 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSteering Guidance for Personalized Text-to-Image Diffusion Models
Aug 01, 2025Personalizing text-to-image diffusion models is crucial for adapting the pre-trained models to specific target concepts, enabling diverse image generation. However, fine-tuning with few images introduces an inherent trade-off between aligning with the target distribution (e.g., subject fidelity) and preserving the broad knowledge of the original model (e.g., text editability). Existing sampling guidance methods, such as classifier-free guidance (CFG) and autoguidance (AG), fail to effectively guide the output toward well-balanced space: CFG restricts the adaptation to the target distribution, while AG compromises text alignment. To address these limitations, we propose personalization guidance, a simple yet effective method leveraging an unlearned weak model conditioned on a null text prompt. Moreover, our method dynamically controls the extent of unlearning in a weak model through weight interpolation between pre-trained and fine-tuned models during inference. Unlike existing guidance methods, which depend solely on guidance scales, our method explicitly steers the outputs toward a balanced latent space without additional computational overhead. Experimental results demonstrate that our proposed guidance can improve text alignment and target distribution fidelity, integrating seamlessly with various fine-tuning strategies.
MultiHuman-Testbench: Benchmarking Image Generation for Multiple Humans
Jun 25, 2025Generation of images containing multiple humans, performing complex actions, while preserving their facial identities, is a significant challenge. A major factor contributing to this is the lack of a a dedicated benchmark. To address this, we introduce MultiHuman-Testbench, a novel benchmark for rigorously evaluating generative models for multi-human generation. The benchmark comprises 1800 samples, including carefully curated text prompts, describing a range of simple to complex human actions. These prompts are matched with a total of 5,550 unique human face images, sampled uniformly to ensure diversity across age, ethnic background, and gender. Alongside captions, we provide human-selected pose conditioning images which accurately match the prompt. We propose a multi-faceted evaluation suite employing four key metrics to quantify face count, ID similarity, prompt alignment, and action detection. We conduct a thorough evaluation of a diverse set of models, including zero-shot approaches and training-based methods, with and without regional priors. We also propose novel techniques to incorporate image and region isolation using human segmentation and Hungarian matching, significantly improving ID similarity. Our proposed benchmark and key findings provide valuable insights and a standardized tool for advancing research in multi-human image generation.
Hollowed Net for On-Device Personalization of Text-to-Image Diffusion Models
Nov 02, 2024Recent advancements in text-to-image diffusion models have enabled the personalization of these models to generate custom images from textual prompts. This paper presents an efficient LoRA-based personalization approach for on-device subject-driven generation, where pre-trained diffusion models are fine-tuned with user-specific data on resource-constrained devices. Our method, termed Hollowed Net, enhances memory efficiency during fine-tuning by modifying the architecture of a diffusion U-Net to temporarily remove a fraction of its deep layers, creating a hollowed structure. This approach directly addresses on-device memory constraints and substantially reduces GPU memory requirements for training, in contrast to previous methods that primarily focus on minimizing training steps and reducing the number of parameters to update. Additionally, the personalized Hollowed Net can be transferred back into the original U-Net, enabling inference without additional memory overhead. Quantitative and qualitative analyses demonstrate that our approach not only reduces training memory to levels as low as those required for inference but also maintains or improves personalization performance compared to existing methods.
Feature Diversification and Adaptation for Federated Domain Generalization
Jul 11, 2024



Federated learning, a distributed learning paradigm, utilizes multiple clients to build a robust global model. In real-world applications, local clients often operate within their limited domains, leading to a `domain shift' across clients. Privacy concerns limit each client's learning to its own domain data, which increase the risk of overfitting. Moreover, the process of aggregating models trained on own limited domain can be potentially lead to a significant degradation in the global model performance. To deal with these challenges, we introduce the concept of federated feature diversification. Each client diversifies the own limited domain data by leveraging global feature statistics, i.e., the aggregated average statistics over all participating clients, shared through the global model's parameters. This data diversification helps local models to learn client-invariant representations while preserving privacy. Our resultant global model shows robust performance on unseen test domain data. To enhance performance further, we develop an instance-adaptive inference approach tailored for test domain data. Our proposed instance feature adapter dynamically adjusts feature statistics to align with the test input, thereby reducing the domain gap between the test and training domains. We show that our method achieves state-of-the-art performance on several domain generalization benchmarks within a federated learning setting.
Progressive Random Convolutions for Single Domain Generalization
Apr 02, 2023Single domain generalization aims to train a generalizable model with only one source domain to perform well on arbitrary unseen target domains. Image augmentation based on Random Convolutions (RandConv), consisting of one convolution layer randomly initialized for each mini-batch, enables the model to learn generalizable visual representations by distorting local textures despite its simple and lightweight structure. However, RandConv has structural limitations in that the generated image easily loses semantics as the kernel size increases, and lacks the inherent diversity of a single convolution operation. To solve the problem, we propose a Progressive Random Convolution (Pro-RandConv) method that recursively stacks random convolution layers with a small kernel size instead of increasing the kernel size. This progressive approach can not only mitigate semantic distortions by reducing the influence of pixels away from the center in the theoretical receptive field, but also create more effective virtual domains by gradually increasing the style diversity. In addition, we develop a basic random convolution layer into a random convolution block including deformable offsets and affine transformation to support texture and contrast diversification, both of which are also randomly initialized. Without complex generators or adversarial learning, we demonstrate that our simple yet effective augmentation strategy outperforms state-of-the-art methods on single domain generalization benchmarks.
Improving Test-Time Adaptation via Shift-agnostic Weight Regularization and Nearest Source Prototypes
Jul 24, 2022
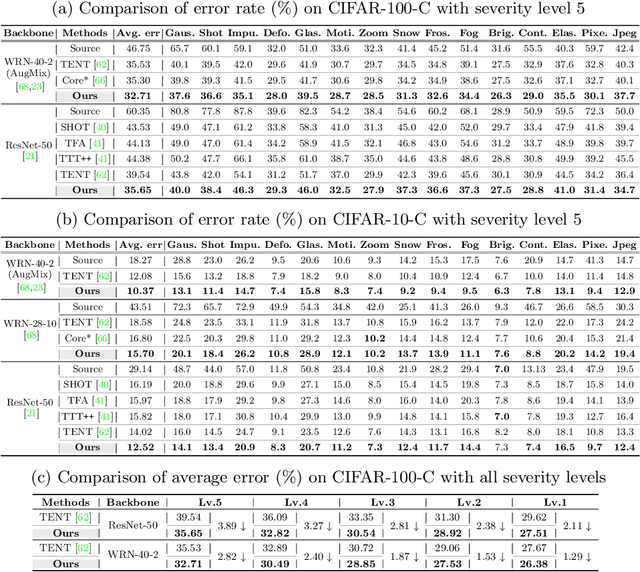

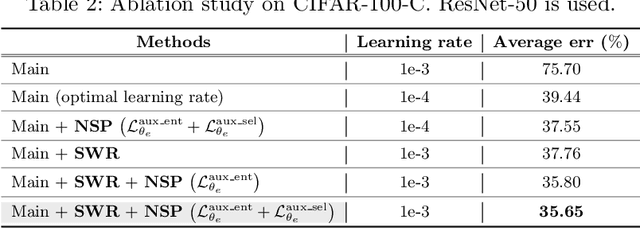
This paper proposes a novel test-time adaptation strategy that adjusts the model pre-trained on the source domain using only unlabeled online data from the target domain to alleviate the performance degradation due to the distribution shift between the source and target domains. Adapting the entire model parameters using the unlabeled online data may be detrimental due to the erroneous signals from an unsupervised objective. To mitigate this problem, we propose a shift-agnostic weight regularization that encourages largely updating the model parameters sensitive to distribution shift while slightly updating those insensitive to the shift, during test-time adaptation. This regularization enables the model to quickly adapt to the target domain without performance degradation by utilizing the benefit of a high learning rate. In addition, we present an auxiliary task based on nearest source prototypes to align the source and target features, which helps reduce the distribution shift and leads to further performance improvement. We show that our method exhibits state-of-the-art performance on various standard benchmarks and even outperforms its supervised counterpart.
Learning to Discriminate Information for Online Action Detection: Analysis and Application
Sep 09, 2021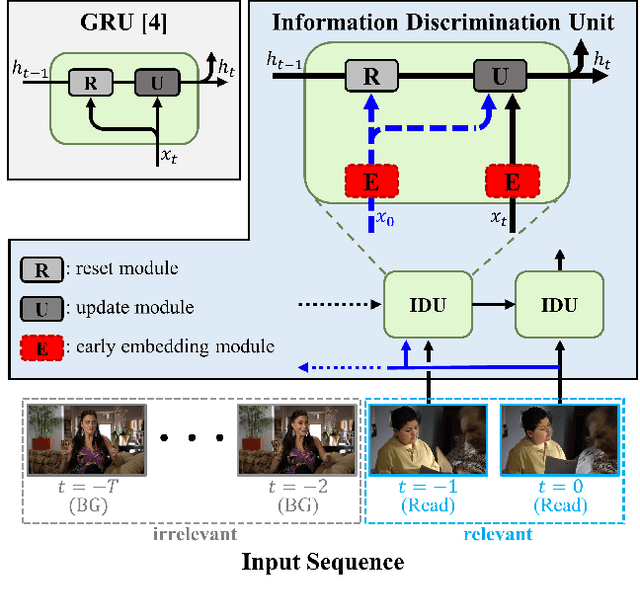
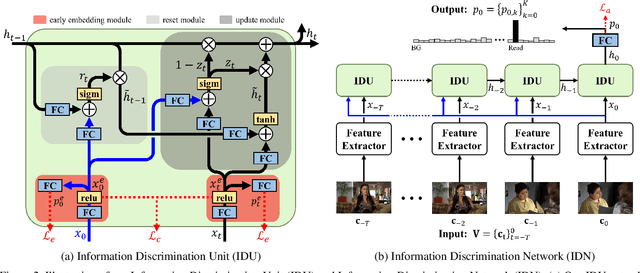
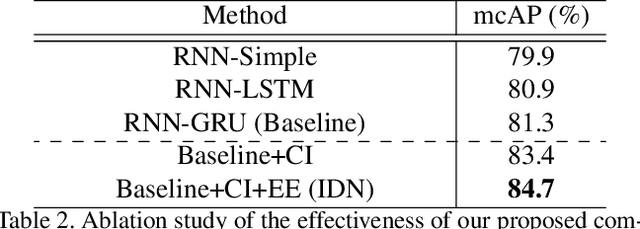
Online action detection, which aims to identify an ongoing action from a streaming video, is an important subject in real-world applications. For this task, previous methods use recurrent neural networks for modeling temporal relations in an input sequence. However, these methods overlook the fact that the input image sequence includes not only the action of interest but background and irrelevant actions. This would induce recurrent units to accumulate unnecessary information for encoding features on the action of interest. To overcome this problem, we propose a novel recurrent unit, named Information Discrimination Unit (IDU), which explicitly discriminates the information relevancy between an ongoing action and others to decide whether to accumulate the input information. This enables learning more discriminative representations for identifying an ongoing action. In this paper, we further present a new recurrent unit, called Information Integration Unit (IIU), for action anticipation. Our IIU exploits the outputs from IDU as pseudo action labels as well as RGB frames to learn enriched features of observed actions effectively. In experiments on TVSeries and THUMOS-14, the proposed methods outperform state-of-the-art methods by a significant margin in online action detection and action anticipation. Moreover, we demonstrate the effectiveness of the proposed units by conducting comprehensive ablation studies.
Few-shot Open-set Recognition by Transformation Consistency
Mar 02, 2021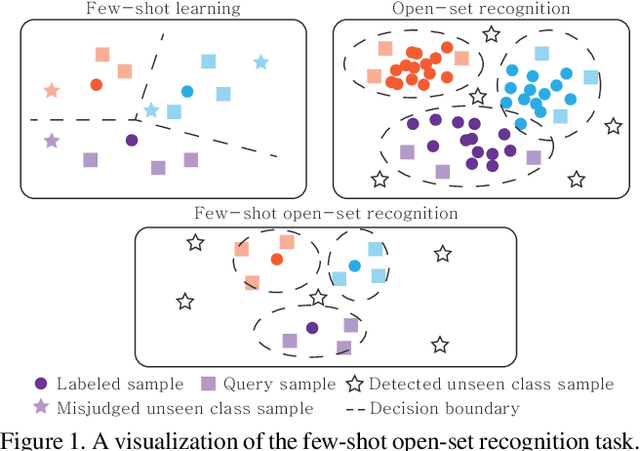
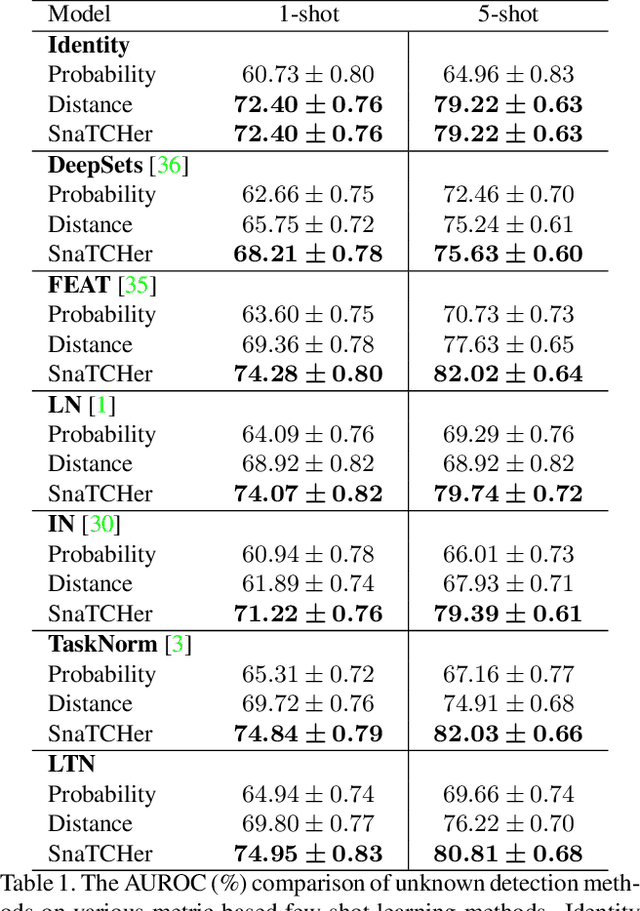
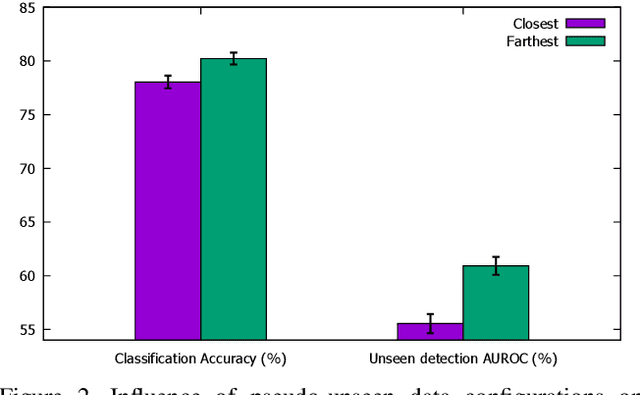
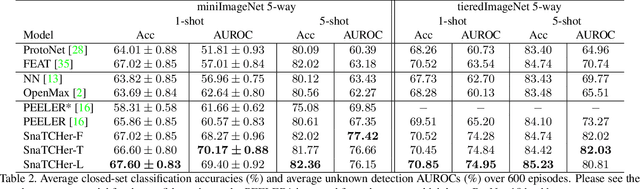
In this paper, we attack a few-shot open-set recognition (FSOSR) problem, which is a combination of few-shot learning (FSL) and open-set recognition (OSR). It aims to quickly adapt a model to a given small set of labeled samples while rejecting unseen class samples. Since OSR requires rich data and FSL considers closed-set classification, existing OSR and FSL methods show poor performances in solving FSOSR problems. The previous FSOSR method follows the pseudo-unseen class sample-based methods, which collect pseudo-unseen samples from the other dataset or synthesize samples to model unseen class representations. However, this approach is heavily dependent on the composition of the pseudo samples. In this paper, we propose a novel unknown class sample detector, named SnaTCHer, that does not require pseudo-unseen samples. Based on the transformation consistency, our method measures the difference between the transformed prototypes and a modified prototype set. The modified set is composed by replacing a query feature and its predicted class prototype. SnaTCHer rejects samples with large differences to the transformed prototypes. Our method alters the unseen class distribution estimation problem to a relative feature transformation problem, independent of pseudo-unseen class samples. We investigate our SnaTCHer with various prototype transformation methods and observe that our method consistently improves unseen class sample detection performance without closed-set classification reduction.
Meta Batch-Instance Normalization for Generalizable Person Re-Identification
Nov 30, 2020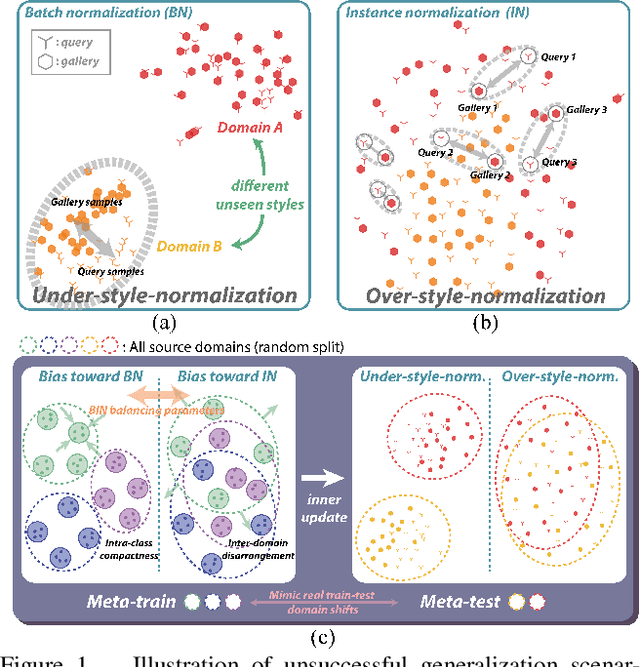
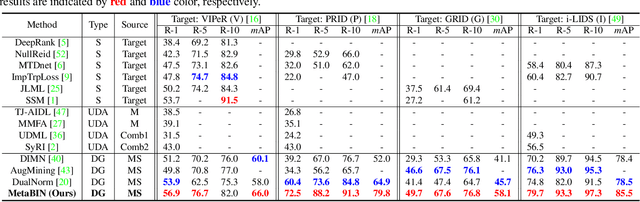
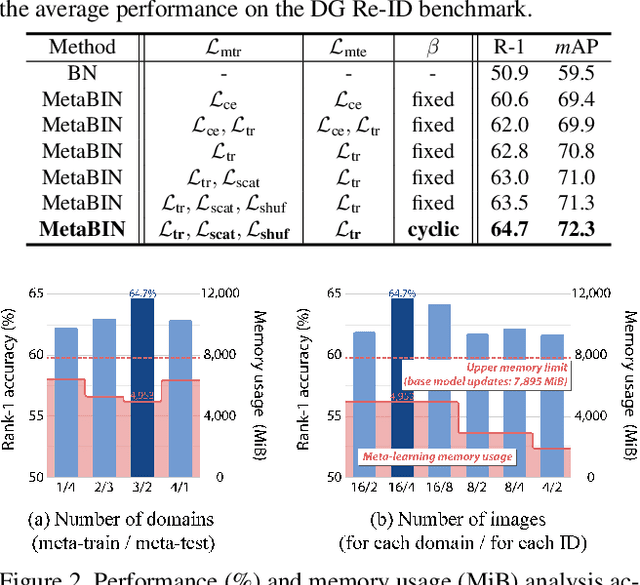
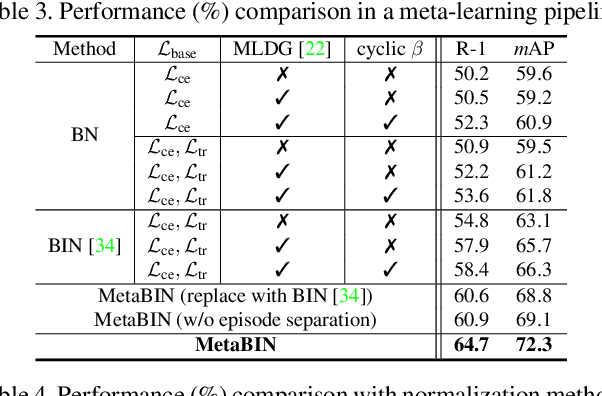
Although supervised person re-identification (Re-ID) methods have shown impressive performance, they suffer from a poor generalization capability on unseen domains. Therefore, generalizable Re-ID has recently attracted growing attention. Many existing methods have employed an instance normalization technique to reduce style variations, but the loss of discriminative information could not be avoided. In this paper, we propose a novel generalizable Re-ID framework, named Meta Batch-Instance Normalization (MetaBIN). Our main idea is to generalize normalization layers by simulating unsuccessful generalization scenarios beforehand in the meta-learning pipeline. To this end, we combine learnable batch-instance normalization layers with meta-learning and investigate the challenging cases caused by both batch and instance normalization layers. Moreover, we diversify the virtual simulations via our meta-train loss accompanied by a cyclic inner-updating manner to boost generalization capability. After all, the MetaBIN framework prevents our model from overfitting to the given source styles and improves the generalization capability to unseen domains without additional data augmentation or complicated network design. Extensive experimental results show that our model outperforms the state-of-the-art methods on the large-scale domain generalization Re-ID benchmark.
Robust Long-Term Object Tracking via Improved Discriminative Model Prediction
Aug 25, 2020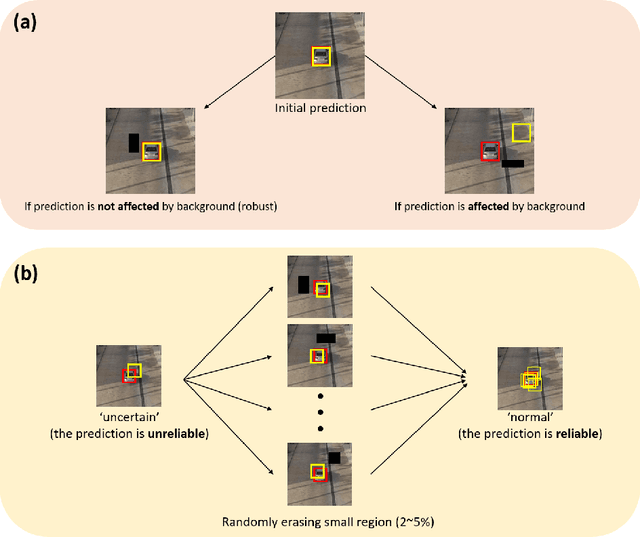
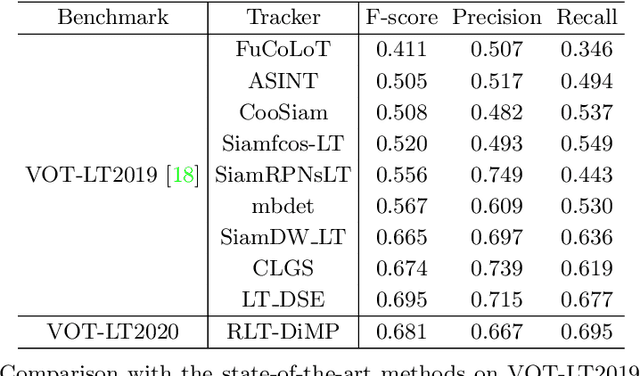


We propose an improved discriminative model prediction method for robust long-term tracking based on a pre-trained short-term tracker. The baseline pre-trained short-term tracker is SuperDiMP which combines the bounding-box regressor of PrDiMP with the standard DiMP classifier. Our tracker RLT-DiMP improves SuperDiMP in the following three aspects: (1) Uncertainty reduction using random erasing: To make our model robust, we exploit an agreement from multiple images after erasing random small rectangular areas as a certainty. And then, we correct the tracking state of our model accordingly. (2) Random search with spatio-temporal constraints: we propose a robust random search method with a score penalty applied to prevent the problem of sudden detection at a distance. (3) Background augmentation for more discriminative feature learning: We augment various backgrounds that are not included in the search area to train a more robust model in the background clutter. In experiments on the VOT-LT2020 benchmark dataset, the proposed method achieves comparable performance to the state-of-the-art long-term trackers. The source code is available at: https://github.com/bismex/RLT-DIMP.