 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCorrecting Negative Bias in Large Language Models through Negative Attention Score Alignment
Jul 31, 2024



A binary decision task, like yes-no questions or answer verification, reflects a significant real-world scenario such as where users look for confirmation about the correctness of their decisions on specific issues. In this work, we observe that language models exhibit a negative bias in the binary decisions of complex reasoning tasks. Based on our observations and the rationale about attention-based model dynamics, we propose a negative attention score (NAS) to systematically and quantitatively formulate negative bias. Based on NAS, we identify attention heads that attend to negative tokens provided in the instructions as answer candidate of binary decisions, regardless of the question in the prompt, and validate their association with the negative bias. Additionally, we propose the negative attention score alignment (NASA) method, which is a parameter-efficient fine-tuning technique to address the extracted negatively biased attention heads. Experimental results from various domains of reasoning tasks and large model search space demonstrate that NASA significantly reduces the gap between precision and recall caused by negative bias while preserving their generalization abilities. Our codes are available at \url{https://github.com/ysw1021/NASA}.
Entity-level Factual Adaptiveness of Fine-tuning based Abstractive Summarization Models
Feb 23, 2024
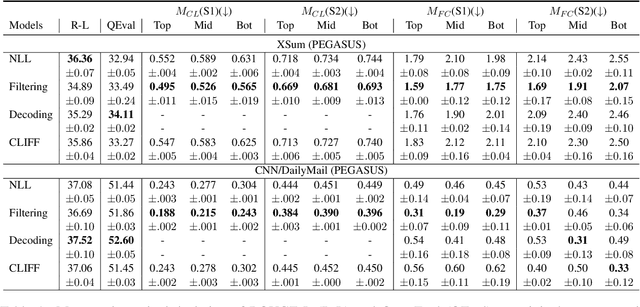
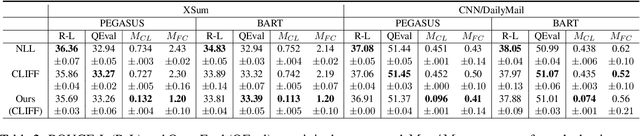
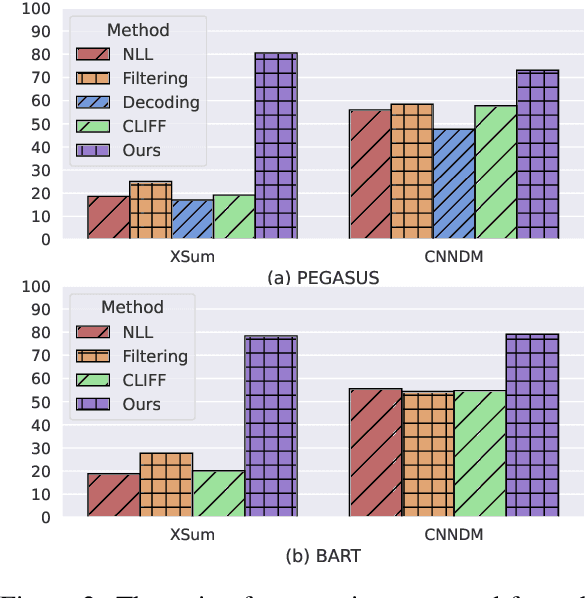
Abstractive summarization models often generate factually inconsistent content particularly when the parametric knowledge of the model conflicts with the knowledge in the input document. In this paper, we analyze the robustness of fine-tuning based summarization models to the knowledge conflict, which we call factual adaptiveness. We utilize pre-trained language models to construct evaluation sets and find that factual adaptiveness is not strongly correlated with factual consistency on original datasets. Furthermore, we introduce a controllable counterfactual data augmentation method where the degree of knowledge conflict within the augmented data can be adjustable. Our experimental results on two pre-trained language models (PEGASUS and BART) and two fine-tuning datasets (XSum and CNN/DailyMail) demonstrate that our method enhances factual adaptiveness while achieving factual consistency on original datasets on par with the contrastive learning baseline.
Is Cross-modal Information Retrieval Possible without Training?
Apr 20, 2023Encoded representations from a pretrained deep learning model (e.g., BERT text embeddings, penultimate CNN layer activations of an image) convey a rich set of features beneficial for information retrieval. Embeddings for a particular modality of data occupy a high-dimensional space of its own, but it can be semantically aligned to another by a simple mapping without training a deep neural net. In this paper, we take a simple mapping computed from the least squares and singular value decomposition (SVD) for a solution to the Procrustes problem to serve a means to cross-modal information retrieval. That is, given information in one modality such as text, the mapping helps us locate a semantically equivalent data item in another modality such as image. Using off-the-shelf pretrained deep learning models, we have experimented the aforementioned simple cross-modal mappings in tasks of text-to-image and image-to-text retrieval. Despite simplicity, our mappings perform reasonably well reaching the highest accuracy of 77% on recall@10, which is comparable to those requiring costly neural net training and fine-tuning. We have improved the simple mappings by contrastive learning on the pretrained models. Contrastive learning can be thought as properly biasing the pretrained encoders to enhance the cross-modal mapping quality. We have further improved the performance by multilayer perceptron with gating (gMLP), a simple neural architecture.
ContraCluster: Learning to Classify without Labels by Contrastive Self-Supervision and Prototype-Based Semi-Supervision
Apr 19, 2023
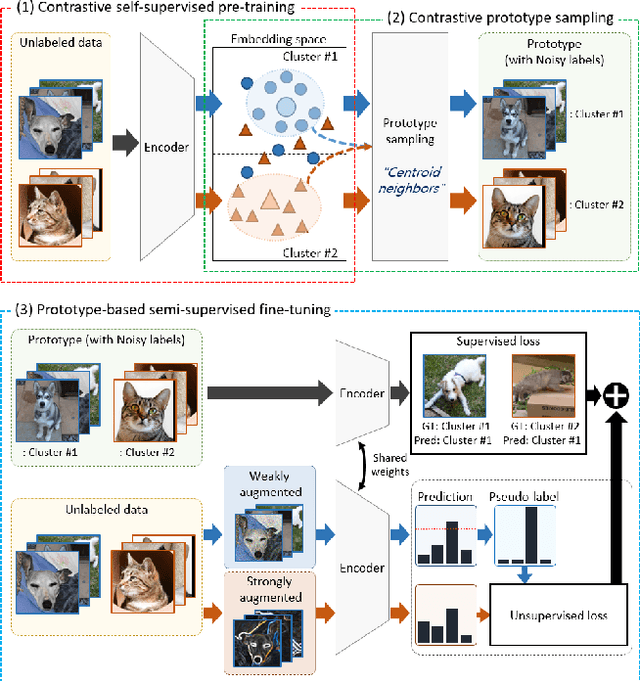
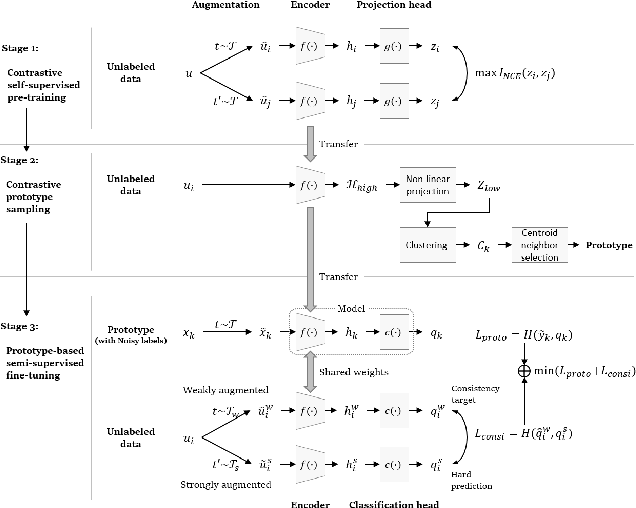
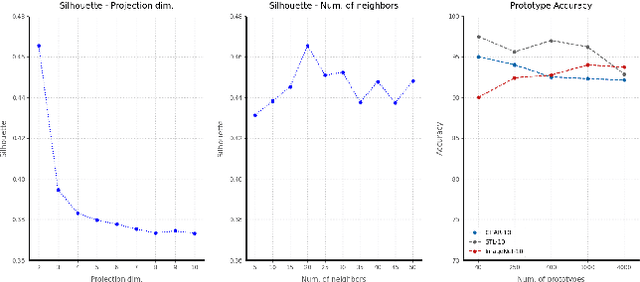
The recent advances in representation learning inspire us to take on the challenging problem of unsupervised image classification tasks in a principled way. We propose ContraCluster, an unsupervised image classification method that combines clustering with the power of contrastive self-supervised learning. ContraCluster consists of three stages: (1) contrastive self-supervised pre-training (CPT), (2) contrastive prototype sampling (CPS), and (3) prototype-based semi-supervised fine-tuning (PB-SFT). CPS can select highly accurate, categorically prototypical images in an embedding space learned by contrastive learning. We use sampled prototypes as noisy labeled data to perform semi-supervised fine-tuning (PB-SFT), leveraging small prototypes and large unlabeled data to further enhance the accuracy. We demonstrate empirically that ContraCluster achieves new state-of-the-art results for standard benchmark datasets including CIFAR-10, STL-10, and ImageNet-10. For example, ContraCluster achieves about 90.8% accuracy for CIFAR-10, which outperforms DAC (52.2%), IIC (61.7%), and SCAN (87.6%) by a large margin. Without any labels, ContraCluster can achieve a 90.8% accuracy that is comparable to 95.8% by the best supervised counterpart.
* Accepted at ICPR 2022
Shuffle & Divide: Contrastive Learning for Long Text
Apr 19, 2023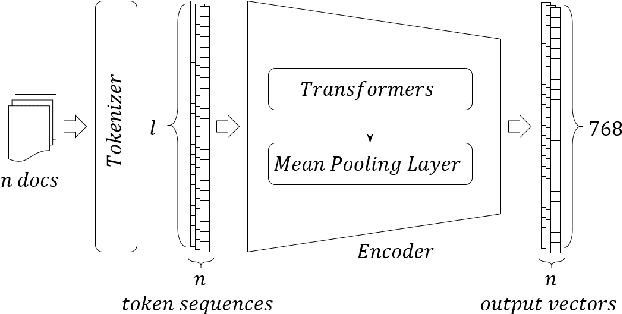

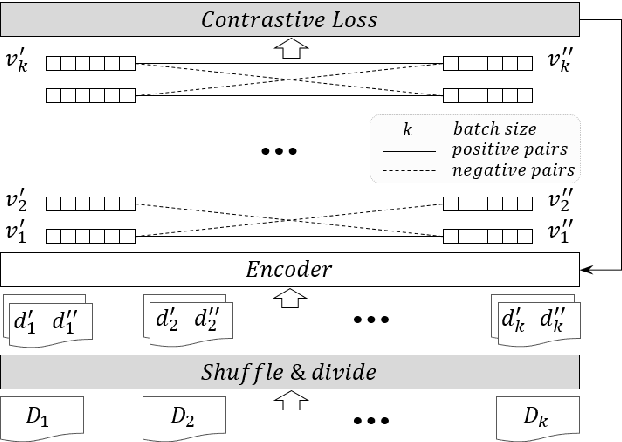
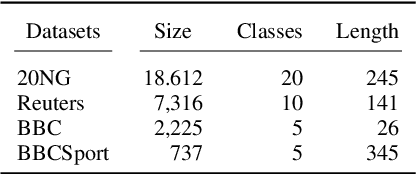
We propose a self-supervised learning method for long text documents based on contrastive learning. A key to our method is Shuffle and Divide (SaD), a simple text augmentation algorithm that sets up a pretext task required for contrastive updates to BERT-based document embedding. SaD splits a document into two sub-documents containing randomly shuffled words in the entire documents. The sub-documents are considered positive examples, leaving all other documents in the corpus as negatives. After SaD, we repeat the contrastive update and clustering phases until convergence. It is naturally a time-consuming, cumbersome task to label text documents, and our method can help alleviate human efforts, which are most expensive resources in AI. We have empirically evaluated our method by performing unsupervised text classification on the 20 Newsgroups, Reuters-21578, BBC, and BBCSport datasets. In particular, our method pushes the current state-of-the-art, SS-SB-MT, on 20 Newsgroups by 20.94% in accuracy. We also achieve the state-of-the-art performance on Reuters-21578 and exceptionally-high accuracy performances (over 95%) for unsupervised classification on the BBC and BBCSport datasets.
* Accepted at ICPR 2022
BiHPF: Bilateral High-Pass Filters for Robust Deepfake Detection
Aug 16, 2021

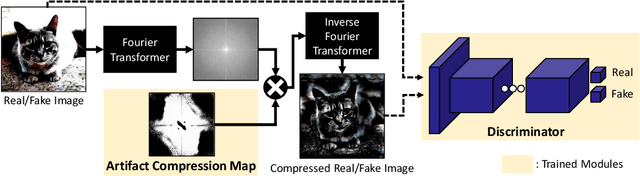
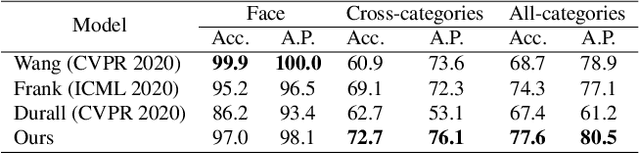
The advancement in numerous generative models has a two-fold effect: a simple and easy generation of realistic synthesized images, but also an increased risk of malicious abuse of those images. Thus, it is important to develop a generalized detector for synthesized images of any GAN model or object category, including those unseen during the training phase. However, the conventional methods heavily depend on the training settings, which cause a dramatic decline in performance when tested with unknown domains. To resolve the issue and obtain a generalized detection ability, we propose Bilateral High-Pass Filters (BiHPF), which amplify the effect of the frequency-level artifacts that are known to be found in the synthesized images of generative models. Numerous experimental results validate that our method outperforms other state-of-the-art methods, even when tested with unseen domains.
KoreALBERT: Pretraining a Lite BERT Model for Korean Language Understanding
Jan 27, 2021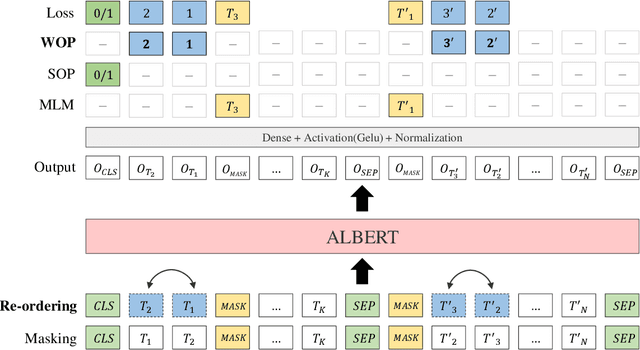
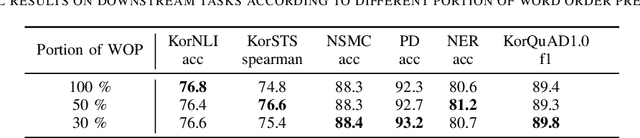

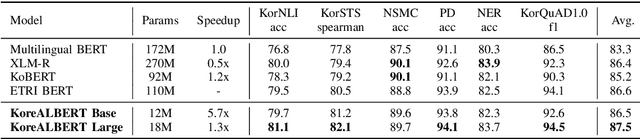
A Lite BERT (ALBERT) has been introduced to scale up deep bidirectional representation learning for natural languages. Due to the lack of pretrained ALBERT models for Korean language, the best available practice is the multilingual model or resorting back to the any other BERT-based model. In this paper, we develop and pretrain KoreALBERT, a monolingual ALBERT model specifically for Korean language understanding. We introduce a new training objective, namely Word Order Prediction (WOP), and use alongside the existing MLM and SOP criteria to the same architecture and model parameters. Despite having significantly fewer model parameters (thus, quicker to train), our pretrained KoreALBERT outperforms its BERT counterpart on 6 different NLU tasks. Consistent with the empirical results in English by Lan et al., KoreALBERT seems to improve downstream task performance involving multi-sentence encoding for Korean language. The pretrained KoreALBERT is publicly available to encourage research and application development for Korean NLP.
Analyzing Zero-shot Cross-lingual Transfer in Supervised NLP Tasks
Jan 26, 2021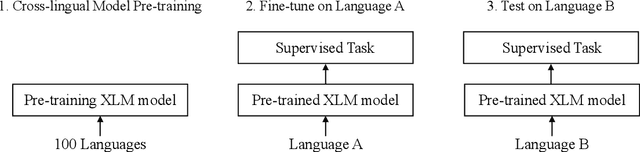
In zero-shot cross-lingual transfer, a supervised NLP task trained on a corpus in one language is directly applicable to another language without any additional training. A source of cross-lingual transfer can be as straightforward as lexical overlap between languages (e.g., use of the same scripts, shared subwords) that naturally forces text embeddings to occupy a similar representation space. Recently introduced cross-lingual language model (XLM) pretraining brings out neural parameter sharing in Transformer-style networks as the most important factor for the transfer. In this paper, we aim to validate the hypothetically strong cross-lingual transfer properties induced by XLM pretraining. Particularly, we take XLM-RoBERTa (XLMR) in our experiments that extend semantic textual similarity (STS), SQuAD and KorQuAD for machine reading comprehension, sentiment analysis, and alignment of sentence embeddings under various cross-lingual settings. Our results indicate that the presence of cross-lingual transfer is most pronounced in STS, sentiment analysis the next, and MRC the last. That is, the complexity of a downstream task softens the degree of crosslingual transfer. All of our results are empirically observed and measured, and we make our code and data publicly available.
Evaluation of BERT and ALBERT Sentence Embedding Performance on Downstream NLP Tasks
Jan 26, 2021



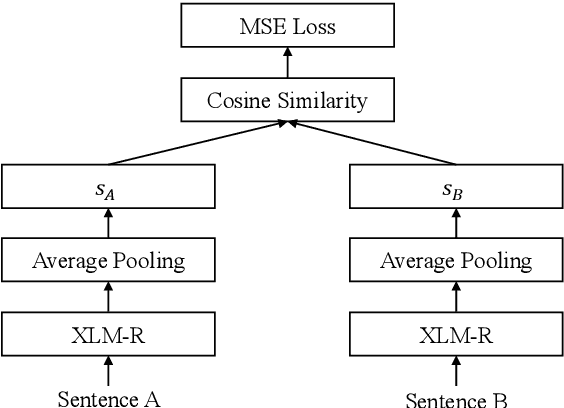
Contextualized representations from a pre-trained language model are central to achieve a high performance on downstream NLP task. The pre-trained BERT and A Lite BERT (ALBERT) models can be fine-tuned to give state-ofthe-art results in sentence-pair regressions such as semantic textual similarity (STS) and natural language inference (NLI). Although BERT-based models yield the [CLS] token vector as a reasonable sentence embedding, the search for an optimal sentence embedding scheme remains an active research area in computational linguistics. This paper explores on sentence embedding models for BERT and ALBERT. In particular, we take a modified BERT network with siamese and triplet network structures called Sentence-BERT (SBERT) and replace BERT with ALBERT to create Sentence-ALBERT (SALBERT). We also experiment with an outer CNN sentence-embedding network for SBERT and SALBERT. We evaluate performances of all sentence-embedding models considered using the STS and NLI datasets. The empirical results indicate that our CNN architecture improves ALBERT models substantially more than BERT models for STS benchmark. Despite significantly fewer model parameters, ALBERT sentence embedding is highly competitive to BERT in downstream NLP evaluations.
SelfMatch: Combining Contrastive Self-Supervision and Consistency for Semi-Supervised Learning
Jan 16, 2021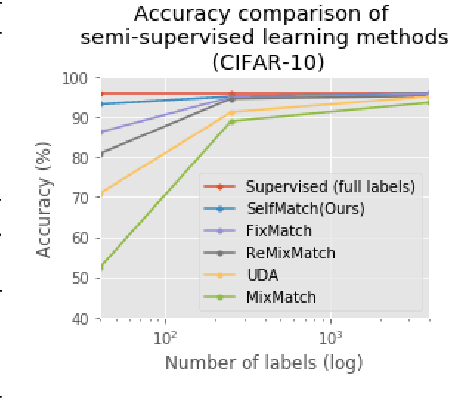
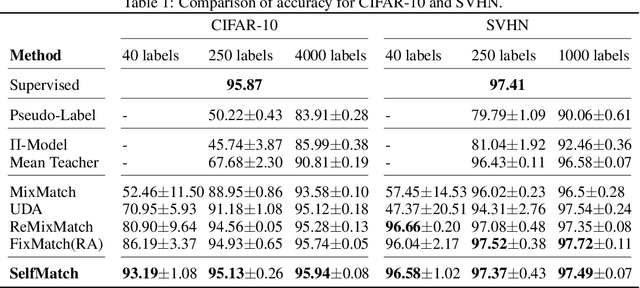
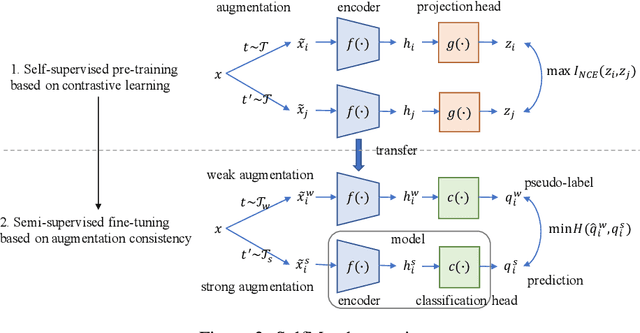

This paper introduces SelfMatch, a semi-supervised learning method that combines the power of contrastive self-supervised learning and consistency regularization. SelfMatch consists of two stages: (1) self-supervised pre-training based on contrastive learning and (2) semi-supervised fine-tuning based on augmentation consistency regularization. We empirically demonstrate that SelfMatch achieves the state-of-the-art results on standard benchmark datasets such as CIFAR-10 and SVHN. For example, for CIFAR-10 with 40 labeled examples, SelfMatch achieves 93.19% accuracy that outperforms the strong previous methods such as MixMatch (52.46%), UDA (70.95%), ReMixMatch (80.9%), and FixMatch (86.19%). We note that SelfMatch can close the gap between supervised learning (95.87%) and semi-supervised learning (93.19%) by using only a few labels for each class.