 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Accurate and Detailed Captions for High-Resolution Images
Oct 31, 2025
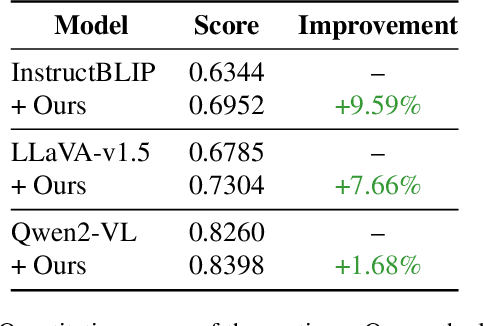


Vision-language models (VLMs) often struggle to generate accurate and detailed captions for high-resolution images since they are typically pre-trained on low-resolution inputs (e.g., 224x224 or 336x336 pixels). Downscaling high-resolution images to these dimensions may result in the loss of visual details and the omission of important objects. To address this limitation, we propose a novel pipeline that integrates vision-language models, large language models (LLMs), and object detection systems to enhance caption quality. Our proposed pipeline refines captions through a novel, multi-stage process. Given a high-resolution image, an initial caption is first generated using a VLM, and key objects in the image are then identified by an LLM. The LLM predicts additional objects likely to co-occur with the identified key objects, and these predictions are verified by object detection systems. Newly detected objects not mentioned in the initial caption undergo focused, region-specific captioning to ensure they are incorporated. This process enriches caption detail while reducing hallucinations by removing references to undetected objects. We evaluate the enhanced captions using pairwise comparison and quantitative scoring from large multimodal models, along with a benchmark for hallucination detection. Experiments on a curated dataset of high-resolution images demonstrate that our pipeline produces more detailed and reliable image captions while effectively minimizing hallucinations.
Enhancing Visual Classification using Comparative Descriptors
Nov 08, 2024



The performance of vision-language models (VLMs), such as CLIP, in visual classification tasks, has been enhanced by leveraging semantic knowledge from large language models (LLMs), including GPT. Recent studies have shown that in zero-shot classification tasks, descriptors incorporating additional cues, high-level concepts, or even random characters often outperform those using only the category name. In many classification tasks, while the top-1 accuracy may be relatively low, the top-5 accuracy is often significantly higher. This gap implies that most misclassifications occur among a few similar classes, highlighting the model's difficulty in distinguishing between classes with subtle differences. To address this challenge, we introduce a novel concept of comparative descriptors. These descriptors emphasize the unique features of a target class against its most similar classes, enhancing differentiation. By generating and integrating these comparative descriptors into the classification framework, we refine the semantic focus and improve classification accuracy. An additional filtering process ensures that these descriptors are closer to the image embeddings in the CLIP space, further enhancing performance. Our approach demonstrates improved accuracy and robustness in visual classification tasks by addressing the specific challenge of subtle inter-class differences.
RPM-Net: Robust Pixel-Level Matching Networks for Self-Supervised Video Object Segmentation
Oct 10, 2019
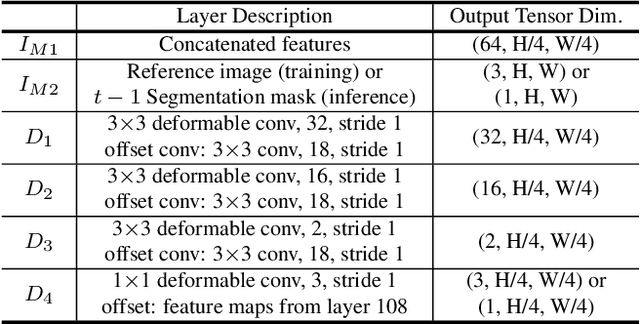


In this paper, we introduce a self-supervised approach for video object segmentation without human labeled data.Specifically, we present Robust Pixel-level Matching Net-works (RPM-Net), a novel deep architecture that matches pixels between adjacent frames, using only color information from unlabeled videos for training. Technically, RPM-Net can be separated in two main modules. The embed-ding module first projects input images into high dimensional embedding space. Then the matching module with deformable convolution layers matches pixels between reference and target frames based on the embedding features.Unlike previous methods using deformable convolution, our matching module adopts deformable convolution to focus on similar features in spatio-temporally neighboring pixels.Our experiments show that the selective feature sampling improves the robustness to challenging problems in video object segmentation such as camera shake, fast motion, deformation, and occlusion. Also, we carry out comprehensive experiments on three public datasets (i.e., DAVIS-2017,SegTrack-v2, and Youtube-Objects) and achieve state-of-the-art performance on self-supervised video object seg-mentation. Moreover, we significantly reduce the performance gap between self-supervised and fully-supervised video object segmentation (41.0% vs. 52.5% on DAVIS-2017 validation set)