 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiCoTTA: Domain-invariant Learning for Continual Test-time Adaptation
Apr 07, 2025



This paper studies continual test-time adaptation (CTTA), the task of adapting a model to constantly changing unseen domains in testing while preserving previously learned knowledge. Existing CTTA methods mostly focus on adaptation to the current test domain only, overlooking generalization to arbitrary test domains a model may face in the future. To tackle this limitation, we present a novel online domain-invariant learning framework for CTTA, dubbed DiCoTTA. DiCoTTA aims to learn feature representation to be invariant to both current and previous test domains on the fly during testing. To this end, we propose a new model architecture and a test-time adaptation strategy dedicated to learning domain-invariant features without corrupting semantic contents, along with a new data structure and optimization algorithm for effectively managing information from previous test domains. DiCoTTA achieved state-of-the-art performance on four public CTTA benchmarks. Moreover, it showed superior generalization to unseen test domains.
Improving Robustness to Multiple Spurious Correlations by Multi-Objective Optimization
Sep 05, 2024



We study the problem of training an unbiased and accurate model given a dataset with multiple biases. This problem is challenging since the multiple biases cause multiple undesirable shortcuts during training, and even worse, mitigating one may exacerbate the other. We propose a novel training method to tackle this challenge. Our method first groups training data so that different groups induce different shortcuts, and then optimizes a linear combination of group-wise losses while adjusting their weights dynamically to alleviate conflicts between the groups in performance; this approach, rooted in the multi-objective optimization theory, encourages to achieve the minimax Pareto solution. We also present a new benchmark with multiple biases, dubbed MultiCelebA, for evaluating debiased training methods under realistic and challenging scenarios. Our method achieved the best on three datasets with multiple biases, and also showed superior performance on conventional single-bias datasets.
Exploiting Synthetic Data for Data Imbalance Problems: Baselines from a Data Perspective
Aug 02, 2023



We live in a vast ocean of data, and deep neural networks are no exception to this. However, this data exhibits an inherent phenomenon of imbalance. This imbalance poses a risk of deep neural networks producing biased predictions, leading to potentially severe ethical and social consequences. To address these challenges, we believe that the use of generative models is a promising approach for comprehending tasks, given the remarkable advancements demonstrated by recent diffusion models in generating high-quality images. In this work, we propose a simple yet effective baseline, SYNAuG, that utilizes synthetic data as a preliminary step before employing task-specific algorithms to address data imbalance problems. This straightforward approach yields impressive performance on datasets such as CIFAR100-LT, ImageNet100-LT, UTKFace, and Waterbird, surpassing the performance of existing task-specific methods. While we do not claim that our approach serves as a complete solution to the problem of data imbalance, we argue that supplementing the existing data with synthetic data proves to be an effective and crucial preliminary step in addressing data imbalance concerns.
Learning Debiased Classifier with Biased Committee
Jun 22, 2022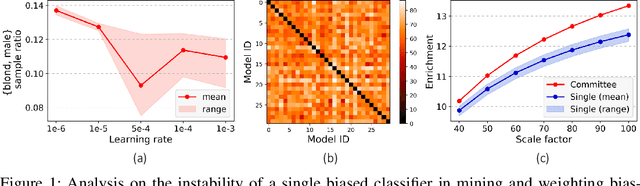
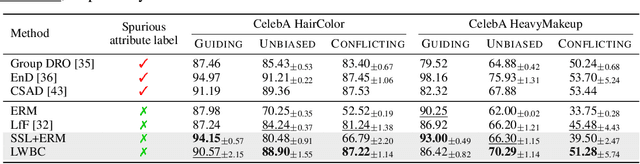
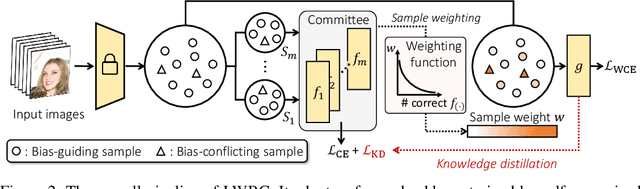
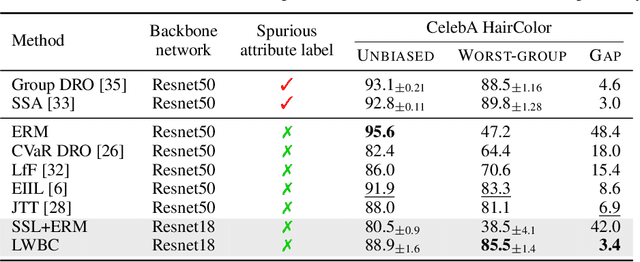
Neural networks are prone to be biased towards spurious correlations between classes and latent attributes exhibited in a major portion of training data, which ruins their generalization capability. This paper proposes a new method for training debiased classifiers with no spurious attribute label. The key idea of the method is to employ a committee of classifiers as an auxiliary module that identifies bias-conflicting data, i.e., data without spurious correlations, and assigns large weights to them when training the main classifier. The committee is learned as a bootstrapped ensemble so that a majority of its classifiers are biased as well as being diverse, and intentionally fail to predict classes of bias-conflicting data accordingly. The consensus within the committee on prediction difficulty thus provides a reliable cue for identifying and weighting bias-conflicting data. Moreover, the committee is also trained with knowledge transferred from the main classifier so that it gradually becomes debiased along with the main classifier and emphasizes more difficult data as training progresses. On five real-world datasets, our method outperforms existing methods using no spurious attribute label like ours and even surpasses those relying on bias labels occasionally.