 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafeDPO: A Simple Approach to Direct Preference Optimization with Enhanced Safety
May 26, 2025As Large Language Models (LLMs) continue to advance and find applications across a growing number of fields, ensuring the safety of LLMs has become increasingly critical. To address safety concerns, recent studies have proposed integrating safety constraints into Reinforcement Learning from Human Feedback (RLHF). However, these approaches tend to be complex, as they encompass complicated procedures in RLHF along with additional steps required by the safety constraints. Inspired by Direct Preference Optimization (DPO), we introduce a new algorithm called SafeDPO, which is designed to directly optimize the safety alignment objective in a single stage of policy learning, without requiring relaxation. SafeDPO introduces only one additional hyperparameter to further enhance safety and requires only minor modifications to standard DPO. As a result, it eliminates the need to fit separate reward and cost models or to sample from the language model during fine-tuning, while still enhancing the safety of LLMs. Finally, we demonstrate that SafeDPO achieves competitive performance compared to state-of-the-art safety alignment algorithms, both in terms of aligning with human preferences and improving safety.
ContraCluster: Learning to Classify without Labels by Contrastive Self-Supervision and Prototype-Based Semi-Supervision
Apr 19, 2023
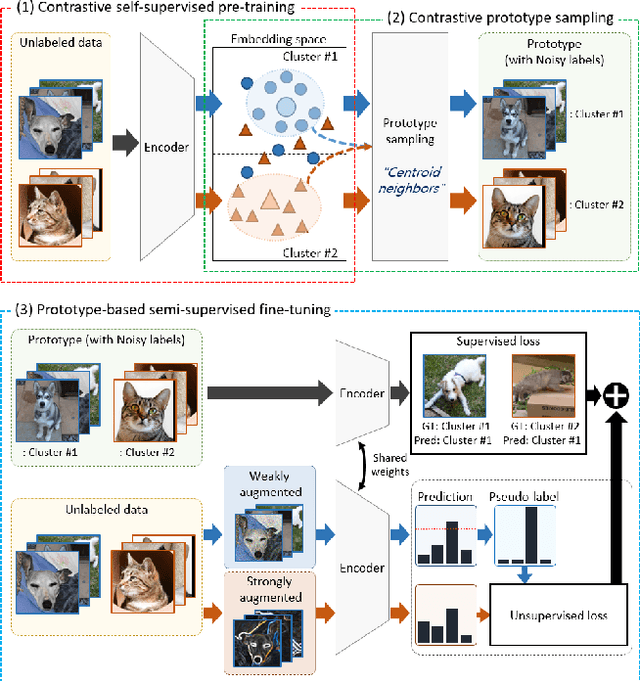
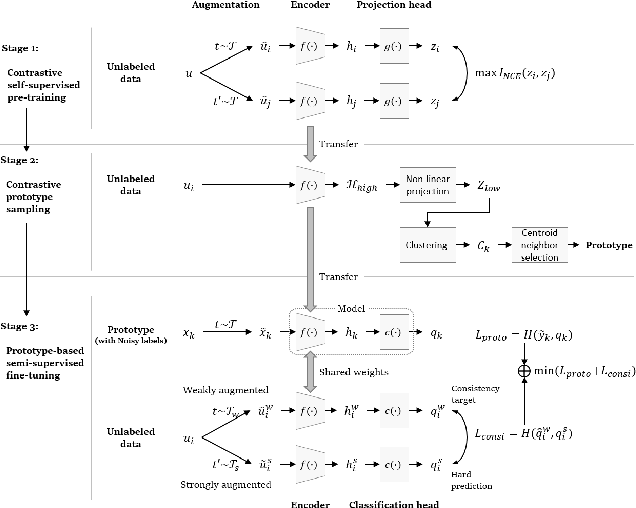
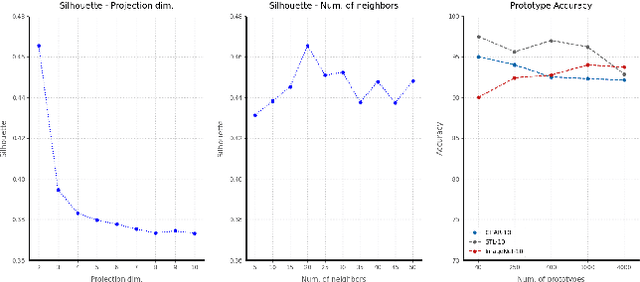
The recent advances in representation learning inspire us to take on the challenging problem of unsupervised image classification tasks in a principled way. We propose ContraCluster, an unsupervised image classification method that combines clustering with the power of contrastive self-supervised learning. ContraCluster consists of three stages: (1) contrastive self-supervised pre-training (CPT), (2) contrastive prototype sampling (CPS), and (3) prototype-based semi-supervised fine-tuning (PB-SFT). CPS can select highly accurate, categorically prototypical images in an embedding space learned by contrastive learning. We use sampled prototypes as noisy labeled data to perform semi-supervised fine-tuning (PB-SFT), leveraging small prototypes and large unlabeled data to further enhance the accuracy. We demonstrate empirically that ContraCluster achieves new state-of-the-art results for standard benchmark datasets including CIFAR-10, STL-10, and ImageNet-10. For example, ContraCluster achieves about 90.8% accuracy for CIFAR-10, which outperforms DAC (52.2%), IIC (61.7%), and SCAN (87.6%) by a large margin. Without any labels, ContraCluster can achieve a 90.8% accuracy that is comparable to 95.8% by the best supervised counterpart.
* Accepted at ICPR 2022
Transferring Pre-trained Multimodal Representations with Cross-modal Similarity Matching
Jan 07, 2023



Despite surprising performance on zero-shot transfer, pre-training a large-scale multimodal model is often prohibitive as it requires a huge amount of data and computing resources. In this paper, we propose a method (BeamCLIP) that can effectively transfer the representations of a large pre-trained multimodal model (CLIP-ViT) into a small target model (e.g., ResNet-18). For unsupervised transfer, we introduce cross-modal similarity matching (CSM) that enables a student model to learn the representations of a teacher model by matching the relative similarity distribution across text prompt embeddings. To better encode the text prompts, we design context-based prompt augmentation (CPA) that can alleviate the lexical ambiguity of input text prompts. Our experiments show that unsupervised representation transfer of a pre-trained vision-language model enables a small ResNet-18 to achieve a better ImageNet-1K top-1 linear probe accuracy (66.2%) than vision-only self-supervised learning (SSL) methods (e.g., SimCLR: 51.8%, SwAV: 63.7%), while closing the gap with supervised learning (69.8%).
SelfMatch: Combining Contrastive Self-Supervision and Consistency for Semi-Supervised Learning
Jan 16, 2021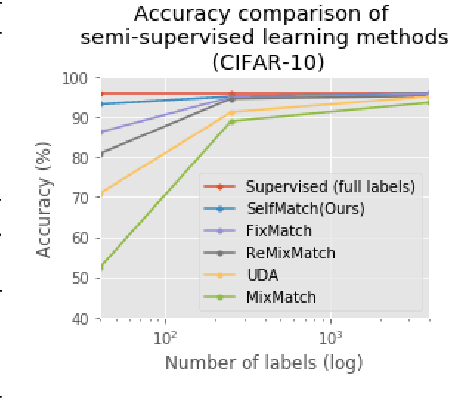
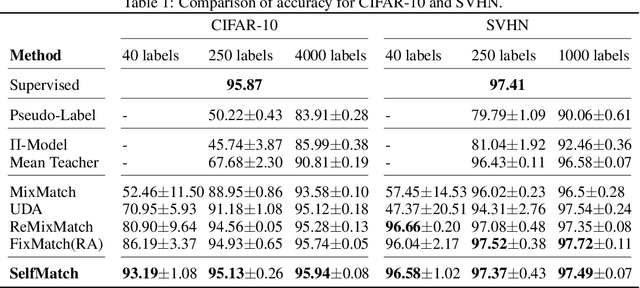
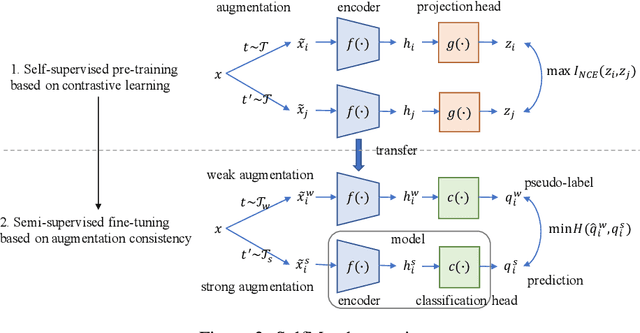

This paper introduces SelfMatch, a semi-supervised learning method that combines the power of contrastive self-supervised learning and consistency regularization. SelfMatch consists of two stages: (1) self-supervised pre-training based on contrastive learning and (2) semi-supervised fine-tuning based on augmentation consistency regularization. We empirically demonstrate that SelfMatch achieves the state-of-the-art results on standard benchmark datasets such as CIFAR-10 and SVHN. For example, for CIFAR-10 with 40 labeled examples, SelfMatch achieves 93.19% accuracy that outperforms the strong previous methods such as MixMatch (52.46%), UDA (70.95%), ReMixMatch (80.9%), and FixMatch (86.19%). We note that SelfMatch can close the gap between supervised learning (95.87%) and semi-supervised learning (93.19%) by using only a few labels for each class.
POMO: Policy Optimization with Multiple Optima for Reinforcement Learning
Oct 30, 2020

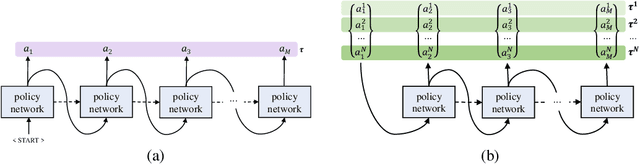
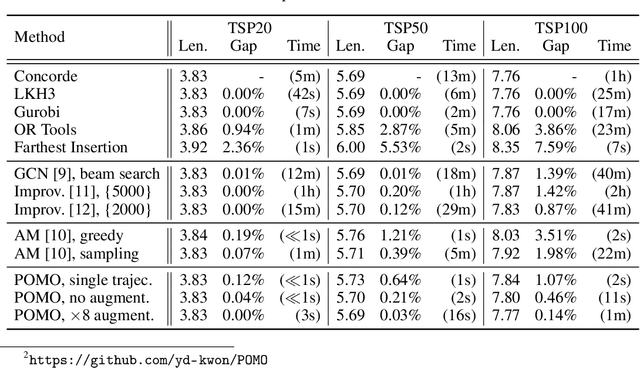
In neural combinatorial optimization (CO), reinforcement learning (RL) can turn a deep neural net into a fast, powerful heuristic solver of NP-hard problems. This approach has a great potential in practical applications because it allows near-optimal solutions to be found without expert guides armed with substantial domain knowledge. We introduce Policy Optimization with Multiple Optima (POMO), an end-to-end approach for building such a heuristic solver. POMO is applicable to a wide range of CO problems. It is designed to exploit the symmetries in the representation of a CO solution. POMO uses a modified REINFORCE algorithm that forces diverse rollouts towards all optimal solutions. Empirically, the low-variance baseline of POMO makes RL training fast and stable, and it is more resistant to local minima compared to previous approaches. We also introduce a new augmentation-based inference method, which accompanies POMO nicely. We demonstrate the effectiveness of POMO by solving three popular NP-hard problems, namely, traveling salesman (TSP), capacitated vehicle routing (CVRP), and 0-1 knapsack (KP). For all three, our solver based on POMO shows a significant improvement in performance over all recent learned heuristics. In particular, we achieve the optimality gap of 0.14% with TSP100 while reducing inference time by more than an order of magnitude.
VaB-AL: Incorporating Class Imbalance and Difficulty with Variational Bayes for Active Learning
Mar 25, 2020
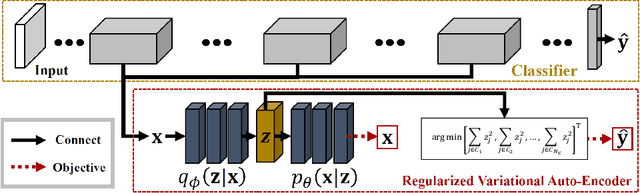
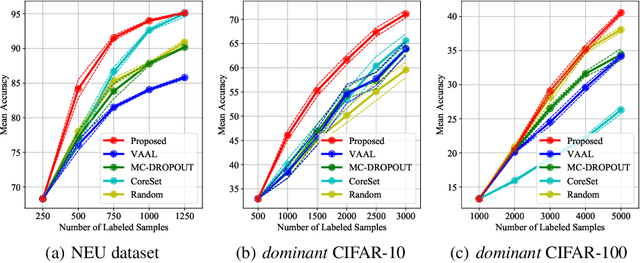

Active Learning for discriminative models has largely been studied with the focus on individual samples, with less emphasis on how classes are distributed or which classes are hard to deal with. In this work, we show that this is harmful. We propose a method based on the Bayes' rule, that can naturally incorporate class imbalance into the Active Learning framework. We derive that three terms should be considered together when estimating the probability of a classifier making a mistake for a given sample; i) probability of mislabelling a class, ii) likelihood of the data given a predicted class, and iii) the prior probability on the abundance of a predicted class. Implementing these terms requires a generative model and an intractable likelihood estimation. Therefore, we train a Variational Auto Encoder (VAE) for this purpose. To further tie the VAE with the classifier and facilitate VAE training, we use the classifiers' deep feature representations as input to the VAE. By considering all three probabilities, among them especially the data imbalance, we can substantially improve the potential of existing methods under limited data budget. We show that our method can be applied to classification tasks on multiple different datasets -- including one that is a real-world dataset with heavy data imbalance -- significantly outperforming the state of the art.
DefogGAN: Predicting Hidden Information in the StarCraft Fog of War with Generative Adversarial Nets
Mar 15, 2020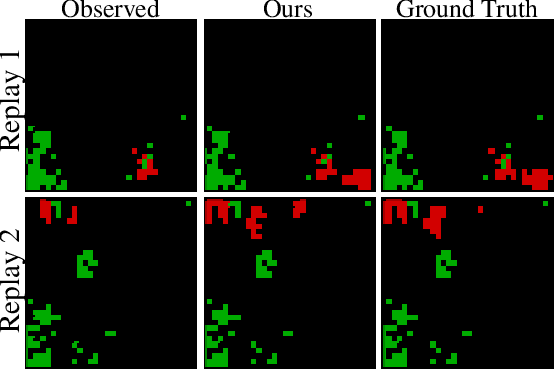
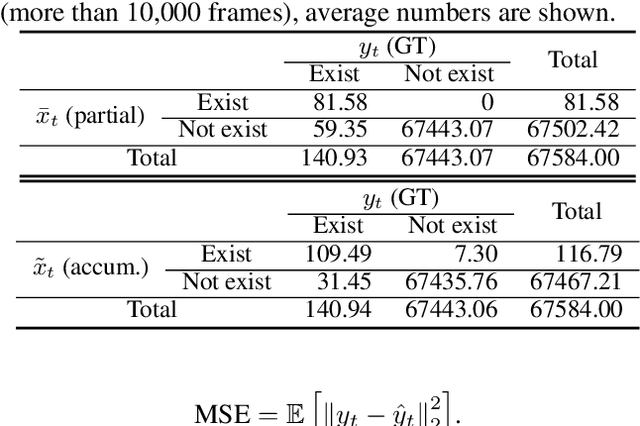
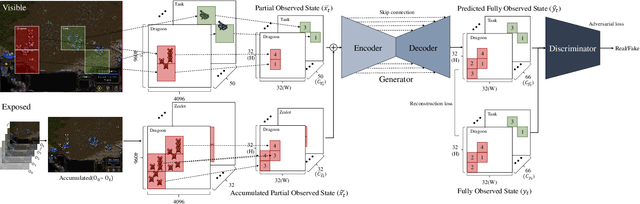
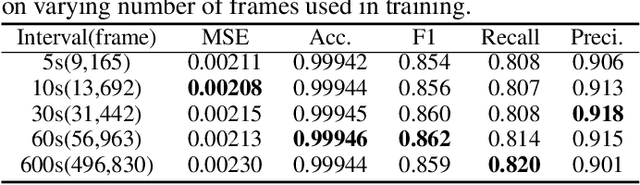
We propose DefogGAN, a generative approach to the problem of inferring state information hidden in the fog of war for real-time strategy (RTS) games. Given a partially observed state, DefogGAN generates defogged images of a game as predictive information. Such information can lead to create a strategic agent for the game. DefogGAN is a conditional GAN variant featuring pyramidal reconstruction loss to optimize on multiple feature resolution scales.We have validated DefogGAN empirically using a large dataset of professional StarCraft replays. Our results indicate that DefogGAN can predict the enemy buildings and combat units as accurately as professional players do and achieves a superior performance among state-of-the-art defoggers.
Unsupervised Visual Attribute Transfer with Reconfigurable Generative Adversarial Networks
Jul 31, 2017



Learning to transfer visual attributes requires supervision dataset. Corresponding images with varying attribute values with the same identity are required for learning the transfer function. This largely limits their applications, because capturing them is often a difficult task. To address the issue, we propose an unsupervised method to learn to transfer visual attribute. The proposed method can learn the transfer function without any corresponding images. Inspecting visualization results from various unsupervised attribute transfer tasks, we verify the effectiveness of the proposed method.