 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnow "No" Better: A Data-Driven Approach for Enhancing Negation Awareness in CLIP
Jan 19, 2025While CLIP has significantly advanced multimodal understanding by bridging vision and language, the inability to grasp negation - such as failing to differentiate concepts like "parking" from "no parking" - poses substantial challenges. By analyzing the data used in the public CLIP model's pre-training, we posit this limitation stems from a lack of negation-inclusive data. To address this, we introduce data generation pipelines that employ a large language model (LLM) and a multimodal LLM to produce negation-inclusive captions. Fine-tuning CLIP with data generated from our pipelines, we develop NegationCLIP, which enhances negation awareness while preserving the generality. Moreover, to enable a comprehensive evaluation of negation understanding, we propose NegRefCOCOg-a benchmark tailored to test VLMs' ability to interpret negation across diverse expressions and positions within a sentence. Experiments on various CLIP architectures validate the effectiveness of our data generation pipelines in enhancing CLIP's ability to perceive negation accurately. Additionally, NegationCLIP's enhanced negation awareness has practical applications across various multimodal tasks, demonstrated by performance gains in text-to-image generation and referring image segmentation.
Toward Interactive Regional Understanding in Vision-Large Language Models
Mar 27, 2024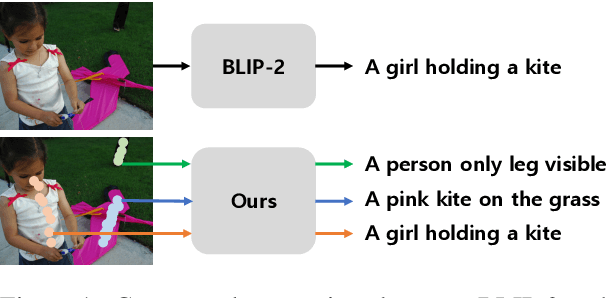

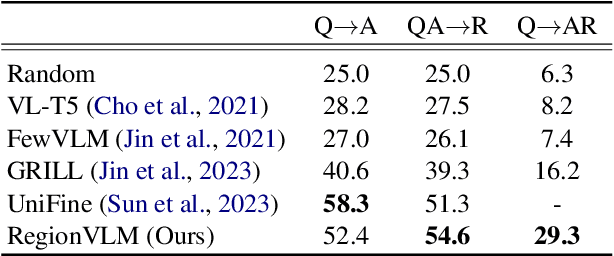
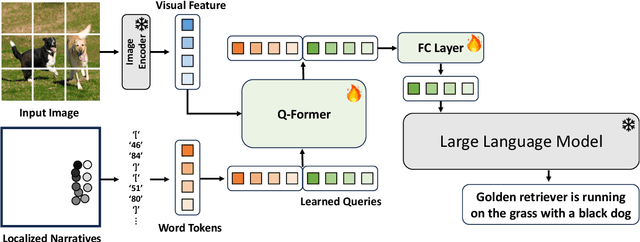
Recent Vision-Language Pre-training (VLP) models have demonstrated significant advancements. Nevertheless, these models heavily rely on image-text pairs that capture only coarse and global information of an image, leading to a limitation in their regional understanding ability. In this work, we introduce \textbf{RegionVLM}, equipped with explicit regional modeling capabilities, allowing them to understand user-indicated image regions. To achieve this, we design a simple yet innovative architecture, requiring no modifications to the model architecture or objective function. Additionally, we leverage a dataset that contains a novel source of information, namely Localized Narratives, which has been overlooked in previous VLP research. Our experiments demonstrate that our single generalist model not only achieves an interactive dialogue system but also exhibits superior performance on various zero-shot region understanding tasks, without compromising its ability for global image understanding.
Improving Visual Prompt Tuning for Self-supervised Vision Transformers
Jun 08, 2023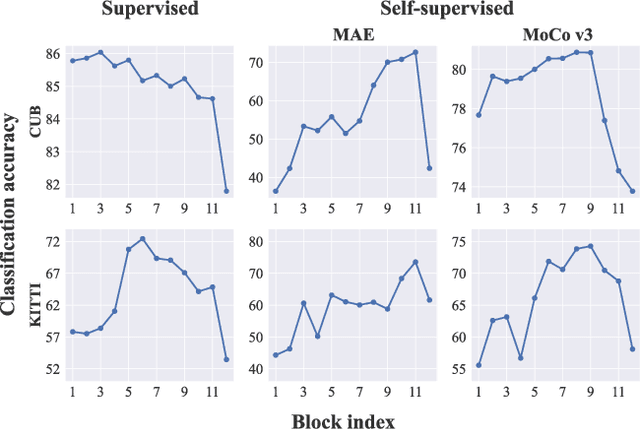
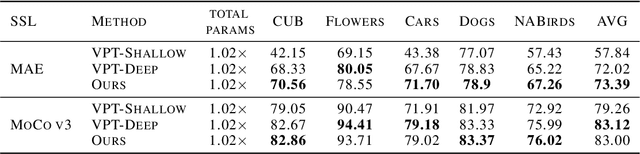
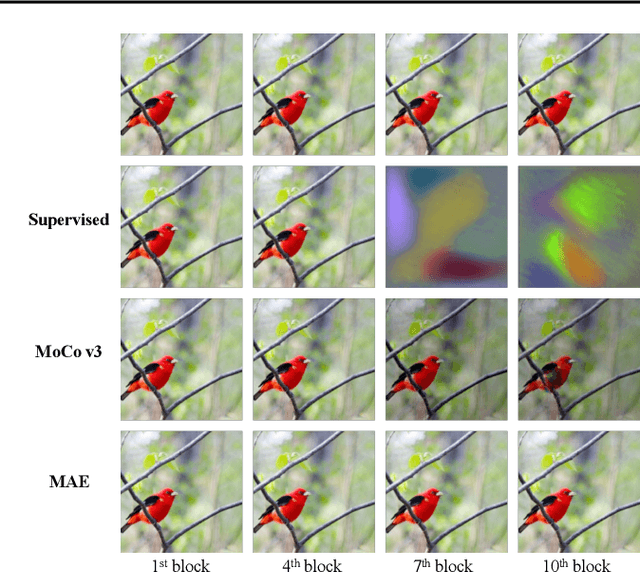
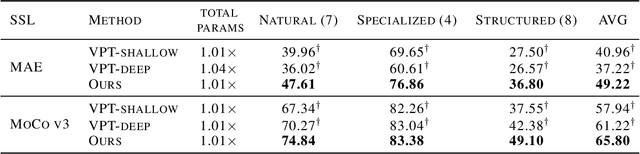
Visual Prompt Tuning (VPT) is an effective tuning method for adapting pretrained Vision Transformers (ViTs) to downstream tasks. It leverages extra learnable tokens, known as prompts, which steer the frozen pretrained ViTs. Although VPT has demonstrated its applicability with supervised vision transformers, it often underperforms with self-supervised ones. Through empirical observations, we deduce that the effectiveness of VPT hinges largely on the ViT blocks with which the prompt tokens interact. Specifically, VPT shows improved performance on image classification tasks for MAE and MoCo v3 when the prompt tokens are inserted into later blocks rather than the first block. These observations suggest that there exists an optimal location of blocks for the insertion of prompt tokens. Unfortunately, identifying the optimal blocks for prompts within each self-supervised ViT for diverse future scenarios is a costly process. To mitigate this problem, we propose a simple yet effective method that learns a gate for each ViT block to adjust its intervention into the prompt tokens. With our method, prompt tokens are selectively influenced by blocks that require steering for task adaptation. Our method outperforms VPT variants in FGVC and VTAB image classification and ADE20K semantic segmentation. The code is available at https://github.com/ryongithub/GatedPromptTuning.
Anti-Adversarially Manipulated Attributions for Weakly Supervised Semantic Segmentation and Object Localization
Apr 11, 2022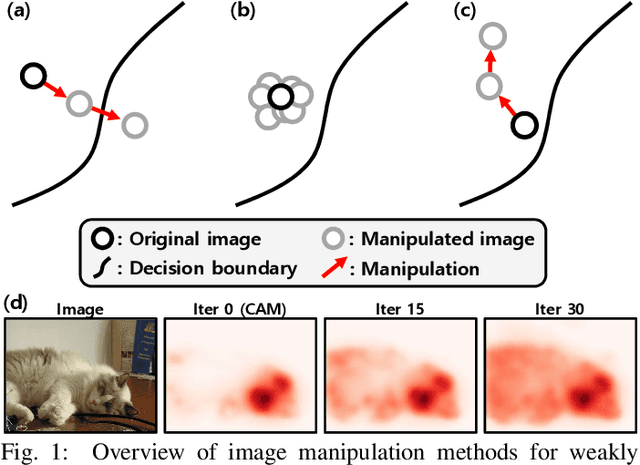
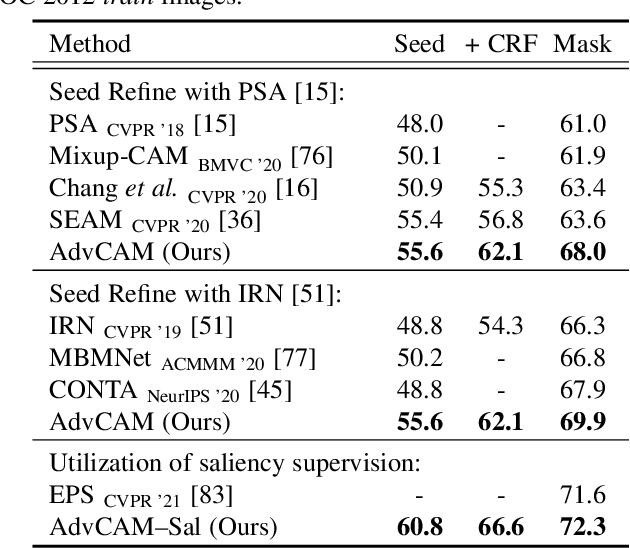
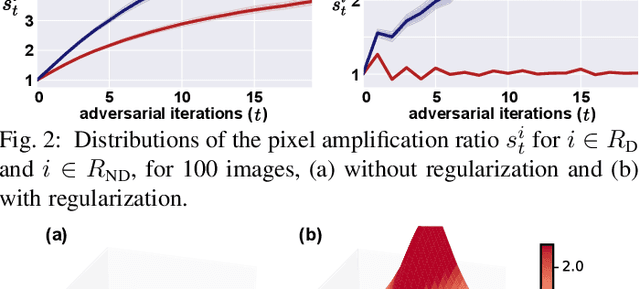

Obtaining accurate pixel-level localization from class labels is a crucial process in weakly supervised semantic segmentation and object localization. Attribution maps from a trained classifier are widely used to provide pixel-level localization, but their focus tends to be restricted to a small discriminative region of the target object. An AdvCAM is an attribution map of an image that is manipulated to increase the classification score produced by a classifier before the final softmax or sigmoid layer. This manipulation is realized in an anti-adversarial manner, so that the original image is perturbed along pixel gradients in directions opposite to those used in an adversarial attack. This process enhances non-discriminative yet class-relevant features, which make an insufficient contribution to previous attribution maps, so that the resulting AdvCAM identifies more regions of the target object. In addition, we introduce a new regularization procedure that inhibits the incorrect attribution of regions unrelated to the target object and the excessive concentration of attributions on a small region of the target object. Our method achieves a new state-of-the-art performance in weakly and semi-supervised semantic segmentation, on both the PASCAL VOC 2012 and MS COCO 2014 datasets. In weakly supervised object localization, it achieves a new state-of-the-art performance on the CUB-200-2011 and ImageNet-1K datasets.
Perception Prioritized Training of Diffusion Models
Apr 01, 2022
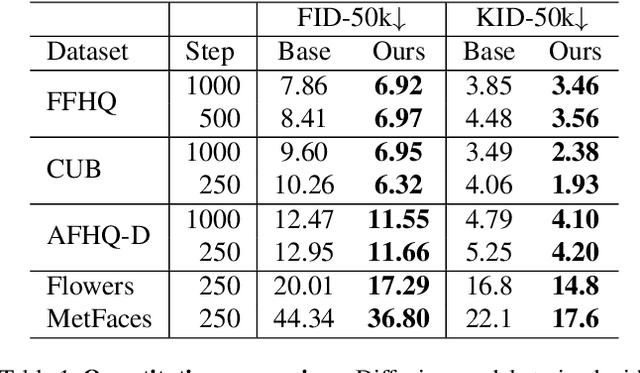


Diffusion models learn to restore noisy data, which is corrupted with different levels of noise, by optimizing the weighted sum of the corresponding loss terms, i.e., denoising score matching loss. In this paper, we show that restoring data corrupted with certain noise levels offers a proper pretext task for the model to learn rich visual concepts. We propose to prioritize such noise levels over other levels during training, by redesigning the weighting scheme of the objective function. We show that our simple redesign of the weighting scheme significantly improves the performance of diffusion models regardless of the datasets, architectures, and sampling strategies.
Bridging the Gap between Classification and Localization for Weakly Supervised Object Localization
Apr 01, 2022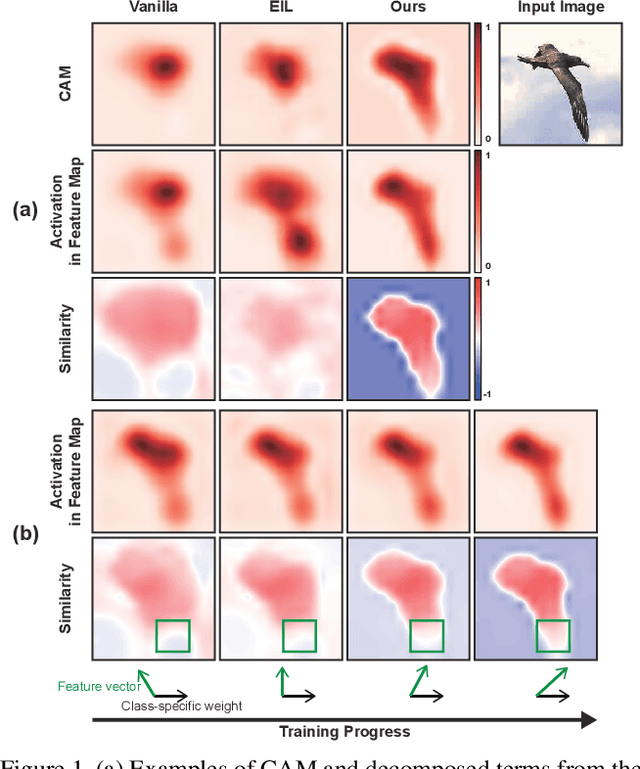
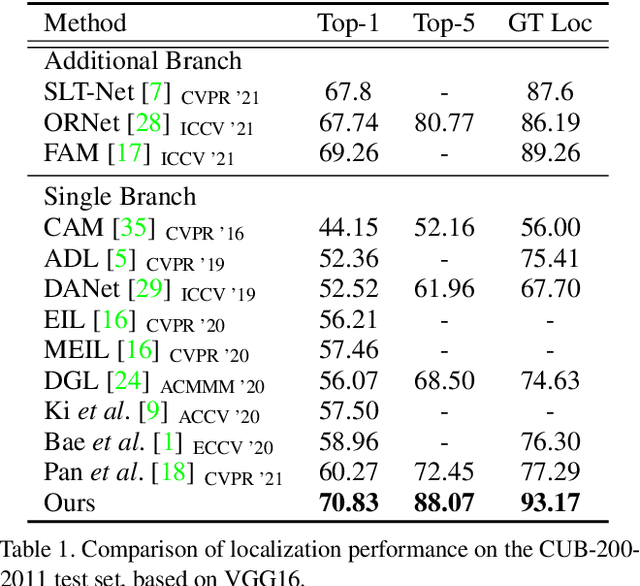
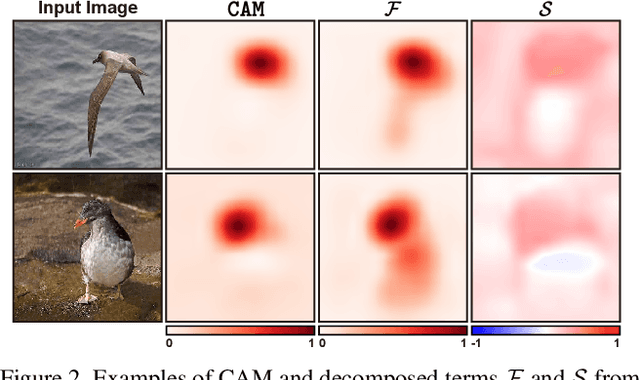
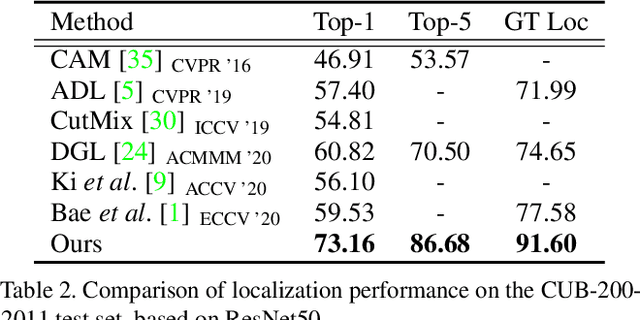
Weakly supervised object localization aims to find a target object region in a given image with only weak supervision, such as image-level labels. Most existing methods use a class activation map (CAM) to generate a localization map; however, a CAM identifies only the most discriminative parts of a target object rather than the entire object region. In this work, we find the gap between classification and localization in terms of the misalignment of the directions between an input feature and a class-specific weight. We demonstrate that the misalignment suppresses the activation of CAM in areas that are less discriminative but belong to the target object. To bridge the gap, we propose a method to align feature directions with a class-specific weight. The proposed method achieves a state-of-the-art localization performance on the CUB-200-2011 and ImageNet-1K benchmarks.
Weakly Supervised Semantic Segmentation using Out-of-Distribution Data
Mar 08, 2022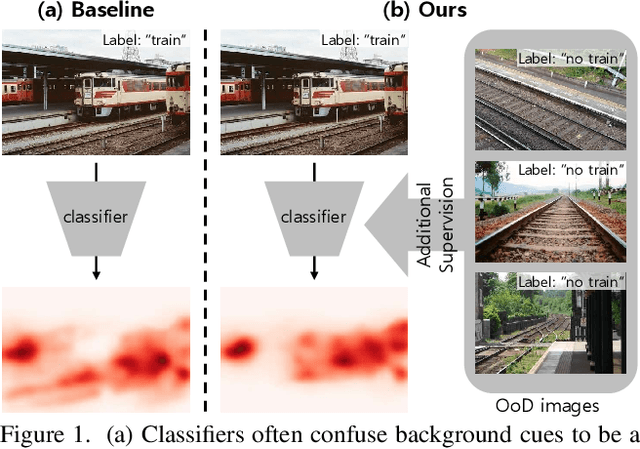



Weakly supervised semantic segmentation (WSSS) methods are often built on pixel-level localization maps obtained from a classifier. However, training on class labels only, classifiers suffer from the spurious correlation between foreground and background cues (e.g. train and rail), fundamentally bounding the performance of WSSS. There have been previous endeavors to address this issue with additional supervision. We propose a novel source of information to distinguish foreground from the background: Out-of-Distribution (OoD) data, or images devoid of foreground object classes. In particular, we utilize the hard OoDs that the classifier is likely to make false-positive predictions. These samples typically carry key visual features on the background (e.g. rail) that the classifiers often confuse as foreground (e.g. train), so these cues let classifiers correctly suppress spurious background cues. Acquiring such hard OoDs does not require an extensive amount of annotation efforts; it only incurs a few additional image-level labeling costs on top of the original efforts to collect class labels. We propose a method, W-OoD, for utilizing the hard OoDs. W-OoD achieves state-of-the-art performance on Pascal VOC 2012.
Reducing Information Bottleneck for Weakly Supervised Semantic Segmentation
Oct 13, 2021
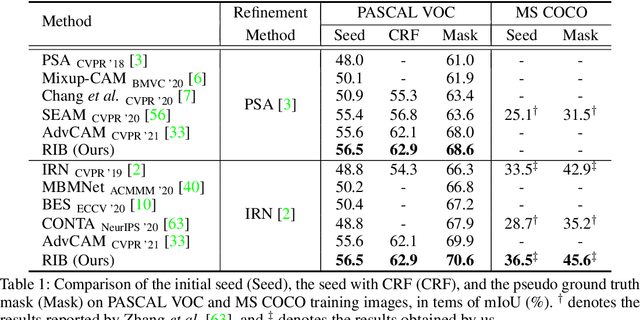
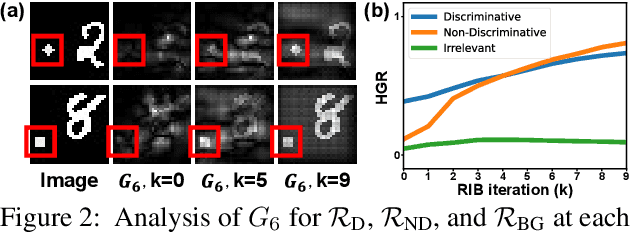
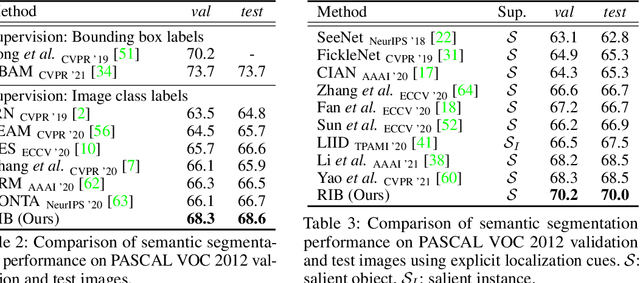
Weakly supervised semantic segmentation produces pixel-level localization from class labels; however, a classifier trained on such labels is likely to focus on a small discriminative region of the target object. We interpret this phenomenon using the information bottleneck principle: the final layer of a deep neural network, activated by the sigmoid or softmax activation functions, causes an information bottleneck, and as a result, only a subset of the task-relevant information is passed on to the output. We first support this argument through a simulated toy experiment and then propose a method to reduce the information bottleneck by removing the last activation function. In addition, we introduce a new pooling method that further encourages the transmission of information from non-discriminative regions to the classification. Our experimental evaluations demonstrate that this simple modification significantly improves the quality of localization maps on both the PASCAL VOC 2012 and MS COCO 2014 datasets, exhibiting a new state-of-the-art performance for weakly supervised semantic segmentation. The code is available at: https://github.com/jbeomlee93/RIB.
Toward Spatially Unbiased Generative Models
Aug 03, 2021
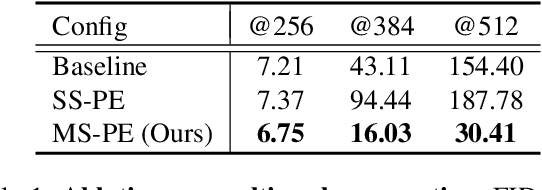
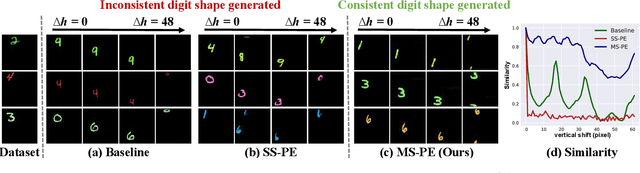
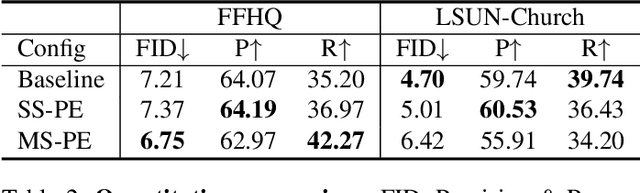
Recent image generation models show remarkable generation performance. However, they mirror strong location preference in datasets, which we call spatial bias. Therefore, generators render poor samples at unseen locations and scales. We argue that the generators rely on their implicit positional encoding to render spatial content. From our observations, the generator's implicit positional encoding is translation-variant, making the generator spatially biased. To address this issue, we propose injecting explicit positional encoding at each scale of the generator. By learning the spatially unbiased generator, we facilitate the robust use of generators in multiple tasks, such as GAN inversion, multi-scale generation, generation of arbitrary sizes and aspect ratios. Furthermore, we show that our method can also be applied to denoising diffusion probabilistic models.
BBAM: Bounding Box Attribution Map for Weakly Supervised Semantic and Instance Segmentation
Mar 16, 2021
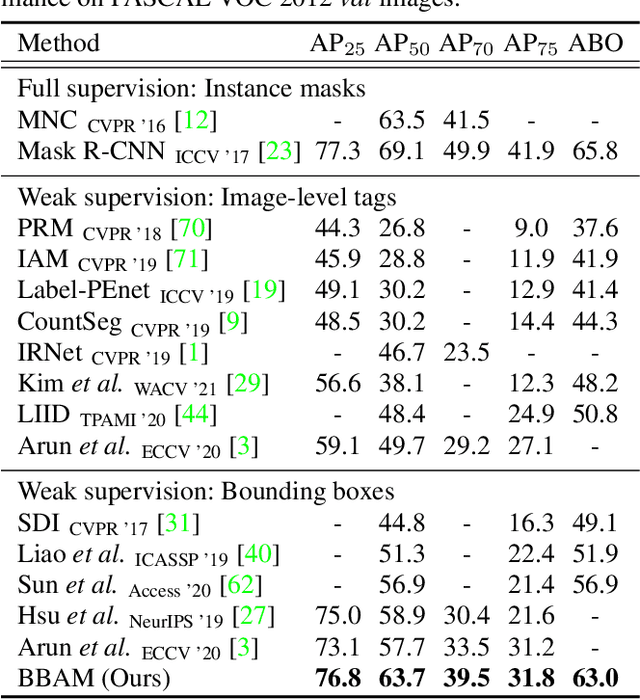


Weakly supervised segmentation methods using bounding box annotations focus on obtaining a pixel-level mask from each box containing an object. Existing methods typically depend on a class-agnostic mask generator, which operates on the low-level information intrinsic to an image. In this work, we utilize higher-level information from the behavior of a trained object detector, by seeking the smallest areas of the image from which the object detector produces almost the same result as it does from the whole image. These areas constitute a bounding-box attribution map (BBAM), which identifies the target object in its bounding box and thus serves as pseudo ground-truth for weakly supervised semantic and instance segmentation. This approach significantly outperforms recent comparable techniques on both the PASCAL VOC and MS COCO benchmarks in weakly supervised semantic and instance segmentation. In addition, we provide a detailed analysis of our method, offering deeper insight into the behavior of the BBAM.