 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShuffle & Divide: Contrastive Learning for Long Text
Apr 19, 2023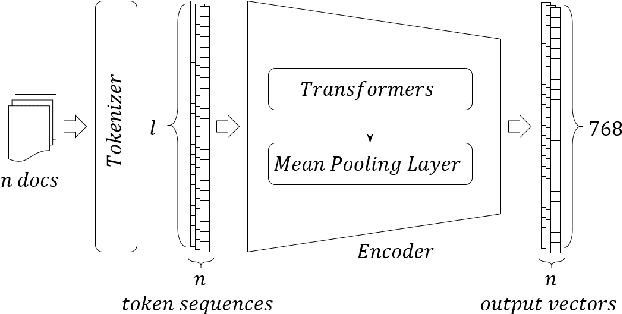

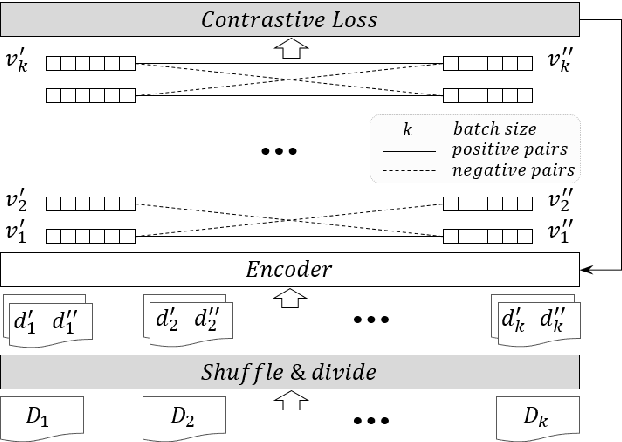
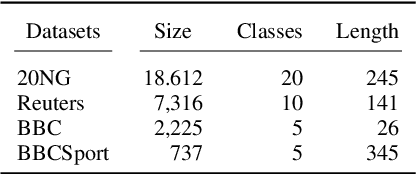
We propose a self-supervised learning method for long text documents based on contrastive learning. A key to our method is Shuffle and Divide (SaD), a simple text augmentation algorithm that sets up a pretext task required for contrastive updates to BERT-based document embedding. SaD splits a document into two sub-documents containing randomly shuffled words in the entire documents. The sub-documents are considered positive examples, leaving all other documents in the corpus as negatives. After SaD, we repeat the contrastive update and clustering phases until convergence. It is naturally a time-consuming, cumbersome task to label text documents, and our method can help alleviate human efforts, which are most expensive resources in AI. We have empirically evaluated our method by performing unsupervised text classification on the 20 Newsgroups, Reuters-21578, BBC, and BBCSport datasets. In particular, our method pushes the current state-of-the-art, SS-SB-MT, on 20 Newsgroups by 20.94% in accuracy. We also achieve the state-of-the-art performance on Reuters-21578 and exceptionally-high accuracy performances (over 95%) for unsupervised classification on the BBC and BBCSport datasets.
* Accepted at ICPR 2022
ContraCluster: Learning to Classify without Labels by Contrastive Self-Supervision and Prototype-Based Semi-Supervision
Apr 19, 2023
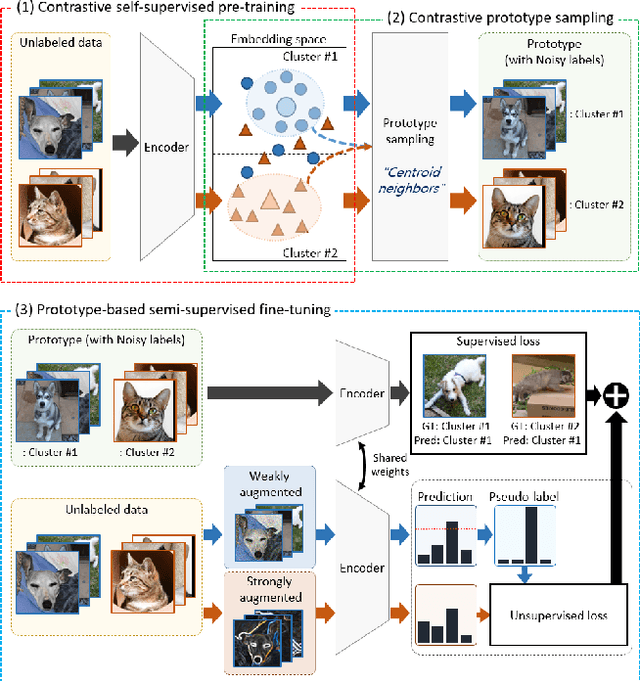
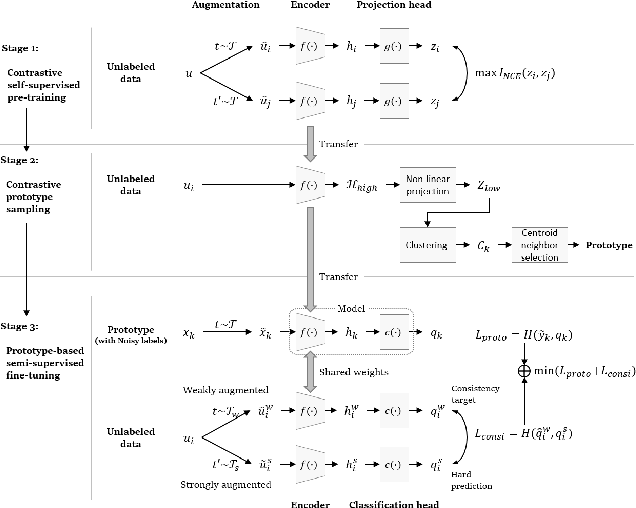
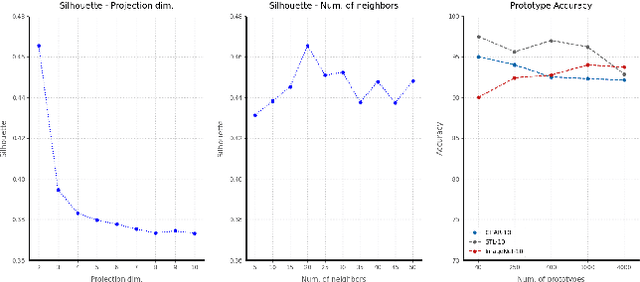
The recent advances in representation learning inspire us to take on the challenging problem of unsupervised image classification tasks in a principled way. We propose ContraCluster, an unsupervised image classification method that combines clustering with the power of contrastive self-supervised learning. ContraCluster consists of three stages: (1) contrastive self-supervised pre-training (CPT), (2) contrastive prototype sampling (CPS), and (3) prototype-based semi-supervised fine-tuning (PB-SFT). CPS can select highly accurate, categorically prototypical images in an embedding space learned by contrastive learning. We use sampled prototypes as noisy labeled data to perform semi-supervised fine-tuning (PB-SFT), leveraging small prototypes and large unlabeled data to further enhance the accuracy. We demonstrate empirically that ContraCluster achieves new state-of-the-art results for standard benchmark datasets including CIFAR-10, STL-10, and ImageNet-10. For example, ContraCluster achieves about 90.8% accuracy for CIFAR-10, which outperforms DAC (52.2%), IIC (61.7%), and SCAN (87.6%) by a large margin. Without any labels, ContraCluster can achieve a 90.8% accuracy that is comparable to 95.8% by the best supervised counterpart.
* Accepted at ICPR 2022
Finding essential parts of the brain in rs-fMRI can improve diagnosing ADHD by Deep Learning
Aug 14, 2021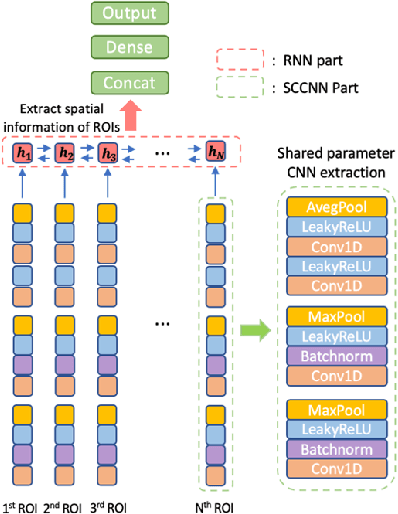

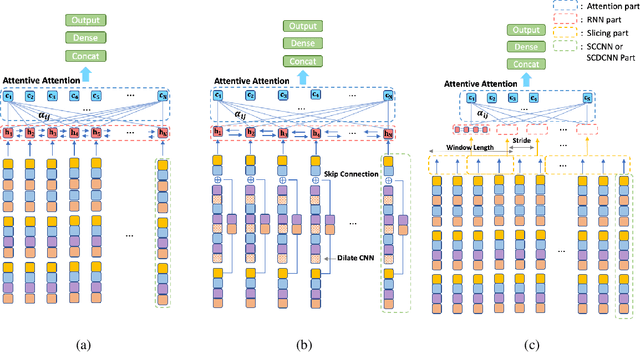

Attention Deficit\Hyperactivity Disorder(ADHD) is considered a very common psychiatric disorder, but it is difficult to establish an accurate diagnostic method for ADHD. Recently, with the development of computing resources and machine learning methods, studies have been conducted to classify ADHD using resting-state functional magnetic resonance(rsfMRI) imaging data. However, most of them utilized all areas of the brain for training the models. In this study, as a different way from this approach, we conducted a study to classify ADHD by selecting areas that are essential for using a deep learning model. For the experiment, rsfMRI data provided by ADHD 200 global competition was used. To obtain an integrated result from the multiple sites, each region of the brain was evaluated with Leave one site out cross-validation. As a result, when we only used 15 important region of interest(ROIs) for training, an accuracy of 70.6% was obtained, significantly exceeding the existing results of 68.6% from all ROIs. In addition, to explore the new structure based on SCCNN-RNN, we performed the same experiment with three modified models: (1) Separate Channel CNN RNN with Attention (ASCRNN), (2) Separate Channel dilate CNN RNN with Attention (ASDRNN), (3) Separate Channel CNN slicing RNN with Attention (ASSRNN). As a result, the ASSRNN model provided a high accuracy of 70.46% when training with only 13 important region of interest (ROI). These results show that finding and using the crucial parts of the brain in diagnosing ADHD by Deep Learning can get better results than using all areas.