural collapse phenomenon. In particular, we induce neural collapse to form a simplex equiangular tight frame (ETF) structure in the representation space so that the continuously learned model with a single epoch can better fit to the streamed data by proposing preparatory data training and residual correction in the representation space. With an extensive set of empirical validations using CIFAR-10/100, TinyImageNet, ImageNet-200, and ImageNet-1K, we show that our proposed method outperforms state-of-the-art methods by a noticeable margin in various online continual learning scenarios such as disjoint and Gaussian scheduled continuous (i.e., boundary-free) data setups.
Projection Regret: Reducing Background Bias for Novelty Detection via Diffusion Models
Dec 05, 2023



Novelty detection is a fundamental task of machine learning which aims to detect abnormal ($\textit{i.e.}$ out-of-distribution (OOD)) samples. Since diffusion models have recently emerged as the de facto standard generative framework with surprising generation results, novelty detection via diffusion models has also gained much attention. Recent methods have mainly utilized the reconstruction property of in-distribution samples. However, they often suffer from detecting OOD samples that share similar background information to the in-distribution data. Based on our observation that diffusion models can \emph{project} any sample to an in-distribution sample with similar background information, we propose \emph{Projection Regret (PR)}, an efficient novelty detection method that mitigates the bias of non-semantic information. To be specific, PR computes the perceptual distance between the test image and its diffusion-based projection to detect abnormality. Since the perceptual distance often fails to capture semantic changes when the background information is dominant, we cancel out the background bias by comparing it against recursive projections. Extensive experiments demonstrate that PR outperforms the prior art of generative-model-based novelty detection methods by a significant margin.
Observation-Guided Diffusion Probabilistic Models
Oct 06, 2023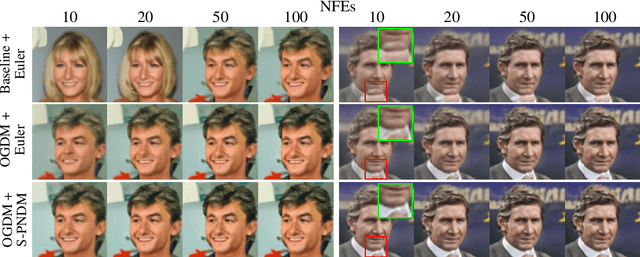
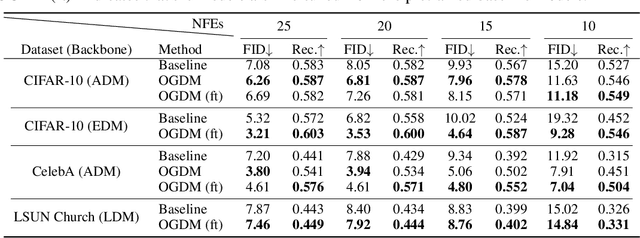
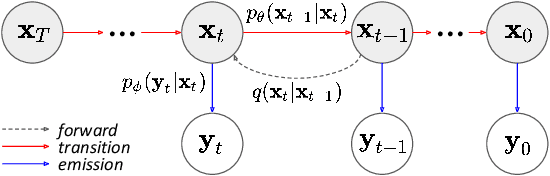

We propose a novel diffusion model called observation-guided diffusion probabilistic model (OGDM), which effectively addresses the trade-off between quality control and fast sampling. Our approach reestablishes the training objective by integrating the guidance of the observation process with the Markov chain in a principled way. This is achieved by introducing an additional loss term derived from the observation based on the conditional discriminator on noise level, which employs Bernoulli distribution indicating whether its input lies on the (noisy) real manifold or not. This strategy allows us to optimize the more accurate negative log-likelihood induced in the inference stage especially when the number of function evaluations is limited. The proposed training method is also advantageous even when incorporated only into the fine-tuning process, and it is compatible with various fast inference strategies since our method yields better denoising networks using the exactly same inference procedure without incurring extra computational cost. We demonstrate the effectiveness of the proposed training algorithm using diverse inference methods on strong diffusion model baselines.
Transferring Pre-trained Multimodal Representations with Cross-modal Similarity Matching
Jan 07, 2023



Despite surprising performance on zero-shot transfer, pre-training a large-scale multimodal model is often prohibitive as it requires a huge amount of data and computing resources. In this paper, we propose a method (BeamCLIP) that can effectively transfer the representations of a large pre-trained multimodal model (CLIP-ViT) into a small target model (e.g., ResNet-18). For unsupervised transfer, we introduce cross-modal similarity matching (CSM) that enables a student model to learn the representations of a teacher model by matching the relative similarity distribution across text prompt embeddings. To better encode the text prompts, we design context-based prompt augmentation (CPA) that can alleviate the lexical ambiguity of input text prompts. Our experiments show that unsupervised representation transfer of a pre-trained vision-language model enables a small ResNet-18 to achieve a better ImageNet-1K top-1 linear probe accuracy (66.2%) than vision-only self-supervised learning (SSL) methods (e.g., SimCLR: 51.8%, SwAV: 63.7%), while closing the gap with supervised learning (69.8%).
Unsupervised Visual Representation Learning via Mutual Information Regularized Assignment
Nov 04, 2022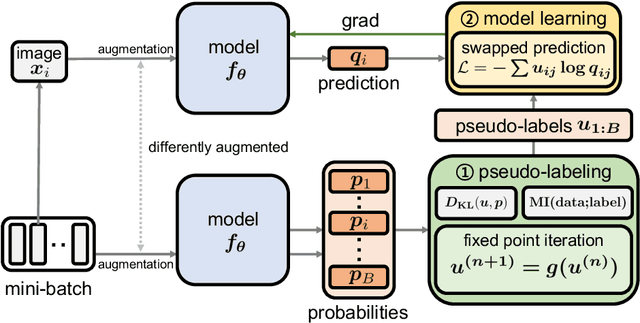
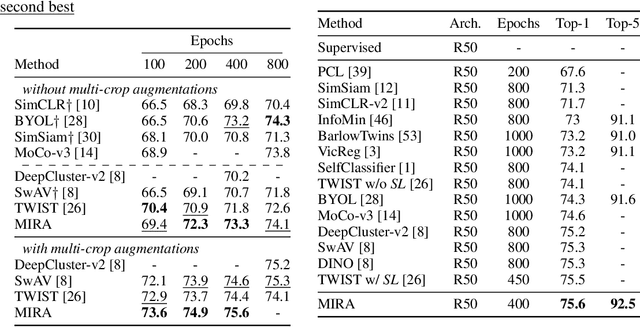
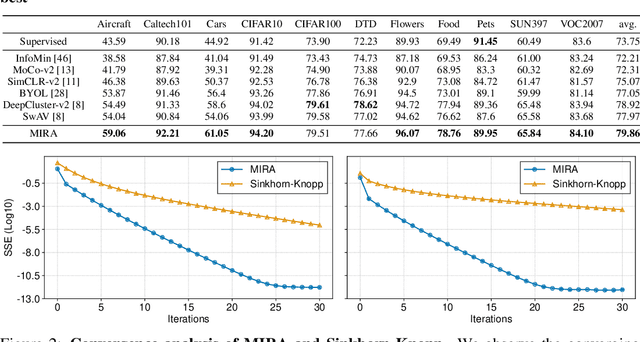

This paper proposes Mutual Information Regularized Assignment (MIRA), a pseudo-labeling algorithm for unsupervised representation learning inspired by information maximization. We formulate online pseudo-labeling as an optimization problem to find pseudo-labels that maximize the mutual information between the label and data while being close to a given model probability. We derive a fixed-point iteration method and prove its convergence to the optimal solution. In contrast to baselines, MIRA combined with pseudo-label prediction enables a simple yet effective clustering-based representation learning without incorporating extra training techniques or artificial constraints such as sampling strategy, equipartition constraints, etc. With relatively small training epochs, representation learned by MIRA achieves state-of-the-art performance on various downstream tasks, including the linear/k-NN evaluation and transfer learning. Especially, with only 400 epochs, our method applied to ImageNet dataset with ResNet-50 architecture achieves 75.6% linear evaluation accuracy.