 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Multi-Image Understanding through Delimiter Token Scaling
Feb 02, 2026Large Vision-Language Models (LVLMs) achieve strong performance on single-image tasks, but their performance declines when multiple images are provided as input. One major reason is the cross-image information leakage, where the model struggles to distinguish information across different images. Existing LVLMs already employ delimiter tokens to mark the start and end of each image, yet our analysis reveals that these tokens fail to effectively block cross-image information leakage. To enhance their effectiveness, we propose a method that scales the hidden states of delimiter tokens. This enhances the model's ability to preserve image-specific information by reinforcing intra-image interaction and limiting undesired cross-image interactions. Consequently, the model is better able to distinguish between images and reason over them more accurately. Experiments show performance gains on multi-image benchmarks such as Mantis, MuirBench, MIRB, and QBench2. We further evaluate our method on text-only tasks that require clear distinction. The method improves performance on multi-document and multi-table understanding benchmarks, including TQABench, MultiNews, and WCEP-10. Notably, our method requires no additional training or inference cost.
Dynamics Reveals Structure: Challenging the Linear Propagation Assumption
Jan 29, 2026Neural networks adapt through first-order parameter updates, yet it remains unclear whether such updates preserve logical coherence. We investigate the geometric limits of the Linear Propagation Assumption (LPA), the premise that local updates coherently propagate to logical consequences. To formalize this, we adopt relation algebra and study three core operations on relations: negation flips truth values, converse swaps argument order, and composition chains relations. For negation and converse, we prove that guaranteeing direction-agnostic first-order propagation necessitates a tensor factorization separating entity-pair context from relation content. However, for composition, we identify a fundamental obstruction. We show that composition reduces to conjunction, and prove that any conjunction well-defined on linear features must be bilinear. Since bilinearity is incompatible with negation, this forces the feature map to collapse. These results suggest that failures in knowledge editing, the reversal curse, and multi-hop reasoning may stem from common structural limitations inherent to the LPA.
Privacy Collapse: Benign Fine-Tuning Can Break Contextual Privacy in Language Models
Jan 21, 2026We identify a novel phenomenon in language models: benign fine-tuning of frontier models can lead to privacy collapse. We find that diverse, subtle patterns in training data can degrade contextual privacy, including optimisation for helpfulness, exposure to user information, emotional and subjective dialogue, and debugging code printing internal variables, among others. Fine-tuned models lose their ability to reason about contextual privacy norms, share information inappropriately with tools, and violate memory boundaries across contexts. Privacy collapse is a ``silent failure'' because models maintain high performance on standard safety and utility benchmarks whilst exhibiting severe privacy vulnerabilities. Our experiments show evidence of privacy collapse across six models (closed and open weight), five fine-tuning datasets (real-world and controlled data), and two task categories (agentic and memory-based). Our mechanistic analysis reveals that privacy representations are uniquely fragile to fine-tuning, compared to task-relevant features which are preserved. Our results reveal a critical gap in current safety evaluations, in particular for the deployment of specialised agents.
Un-Attributability: Computing Novelty From Retrieval & Semantic Similarity
Oct 31, 2025Understanding how language-model outputs relate to the pretraining corpus is central to studying model behavior. Most training data attribution (TDA) methods ask which training examples causally influence a given output, often using leave-one-out tests. We invert the question: which outputs cannot be attributed to any pretraining example? We introduce un-attributability as an operational measure of semantic novelty: an output is novel if the pretraining corpus contains no semantically similar context. We approximate this with a simple two-stage retrieval pipeline: index the corpus with lightweight GIST embeddings, retrieve the top-n candidates, then rerank with ColBERTv2. If the nearest corpus item is less attributable than a human-generated text reference, we consider the output of the model as novel. We evaluate on SmolLM and SmolLM2 and report three findings: (1) models draw on pretraining data across much longer spans than previously reported; (2) some domains systematically promote or suppress novelty; and (3) instruction tuning not only alters style but also increases novelty. Reframing novelty assessment around un-attributability enables efficient analysis at pretraining scale. We release ~20 TB of corpus chunks and index artifacts to support replication and large-scale extension of our analysis at https://huggingface.co/datasets/stai-tuebingen/faiss-smollm
What Defines Good Reasoning in LLMs? Dissecting Reasoning Steps with Multi-Aspect Evaluation
Oct 23, 2025
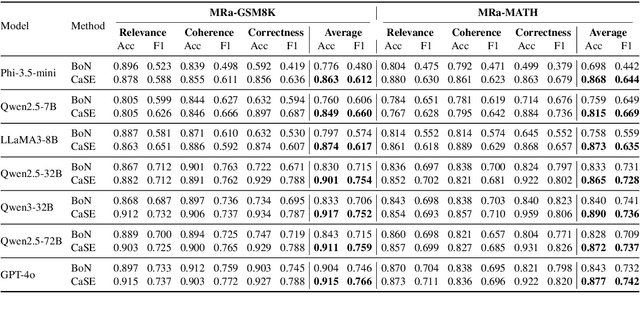
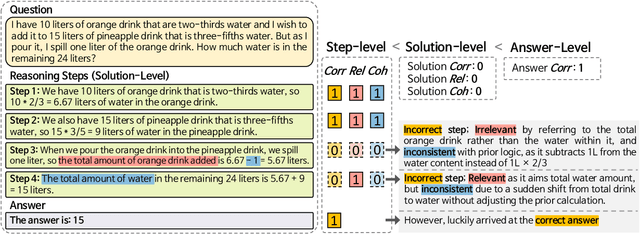
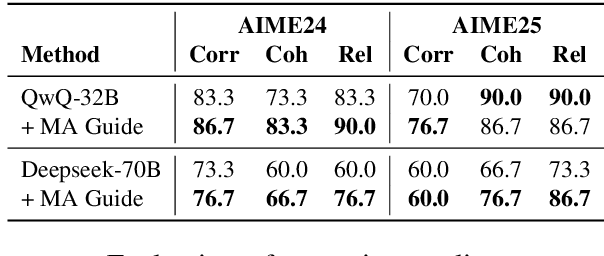
Evaluating large language models (LLMs) on final-answer correctness is the dominant paradigm. This approach, however, provides a coarse signal for model improvement and overlooks the quality of the underlying reasoning process. We argue that a more granular evaluation of reasoning offers a more effective path to building robust models. We decompose reasoning quality into two dimensions: relevance and coherence. Relevance measures if a step is grounded in the problem; coherence measures if it follows logically from prior steps. To measure these aspects reliably, we introduce causal stepwise evaluation (CaSE). This method assesses each reasoning step using only its preceding context, which avoids hindsight bias. We validate CaSE against human judgments on our new expert-annotated benchmarks, MRa-GSM8K and MRa-MATH. More importantly, we show that curating training data with CaSE-evaluated relevance and coherence directly improves final task performance. Our work provides a scalable framework for analyzing, debugging, and improving LLM reasoning, demonstrating the practical value of moving beyond validity checks.
Dr.LLM: Dynamic Layer Routing in LLMs
Oct 14, 2025Large Language Models (LLMs) process every token through all layers of a transformer stack, causing wasted computation on simple queries and insufficient flexibility for harder ones that need deeper reasoning. Adaptive-depth methods can improve efficiency, but prior approaches rely on costly inference-time search, architectural changes, or large-scale retraining, and in practice often degrade accuracy despite efficiency gains. We introduce Dr.LLM, Dynamic routing of Layers for LLMs, a retrofittable framework that equips pretrained models with lightweight per-layer routers deciding to skip, execute, or repeat a block. Routers are trained with explicit supervision: using Monte Carlo Tree Search (MCTS), we derive high-quality layer configurations that preserve or improve accuracy under a compute budget. Our design, windowed pooling for stable routing, focal loss with class balancing, and bottleneck MLP routers, ensures robustness under class imbalance and long sequences. On ARC (logic) and DART (math), Dr.LLM improves accuracy by up to +3.4%p while saving 5 layers per example on average. Routers generalize to out-of-domain tasks (MMLU, GSM8k, AIME, TruthfulQA, SQuADv2, GPQA, PIQA, AGIEval) with only 0.85% accuracy drop while retaining efficiency, and outperform prior routing methods by up to +7.7%p. Overall, Dr.LLM shows that explicitly supervised routers retrofit frozen LLMs for budget-aware, accuracy-driven inference without altering base weights.
DISCO: Diversifying Sample Condensation for Efficient Model Evaluation
Oct 09, 2025Evaluating modern machine learning models has become prohibitively expensive. Benchmarks such as LMMs-Eval and HELM demand thousands of GPU hours per model. Costly evaluation reduces inclusivity, slows the cycle of innovation, and worsens environmental impact. The typical approach follows two steps. First, select an anchor subset of data. Second, train a mapping from the accuracy on this subset to the final test result. The drawback is that anchor selection depends on clustering, which can be complex and sensitive to design choices. We argue that promoting diversity among samples is not essential; what matters is to select samples that $\textit{maximise diversity in model responses}$. Our method, $\textbf{Diversifying Sample Condensation (DISCO)}$, selects the top-k samples with the greatest model disagreements. This uses greedy, sample-wise statistics rather than global clustering. The approach is conceptually simpler. From a theoretical view, inter-model disagreement provides an information-theoretically optimal rule for such greedy selection. $\textbf{DISCO}$ shows empirical gains over prior methods, achieving state-of-the-art results in performance prediction across MMLU, Hellaswag, Winogrande, and ARC. Code is available here: https://github.com/arubique/disco-public.
First Hallucination Tokens Are Different from Conditional Ones
Jul 28, 2025Hallucination, the generation of untruthful content, is one of the major concerns regarding foundational models. Detecting hallucinations at the token level is vital for real-time filtering and targeted correction, yet the variation of hallucination signals within token sequences is not fully understood. Leveraging the RAGTruth corpus with token-level annotations and reproduced logits, we analyse how these signals depend on a token's position within hallucinated spans, contributing to an improved understanding of token-level hallucination. Our results show that the first hallucinated token carries a stronger signal and is more detectable than conditional tokens. We release our analysis framework, along with code for logit reproduction and metric computation at https://github.com/jakobsnl/RAGTruth_Xtended.
Does Data Scaling Lead to Visual Compositional Generalization?
Jul 09, 2025Compositional understanding is crucial for human intelligence, yet it remains unclear whether contemporary vision models exhibit it. The dominant machine learning paradigm is built on the premise that scaling data and model sizes will improve out-of-distribution performance, including compositional generalization. We test this premise through controlled experiments that systematically vary data scale, concept diversity, and combination coverage. We find that compositional generalization is driven by data diversity, not mere data scale. Increased combinatorial coverage forces models to discover a linearly factored representational structure, where concepts decompose into additive components. We prove this structure is key to efficiency, enabling perfect generalization from few observed combinations. Evaluating pretrained models (DINO, CLIP), we find above-random yet imperfect performance, suggesting partial presence of this structure. Our work motivates stronger emphasis on constructing diverse datasets for compositional generalization, and considering the importance of representational structure that enables efficient compositional learning. Code available at https://github.com/oshapio/visual-compositional-generalization.
Leaky Thoughts: Large Reasoning Models Are Not Private Thinkers
Jun 18, 2025We study privacy leakage in the reasoning traces of large reasoning models used as personal agents. Unlike final outputs, reasoning traces are often assumed to be internal and safe. We challenge this assumption by showing that reasoning traces frequently contain sensitive user data, which can be extracted via prompt injections or accidentally leak into outputs. Through probing and agentic evaluations, we demonstrate that test-time compute approaches, particularly increased reasoning steps, amplify such leakage. While increasing the budget of those test-time compute approaches makes models more cautious in their final answers, it also leads them to reason more verbosely and leak more in their own thinking. This reveals a core tension: reasoning improves utility but enlarges the privacy attack surface. We argue that safety efforts must extend to the model's internal thinking, not just its outputs.