 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemory-Efficient Fine-Tuning Diffusion Transformers via Dynamic Patch Sampling and Block Skipping
Mar 21, 2026Diffusion Transformers (DiTs) have significantly enhanced text-to-image (T2I) generation quality, enabling high-quality personalized content creation. However, fine-tuning these models requires substantial computational complexity and memory, limiting practical deployment under resource constraints. To tackle these challenges, we propose a memory-efficient fine-tuning framework called DiT-BlockSkip, integrating timestep-aware dynamic patch sampling and block skipping by precomputing residual features. Our dynamic patch sampling strategy adjusts patch sizes based on the diffusion timestep, then resizes the cropped patches to a fixed lower resolution. This approach reduces forward & backward memory usage while allowing the model to capture global structures at higher timesteps and fine-grained details at lower timesteps. The block skipping mechanism selectively fine-tunes essential transformer blocks and precomputes residual features for the skipped blocks, significantly reducing training memory. To identify vital blocks for personalization, we introduce a block selection strategy based on cross-attention masking. Evaluations demonstrate that our approach achieves competitive personalization performance qualitatively and quantitatively, while reducing memory usage substantially, moving toward on-device feasibility (e.g., smartphones, IoT devices) for large-scale diffusion transformers.
LoRA-X: Bridging Foundation Models with Training-Free Cross-Model Adaptation
Jan 27, 2025



The rising popularity of large foundation models has led to a heightened demand for parameter-efficient fine-tuning methods, such as Low-Rank Adaptation (LoRA), which offer performance comparable to full model fine-tuning while requiring only a few additional parameters tailored to the specific base model. When such base models are deprecated and replaced, all associated LoRA modules must be retrained, requiring access to either the original training data or a substantial amount of synthetic data that mirrors the original distribution. However, the original data is often inaccessible due to privacy or licensing issues, and generating synthetic data may be impractical and insufficiently representative. These factors complicate the fine-tuning process considerably. To address this challenge, we introduce a new adapter, Cross-Model Low-Rank Adaptation (LoRA-X), which enables the training-free transfer of LoRA parameters across source and target models, eliminating the need for original or synthetic training data. Our approach imposes the adapter to operate within the subspace of the source base model. This constraint is necessary because our prior knowledge of the target model is limited to its weights, and the criteria for ensuring the adapter's transferability are restricted to the target base model's weights and subspace. To facilitate the transfer of LoRA parameters of the source model to a target model, we employ the adapter only in the layers of the target model that exhibit an acceptable level of subspace similarity. Our extensive experiments demonstrate the effectiveness of LoRA-X for text-to-image generation, including Stable Diffusion v1.5 and Stable Diffusion XL.
Hollowed Net for On-Device Personalization of Text-to-Image Diffusion Models
Nov 02, 2024Recent advancements in text-to-image diffusion models have enabled the personalization of these models to generate custom images from textual prompts. This paper presents an efficient LoRA-based personalization approach for on-device subject-driven generation, where pre-trained diffusion models are fine-tuned with user-specific data on resource-constrained devices. Our method, termed Hollowed Net, enhances memory efficiency during fine-tuning by modifying the architecture of a diffusion U-Net to temporarily remove a fraction of its deep layers, creating a hollowed structure. This approach directly addresses on-device memory constraints and substantially reduces GPU memory requirements for training, in contrast to previous methods that primarily focus on minimizing training steps and reducing the number of parameters to update. Additionally, the personalized Hollowed Net can be transferred back into the original U-Net, enabling inference without additional memory overhead. Quantitative and qualitative analyses demonstrate that our approach not only reduces training memory to levels as low as those required for inference but also maintains or improves personalization performance compared to existing methods.
PosSAM: Panoptic Open-vocabulary Segment Anything
Mar 14, 2024
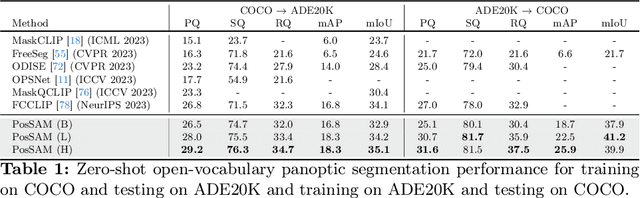

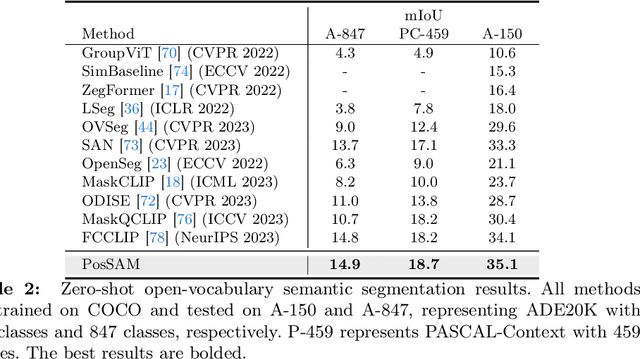
In this paper, we introduce an open-vocabulary panoptic segmentation model that effectively unifies the strengths of the Segment Anything Model (SAM) with the vision-language CLIP model in an end-to-end framework. While SAM excels in generating spatially-aware masks, it's decoder falls short in recognizing object class information and tends to oversegment without additional guidance. Existing approaches address this limitation by using multi-stage techniques and employing separate models to generate class-aware prompts, such as bounding boxes or segmentation masks. Our proposed method, PosSAM is an end-to-end model which leverages SAM's spatially rich features to produce instance-aware masks and harnesses CLIP's semantically discriminative features for effective instance classification. Specifically, we address the limitations of SAM and propose a novel Local Discriminative Pooling (LDP) module leveraging class-agnostic SAM and class-aware CLIP features for unbiased open-vocabulary classification. Furthermore, we introduce a Mask-Aware Selective Ensembling (MASE) algorithm that adaptively enhances the quality of generated masks and boosts the performance of open-vocabulary classification during inference for each image. We conducted extensive experiments to demonstrate our methods strong generalization properties across multiple datasets, achieving state-of-the-art performance with substantial improvements over SOTA open-vocabulary panoptic segmentation methods. In both COCO to ADE20K and ADE20K to COCO settings, PosSAM outperforms the previous state-of-the-art methods by a large margin, 2.4 PQ and 4.6 PQ, respectively. Project Website: https://vibashan.github.io/possam-web/.
Towards Open-Set Test-Time Adaptation Utilizing the Wisdom of Crowds in Entropy Minimization
Sep 04, 2023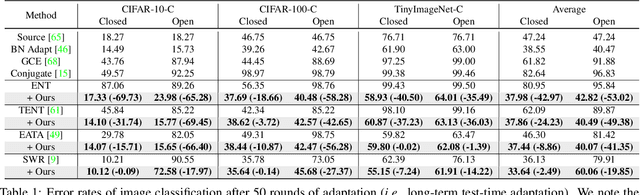
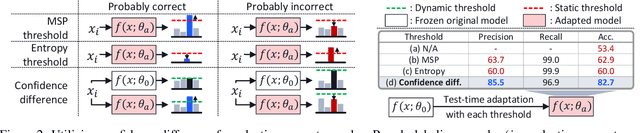
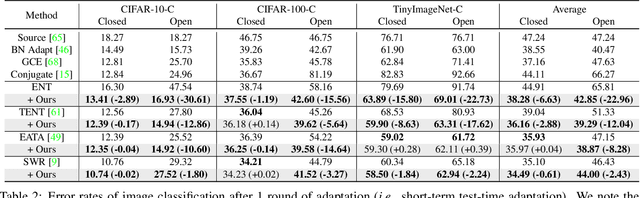
Test-time adaptation (TTA) methods, which generally rely on the model's predictions (e.g., entropy minimization) to adapt the source pretrained model to the unlabeled target domain, suffer from noisy signals originating from 1) incorrect or 2) open-set predictions. Long-term stable adaptation is hampered by such noisy signals, so training models without such error accumulation is crucial for practical TTA. To address these issues, including open-set TTA, we propose a simple yet effective sample selection method inspired by the following crucial empirical finding. While entropy minimization compels the model to increase the probability of its predicted label (i.e., confidence values), we found that noisy samples rather show decreased confidence values. To be more specific, entropy minimization attempts to raise the confidence values of an individual sample's prediction, but individual confidence values may rise or fall due to the influence of signals from numerous other predictions (i.e., wisdom of crowds). Due to this fact, noisy signals misaligned with such 'wisdom of crowds', generally found in the correct signals, fail to raise the individual confidence values of wrong samples, despite attempts to increase them. Based on such findings, we filter out the samples whose confidence values are lower in the adapted model than in the original model, as they are likely to be noisy. Our method is widely applicable to existing TTA methods and improves their long-term adaptation performance in both image classification (e.g., 49.4% reduced error rates with TENT) and semantic segmentation (e.g., 11.7% gain in mIoU with TENT).
Progressive Random Convolutions for Single Domain Generalization
Apr 02, 2023Single domain generalization aims to train a generalizable model with only one source domain to perform well on arbitrary unseen target domains. Image augmentation based on Random Convolutions (RandConv), consisting of one convolution layer randomly initialized for each mini-batch, enables the model to learn generalizable visual representations by distorting local textures despite its simple and lightweight structure. However, RandConv has structural limitations in that the generated image easily loses semantics as the kernel size increases, and lacks the inherent diversity of a single convolution operation. To solve the problem, we propose a Progressive Random Convolution (Pro-RandConv) method that recursively stacks random convolution layers with a small kernel size instead of increasing the kernel size. This progressive approach can not only mitigate semantic distortions by reducing the influence of pixels away from the center in the theoretical receptive field, but also create more effective virtual domains by gradually increasing the style diversity. In addition, we develop a basic random convolution layer into a random convolution block including deformable offsets and affine transformation to support texture and contrast diversification, both of which are also randomly initialized. Without complex generators or adversarial learning, we demonstrate that our simple yet effective augmentation strategy outperforms state-of-the-art methods on single domain generalization benchmarks.
DejaVu: Conditional Regenerative Learning to Enhance Dense Prediction
Mar 02, 2023We present DejaVu, a novel framework which leverages conditional image regeneration as additional supervision during training to improve deep networks for dense prediction tasks such as segmentation, depth estimation, and surface normal prediction. First, we apply redaction to the input image, which removes certain structural information by sparse sampling or selective frequency removal. Next, we use a conditional regenerator, which takes the redacted image and the dense predictions as inputs, and reconstructs the original image by filling in the missing structural information. In the redacted image, structural attributes like boundaries are broken while semantic context is largely preserved. In order to make the regeneration feasible, the conditional generator will then require the structure information from the other input source, i.e., the dense predictions. As such, by including this conditional regeneration objective during training, DejaVu encourages the base network to learn to embed accurate scene structure in its dense prediction. This leads to more accurate predictions with clearer boundaries and better spatial consistency. When it is feasible to leverage additional computation, DejaVu can be extended to incorporate an attention-based regeneration module within the dense prediction network, which further improves accuracy. Through extensive experiments on multiple dense prediction benchmarks such as Cityscapes, COCO, ADE20K, NYUD-v2, and KITTI, we demonstrate the efficacy of employing DejaVu during training, as it outperforms SOTA methods at no added computation cost.
TransAdapt: A Transformative Framework for Online Test Time Adaptive Semantic Segmentation
Feb 24, 2023Test-time adaptive (TTA) semantic segmentation adapts a source pre-trained image semantic segmentation model to unlabeled batches of target domain test images, different from real-world, where samples arrive one-by-one in an online fashion. To tackle online settings, we propose TransAdapt, a framework that uses transformer and input transformations to improve segmentation performance. Specifically, we pre-train a transformer-based module on a segmentation network that transforms unsupervised segmentation output to a more reliable supervised output, without requiring test-time online training. To also facilitate test-time adaptation, we propose an unsupervised loss based on the transformed input that enforces the model to be invariant and equivariant to photometric and geometric perturbations, respectively. Overall, our framework produces higher quality segmentation masks with up to 17.6% and 2.8% mIOU improvement over no-adaptation and competitive baselines, respectively.
Test-time Adaptation vs. Training-time Generalization: A Case Study in Human Instance Segmentation using Keypoints Estimation
Dec 12, 2022



We consider the problem of improving the human instance segmentation mask quality for a given test image using keypoints estimation. We compare two alternative approaches. The first approach is a test-time adaptation (TTA) method, where we allow test-time modification of the segmentation network's weights using a single unlabeled test image. In this approach, we do not assume test-time access to the labeled source dataset. More specifically, our TTA method consists of using the keypoints estimates as pseudo labels and backpropagating them to adjust the backbone weights. The second approach is a training-time generalization (TTG) method, where we permit offline access to the labeled source dataset but not the test-time modification of weights. Furthermore, we do not assume the availability of any images from or knowledge about the target domain. Our TTG method consists of augmenting the backbone features with those generated by the keypoints head and feeding the aggregate vector to the mask head. Through a comprehensive set of ablations, we evaluate both approaches and identify several factors limiting the TTA gains. In particular, we show that in the absence of a significant domain shift, TTA may hurt and TTG show only a small gain in performance, whereas for a large domain shift, TTA gains are smaller and dependent on the heuristics used, while TTG gains are larger and robust to architectural choices.
Domain Agnostic Few-shot Learning for Speaker Verification
Jun 28, 2022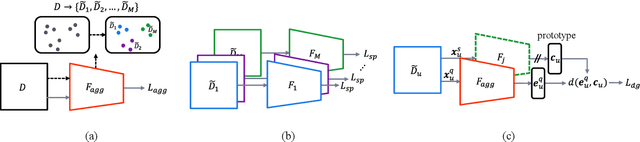
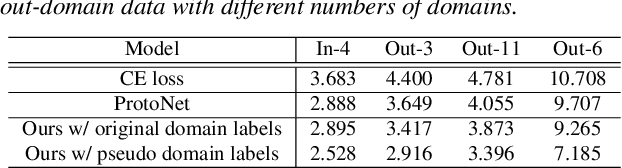
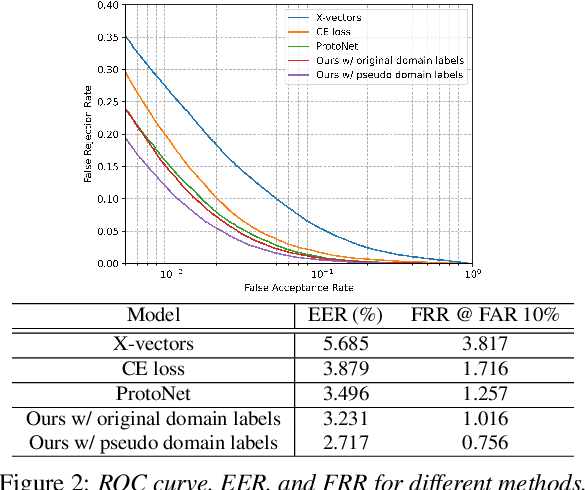
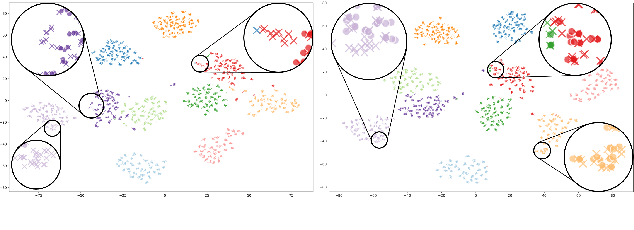
Deep learning models for verification systems often fail to generalize to new users and new environments, even though they learn highly discriminative features. To address this problem, we propose a few-shot domain generalization framework that learns to tackle distribution shift for new users and new domains. Our framework consists of domain-specific and domain-aggregation networks, which are the experts on specific and combined domains, respectively. By using these networks, we generate episodes that mimic the presence of both novel users and novel domains in the training phase to eventually produce better generalization. To save memory, we reduce the number of domain-specific networks by clustering similar domains together. Upon extensive evaluation on artificially generated noise domains, we can explicitly show generalization ability of our framework. In addition, we apply our proposed methods to the existing competitive architecture on the standard benchmark, which shows further performance improvements.