 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeSS: Head Sensitivity Score for Sparsity Redistribution in VGGT
Mar 26, 2026Visual Geometry Grounded Transformer (VGGT) has advanced 3D vision, yet its global attention layers suffer from quadratic computational costs that hinder scalability. Several sparsification-based acceleration techniques have been proposed to alleviate this issue, but they often suffer from substantial accuracy degradation. We hypothesize that the accuracy degradation stems from the heterogeneity in head-wise sparsification sensitivity, as the existing methods apply a uniform sparsity pattern across all heads. Motivated by this hypothesis, we present a two-stage sparsification pipeline that effectively quantifies and exploits headwise sparsification sensitivity. In the first stage, we measure head-wise sparsification sensitivity using a novel metric, the Head Sensitivity Score (HeSS), which approximates the Hessian with respect to two distinct error terms on a small calibration set. In the inference stage, we perform HeSS-Guided Sparsification, leveraging the pre-computed HeSS to reallocate the total attention budget-assigning denser attention to sensitive heads and sparser attention to more robust ones. We demonstrate that HeSS effectively captures head-wise sparsification sensitivity and empirically confirm that attention heads in the global attention layers exhibit heterogeneous sensitivity characteristics. Extensive experiments further show that our method effectively mitigates performance degradation under high sparsity, demonstrating strong robustness across varying sparsification levels. Code is available at https://github.com/libary753/HeSS.
Balancing Saliency and Coverage: Semantic Prominence-Aware Budgeting for Visual Token Compression in VLMs
Mar 16, 2026Large Vision-Language Models (VLMs) achieve strong multimodal understanding capabilities by leveraging high-resolution visual inputs, but the resulting large number of visual tokens creates a major computational bottleneck. Recent work mitigates this issue through visual token compression, typically compressing tokens based on saliency, diversity, or a fixed combination of both. We observe that the distribution of semantic prominence varies substantially across samples, leading to different optimal trade-offs between local saliency preservation and global coverage. This observation suggests that applying a static compression strategy across all samples can be suboptimal. Motivated by this insight, we propose PromPrune, a sample-adaptive visual token selection framework composed of semantic prominence-aware budget allocation and a two-stage selection pipeline. Our method adaptively balances local saliency preservation and global coverage according to the semantic prominence distribution of each sample. By allocating token budgets between locally salient regions and globally diverse regions, our method maintains strong performance even under high compression ratios. On LLaVA-NeXT-7B, our approach reduces FLOPs by 88% and prefill latency by 22% while preserving 97.5% of the original accuracy.
Mirroring the Mind: Distilling Human-Like Metacognitive Strategies into Large Language Models
Feb 26, 2026Large Reasoning Models (LRMs) often exhibit structural fragility in complex reasoning tasks, failing to produce correct answers even after successfully deriving valid intermediate steps. Through systematic analysis, we observe that these failures frequently stem not from a lack of reasoning capacity, but from a deficiency in self-regulatory control, where valid logic is destabilized by uncontrolled exploration or the failure to recognize logical sufficiency. Motivated by this observation, we propose Metacognitive Behavioral Tuning (MBT), a post-training framework that explicitly injects metacognitive behaviors into the model's thought process. MBT implements this via two complementary formulations: (1) MBT-S, which synthesizes rigorous reasoning traces from scratch, and (2) MBT-R, which rewrites the student's initial traces to stabilize intrinsic exploration patterns. Experiments across multi-hop QA benchmarks demonstrate that MBT consistently outperforms baselines, achieving notable gains on challenging benchmarks. By effectively eliminating reasoning collapse, MBT achieves higher accuracy with significantly reduced token consumption, demonstrating that internalizing metacognitive strategies leads to more stable and robust reasoning.
Knowledge Integration Decay in Search-Augmented Reasoning of Large Language Models
Feb 10, 2026Modern Large Language Models (LLMs) have demonstrated remarkable capabilities in complex tasks by employing search-augmented reasoning to incorporate external knowledge into long chains of thought. However, we identify a critical yet underexplored bottleneck in this paradigm, termed Knowledge Integration Decay (KID). Specifically, we observe that as the length of reasoning generated before search grows, models increasingly fail to integrate retrieved evidence into subsequent reasoning steps, limiting performance even when relevant information is available. To address this, we propose Self-Anchored Knowledge Encoding (SAKE), a training-free inference-time strategy designed to stabilize knowledge utilization. By anchoring retrieved knowledge at both the beginning and end of the reasoning process, SAKE prevents it from being overshadowed by prior context, thereby preserving its semantic integrity. Extensive experiments on multi-hop QA and complex reasoning benchmarks demonstrate that SAKE significantly mitigates KID and improves performance, offering a lightweight yet effective solution for knowledge integration in agentic LLMs.
Contextualized Visual Personalization in Vision-Language Models
Feb 03, 2026Despite recent progress in vision-language models (VLMs), existing approaches often fail to generate personalized responses based on the user's specific experiences, as they lack the ability to associate visual inputs with a user's accumulated visual-textual context. We newly formalize this challenge as contextualized visual personalization, which requires the visual recognition and textual retrieval of personalized visual experiences by VLMs when interpreting new images. To address this issue, we propose CoViP, a unified framework that treats personalized image captioning as a core task for contextualized visual personalization and improves this capability through reinforcement-learning-based post-training and caption-augmented generation. We further introduce diagnostic evaluations that explicitly rule out textual shortcut solutions and verify whether VLMs truly leverage visual context. Extensive experiments demonstrate that existing open-source and proprietary VLMs exhibit substantial limitations, while CoViP not only improves personalized image captioning but also yields holistic gains across downstream personalization tasks. These results highlight CoViP as a crucial stage for enabling robust and generalizable contextualized visual personalization.
TextGuider: Training-Free Guidance for Text Rendering via Attention Alignment
Dec 13, 2025
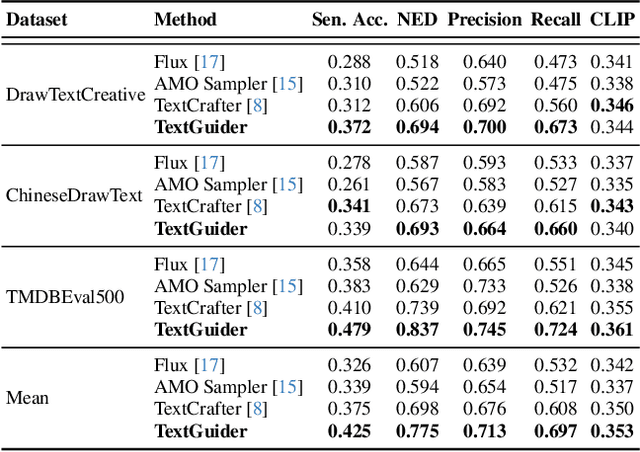
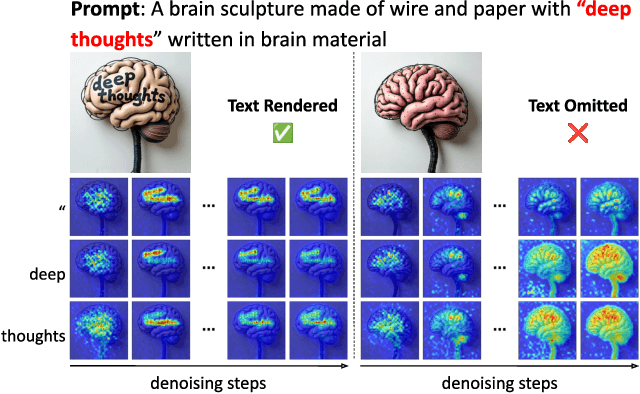
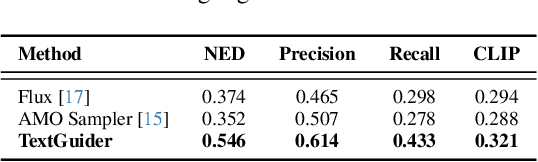
Despite recent advances, diffusion-based text-to-image models still struggle with accurate text rendering. Several studies have proposed fine-tuning or training-free refinement methods for accurate text rendering. However, the critical issue of text omission, where the desired text is partially or entirely missing, remains largely overlooked. In this work, we propose TextGuider, a novel training-free method that encourages accurate and complete text appearance by aligning textual content tokens and text regions in the image. Specifically, we analyze attention patterns in Multi-Modal Diffusion Transformer(MM-DiT) models, particularly for text-related tokens intended to be rendered in the image. Leveraging this observation, we apply latent guidance during the early stage of denoising steps based on two loss functions that we introduce. Our method achieves state-of-the-art performance in test-time text rendering, with significant gains in recall and strong results in OCR accuracy and CLIP score.
Guiding What Not to Generate: Automated Negative Prompting for Text-Image Alignment
Dec 11, 2025Despite substantial progress in text-to-image generation, achieving precise text-image alignment remains challenging, particularly for prompts with rich compositional structure or imaginative elements. To address this, we introduce Negative Prompting for Image Correction (NPC), an automated pipeline that improves alignment by identifying and applying negative prompts that suppress unintended content. We begin by analyzing cross-attention patterns to explain why both targeted negatives-those directly tied to the prompt's alignment error-and untargeted negatives-tokens unrelated to the prompt but present in the generated image-can enhance alignment. To discover useful negatives, NPC generates candidate prompts using a verifier-captioner-proposer framework and ranks them with a salient text-space score, enabling effective selection without requiring additional image synthesis. On GenEval++ and Imagine-Bench, NPC outperforms strong baselines, achieving 0.571 vs. 0.371 on GenEval++ and the best overall performance on Imagine-Bench. By guiding what not to generate, NPC provides a principled, fully automated route to stronger text-image alignment in diffusion models. Code is released at https://github.com/wiarae/NPC.
SAVE: Sparse Autoencoder-Driven Visual Information Enhancement for Mitigating Object Hallucination
Dec 11, 2025Although Multimodal Large Language Models (MLLMs) have advanced substantially, they remain vulnerable to object hallucination caused by language priors and visual information loss. To address this, we propose SAVE (Sparse Autoencoder-Driven Visual Information Enhancement), a framework that mitigates hallucination by steering the model along Sparse Autoencoder (SAE) latent features. A binary object-presence question-answering probe identifies the SAE features most indicative of the model's visual information processing, referred to as visual understanding features. Steering the model along these identified features reinforces grounded visual understanding and effectively reduces hallucination. With its simple design, SAVE outperforms state-of-the-art training-free methods on standard benchmarks, achieving a 10\%p improvement in CHAIR\_S and consistent gains on POPE and MMHal-Bench. Extensive evaluations across multiple models and layers confirm the robustness and generalizability of our approach. Further analysis reveals that steering along visual understanding features suppresses the generation of uncertain object tokens and increases attention to image tokens, mitigating hallucination. Code is released at https://github.com/wiarae/SAVE.
A Multifaceted Analysis of Negative Bias in Large Language Models through the Lens of Parametric Knowledge
Nov 14, 2025
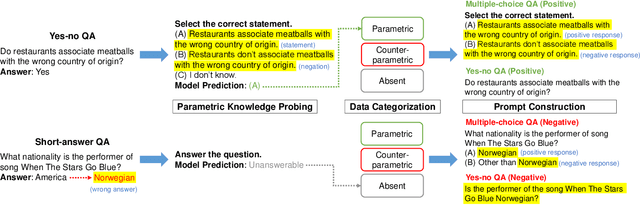


Negative bias refers to the tendency of large language models (LLMs) to excessively generate negative responses in binary decision tasks (e.g., yes-no question answering). Previous research has focused on detecting and addressing negative attention heads that induce negative bias. However, the underlying detailed factors influencing negative bias remain underexplored. In this paper, we demonstrate that LLMs exhibit format-level negative bias, meaning the prompt format more influences their responses than the semantics of the negative response. For the fine-grained study of the negative bias, we introduce a pipeline for constructing the evaluation set, which systematically categorizes the dataset into three subsets based on the model's parametric knowledge: correct, incorrect, and insufficient relevant knowledge. Through analysis of this evaluation set, we identify a shortcut behavior in which models tend to generate negative responses when they lack sufficient knowledge to answer a yes-no question, leading to negative bias. We further examine how negative bias changes under various prompting scenarios related to parametric knowledge. We observe that providing relevant context and offering an "I don't know" option generally reduces negative bias, whereas chain-of-thought prompting tends to amplify the bias. Finally, we demonstrate that the degree of negative bias can vary depending on the type of prompt, which influences the direction of the response. Our work reveals the various factors that influence negative bias, providing critical insights for mitigating it in LLMs.
Causality-Aware Contrastive Learning for Robust Multivariate Time-Series Anomaly Detection
Jun 04, 2025Utilizing the complex inter-variable causal relationships within multivariate time-series provides a promising avenue toward more robust and reliable multivariate time-series anomaly detection (MTSAD) but remains an underexplored area of research. This paper proposes Causality-Aware contrastive learning for RObust multivariate Time-Series (CAROTS), a novel MTSAD pipeline that incorporates the notion of causality into contrastive learning. CAROTS employs two data augmentors to obtain causality-preserving and -disturbing samples that serve as a wide range of normal variations and synthetic anomalies, respectively. With causality-preserving and -disturbing samples as positives and negatives, CAROTS performs contrastive learning to train an encoder whose latent space separates normal and abnormal samples based on causality. Moreover, CAROTS introduces a similarity-filtered one-class contrastive loss that encourages the contrastive learning process to gradually incorporate more semantically diverse samples with common causal relationships. Extensive experiments on five real-world and two synthetic datasets validate that the integration of causal relationships endows CAROTS with improved MTSAD capabilities. The code is available at https://github.com/kimanki/CAROTS.