 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Culturally Aligned LLMs through Ontology-Guided Multi-Agent Reasoning
Jan 29, 2026Large Language Models (LLMs) increasingly support culturally sensitive decision making, yet often exhibit misalignment due to skewed pretraining data and the absence of structured value representations. Existing methods can steer outputs, but often lack demographic grounding and treat values as independent, unstructured signals, reducing consistency and interpretability. We propose OG-MAR, an Ontology-Guided Multi-Agent Reasoning framework. OG-MAR summarizes respondent-specific values from the World Values Survey (WVS) and constructs a global cultural ontology by eliciting relations over a fixed taxonomy via competency questions. At inference time, it retrieves ontology-consistent relations and demographically similar profiles to instantiate multiple value-persona agents, whose outputs are synthesized by a judgment agent that enforces ontology consistency and demographic proximity. Experiments on regional social-survey benchmarks across four LLM backbones show that OG-MAR improves cultural alignment and robustness over competitive baselines, while producing more transparent reasoning traces.
Patch-wise Retrieval: A Bag of Practical Techniques for Instance-level Matching
Dec 14, 2025Instance-level image retrieval aims to find images containing the same object as a given query, despite variations in size, position, or appearance. To address this challenging task, we propose Patchify, a simple yet effective patch-wise retrieval framework that offers high performance, scalability, and interpretability without requiring fine-tuning. Patchify divides each database image into a small number of structured patches and performs retrieval by comparing these local features with a global query descriptor, enabling accurate and spatially grounded matching. To assess not just retrieval accuracy but also spatial correctness, we introduce LocScore, a localization-aware metric that quantifies whether the retrieved region aligns with the target object. This makes LocScore a valuable diagnostic tool for understanding and improving retrieval behavior. We conduct extensive experiments across multiple benchmarks, backbones, and region selection strategies, showing that Patchify outperforms global methods and complements state-of-the-art reranking pipelines. Furthermore, we apply Product Quantization for efficient large-scale retrieval and highlight the importance of using informative features during compression, which significantly boosts performance. Project website: https://wons20k.github.io/PatchwiseRetrieval/
CSIT-Free Multi-Group Multicast Transmission in Overloaded mmWave Systems
Nov 09, 2025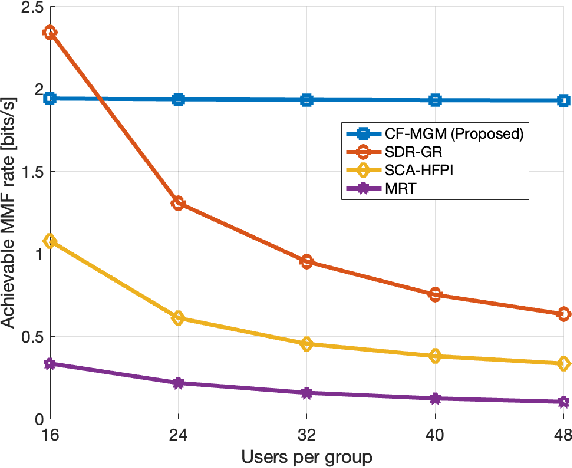
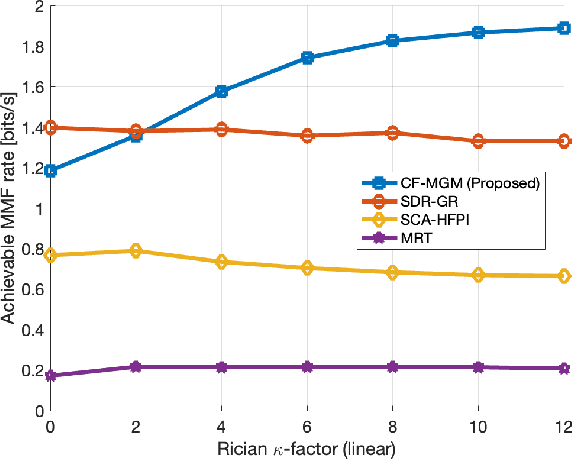
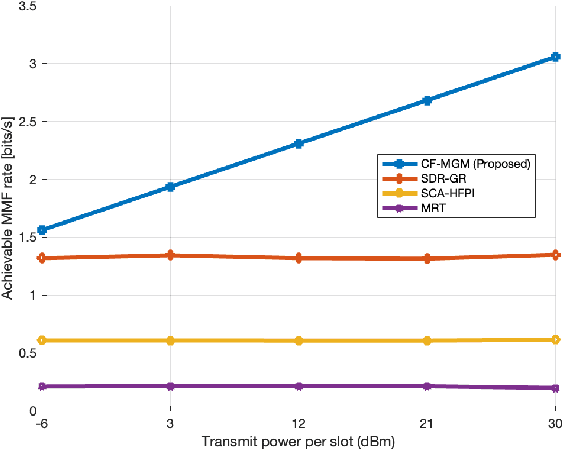
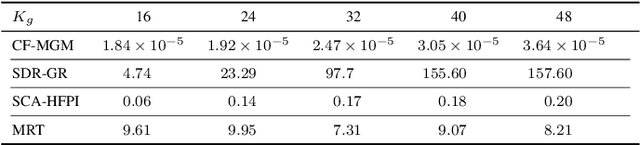
In this paper, we investigate the downlink multi-group multicast (MGM) transmission problem in overloaded mmWave systems. In particular, the conventional MGM beamforming requires substantial computational complexity and feedback (or pilot) overhead for acquisition of channel state information at the transmitter (CSIT), while simultaneous interference management and multicast beamforming optimization across multi-group inevitably incurs a significant rate loss. To address this, we propose a CSIT-free MGM (CF-MGM) transmission that eliminates the need for a complex CSIT acquisition. A deterministic CSIT-free precoding and proposed closed-form power allocation based on max-min fairness (MMF) allow each user to detect the common multicast stream completely canceling the inter-group interference with a significantly low complexity. Simulation results demonstrate the superiority and scalability of the proposed CF-MGM for the achievable rate and increase of users in a group outperforming the existing CSIT-based methods.
CSIT-Free Downlink Transmission for mmWave MU-MISO Systems in High-Mobility Scenario
Sep 19, 2025This paper investigates the downlink (DL) transmission in millimeter-wave (mmWave) multi-user multiple-input single-output (MU-MISO) systems especially focusing on a high speed mobile scenario. To complete the DL transmission within an extremely short channel coherence time, we propose a novel DL transmission framework that eliminates the need for channel state information at the transmitter (CSIT), of which acquisition process requires a substantial overhead, instead fully exploiting the given channel coherence time. Harnessing the characteristic of mmWave channel and uniquely designed CSIT-free unitary precoding, we propose a symbol detection method along with the simultaneous CSI at the receiver (CSIR) and Doppler shift estimation method to completely cancel the interferences while achieving a full combining gain. Via simulations, we demonstrate the effectiveness of the proposed method comparing with the existing baselines.
Enhancing Visual Classification using Comparative Descriptors
Nov 08, 2024



The performance of vision-language models (VLMs), such as CLIP, in visual classification tasks, has been enhanced by leveraging semantic knowledge from large language models (LLMs), including GPT. Recent studies have shown that in zero-shot classification tasks, descriptors incorporating additional cues, high-level concepts, or even random characters often outperform those using only the category name. In many classification tasks, while the top-1 accuracy may be relatively low, the top-5 accuracy is often significantly higher. This gap implies that most misclassifications occur among a few similar classes, highlighting the model's difficulty in distinguishing between classes with subtle differences. To address this challenge, we introduce a novel concept of comparative descriptors. These descriptors emphasize the unique features of a target class against its most similar classes, enhancing differentiation. By generating and integrating these comparative descriptors into the classification framework, we refine the semantic focus and improve classification accuracy. An additional filtering process ensures that these descriptors are closer to the image embeddings in the CLIP space, further enhancing performance. Our approach demonstrates improved accuracy and robustness in visual classification tasks by addressing the specific challenge of subtle inter-class differences.
BEAF: Observing BEfore-AFter Changes to Evaluate Hallucination in Vision-language Models
Jul 18, 2024



Vision language models (VLMs) perceive the world through a combination of a visual encoder and a large language model (LLM). The visual encoder, pre-trained on large-scale vision-text datasets, provides zero-shot generalization to visual data, and the LLM endows its high reasoning ability to VLMs. It leads VLMs to achieve high performance on wide benchmarks without fine-tuning, exhibiting zero or few-shot capability. However, recent studies show that VLMs are vulnerable to hallucination. This undesirable behavior degrades reliability and credibility, thereby making users unable to fully trust the output from VLMs. To enhance trustworthiness and better tackle the hallucination of VLMs, we curate a new evaluation dataset, called the BEfore-AFter hallucination dataset (BEAF), and introduce new metrics: True Understanding (TU), IGnorance (IG), StuBbornness (SB), and InDecision (ID). Unlike prior works that focus only on constructing questions and answers, the key idea of our benchmark is to manipulate visual scene information by image editing models and to design the metrics based on scene changes. This allows us to clearly assess whether VLMs correctly understand a given scene by observing the ability to perceive changes. We also visualize image-wise object relationship by virtue of our two-axis view: vision and text. Upon evaluating VLMs with our dataset, we observed that our metrics reveal different aspects of VLM hallucination that have not been reported before. Project page: \url{https://beafbench.github.io/}
Exploiting Synthetic Data for Data Imbalance Problems: Baselines from a Data Perspective
Aug 02, 2023



We live in a vast ocean of data, and deep neural networks are no exception to this. However, this data exhibits an inherent phenomenon of imbalance. This imbalance poses a risk of deep neural networks producing biased predictions, leading to potentially severe ethical and social consequences. To address these challenges, we believe that the use of generative models is a promising approach for comprehending tasks, given the remarkable advancements demonstrated by recent diffusion models in generating high-quality images. In this work, we propose a simple yet effective baseline, SYNAuG, that utilizes synthetic data as a preliminary step before employing task-specific algorithms to address data imbalance problems. This straightforward approach yields impressive performance on datasets such as CIFAR100-LT, ImageNet100-LT, UTKFace, and Waterbird, surpassing the performance of existing task-specific methods. While we do not claim that our approach serves as a complete solution to the problem of data imbalance, we argue that supplementing the existing data with synthetic data proves to be an effective and crucial preliminary step in addressing data imbalance concerns.