 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisCo: Reinforcement with Diversity Constraints for Multi-Human Generation
Oct 01, 2025State-of-the-art text-to-image models excel at realism but collapse on multi-human prompts - duplicating faces, merging identities, and miscounting individuals. We introduce DisCo (Reinforcement with Diversity Constraints), the first RL-based framework to directly optimize identity diversity in multi-human generation. DisCo fine-tunes flow-matching models via Group-Relative Policy Optimization (GRPO) with a compositional reward that (i) penalizes intra-image facial similarity, (ii) discourages cross-sample identity repetition, (iii) enforces accurate person counts, and (iv) preserves visual fidelity through human preference scores. A single-stage curriculum stabilizes training as complexity scales, requiring no extra annotations. On the DiverseHumans Testset, DisCo achieves 98.6 Unique Face Accuracy and near-perfect Global Identity Spread - surpassing both open-source and proprietary methods (e.g., Gemini, GPT-Image) while maintaining competitive perceptual quality. Our results establish DisCo as a scalable, annotation-free solution that resolves the long-standing identity crisis in generative models and sets a new benchmark for compositional multi-human generation.
MultiHuman-Testbench: Benchmarking Image Generation for Multiple Humans
Jun 25, 2025Generation of images containing multiple humans, performing complex actions, while preserving their facial identities, is a significant challenge. A major factor contributing to this is the lack of a a dedicated benchmark. To address this, we introduce MultiHuman-Testbench, a novel benchmark for rigorously evaluating generative models for multi-human generation. The benchmark comprises 1800 samples, including carefully curated text prompts, describing a range of simple to complex human actions. These prompts are matched with a total of 5,550 unique human face images, sampled uniformly to ensure diversity across age, ethnic background, and gender. Alongside captions, we provide human-selected pose conditioning images which accurately match the prompt. We propose a multi-faceted evaluation suite employing four key metrics to quantify face count, ID similarity, prompt alignment, and action detection. We conduct a thorough evaluation of a diverse set of models, including zero-shot approaches and training-based methods, with and without regional priors. We also propose novel techniques to incorporate image and region isolation using human segmentation and Hungarian matching, significantly improving ID similarity. Our proposed benchmark and key findings provide valuable insights and a standardized tool for advancing research in multi-human image generation.
SubZero: Composing Subject, Style, and Action via Zero-Shot Personalization
Feb 27, 2025Diffusion models are increasingly popular for generative tasks, including personalized composition of subjects and styles. While diffusion models can generate user-specified subjects performing text-guided actions in custom styles, they require fine-tuning and are not feasible for personalization on mobile devices. Hence, tuning-free personalization methods such as IP-Adapters have progressively gained traction. However, for the composition of subjects and styles, these works are less flexible due to their reliance on ControlNet, or show content and style leakage artifacts. To tackle these, we present SubZero, a novel framework to generate any subject in any style, performing any action without the need for fine-tuning. We propose a novel set of constraints to enhance subject and style similarity, while reducing leakage. Additionally, we propose an orthogonalized temporal aggregation scheme in the cross-attention blocks of denoising model, effectively conditioning on a text prompt along with single subject and style images. We also propose a novel method to train customized content and style projectors to reduce content and style leakage. Through extensive experiments, we show that our proposed approach, while suitable for running on-edge, shows significant improvements over state-of-the-art works performing subject, style and action composition.
LoRA-X: Bridging Foundation Models with Training-Free Cross-Model Adaptation
Jan 27, 2025



The rising popularity of large foundation models has led to a heightened demand for parameter-efficient fine-tuning methods, such as Low-Rank Adaptation (LoRA), which offer performance comparable to full model fine-tuning while requiring only a few additional parameters tailored to the specific base model. When such base models are deprecated and replaced, all associated LoRA modules must be retrained, requiring access to either the original training data or a substantial amount of synthetic data that mirrors the original distribution. However, the original data is often inaccessible due to privacy or licensing issues, and generating synthetic data may be impractical and insufficiently representative. These factors complicate the fine-tuning process considerably. To address this challenge, we introduce a new adapter, Cross-Model Low-Rank Adaptation (LoRA-X), which enables the training-free transfer of LoRA parameters across source and target models, eliminating the need for original or synthetic training data. Our approach imposes the adapter to operate within the subspace of the source base model. This constraint is necessary because our prior knowledge of the target model is limited to its weights, and the criteria for ensuring the adapter's transferability are restricted to the target base model's weights and subspace. To facilitate the transfer of LoRA parameters of the source model to a target model, we employ the adapter only in the layers of the target model that exhibit an acceptable level of subspace similarity. Our extensive experiments demonstrate the effectiveness of LoRA-X for text-to-image generation, including Stable Diffusion v1.5 and Stable Diffusion XL.
Rapid Switching and Multi-Adapter Fusion via Sparse High Rank Adapters
Jul 22, 2024


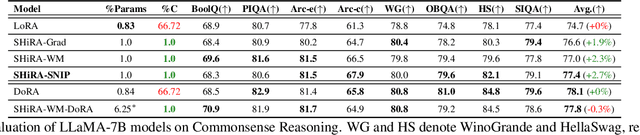
In this paper, we propose Sparse High Rank Adapters (SHiRA) that directly finetune 1-2% of the base model weights while leaving others unchanged, thus, resulting in a highly sparse adapter. This high sparsity incurs no inference overhead, enables rapid switching directly in the fused mode, and significantly reduces concept-loss during multi-adapter fusion. Our extensive experiments on LVMs and LLMs demonstrate that finetuning merely 1-2% parameters in the base model is sufficient for many adapter tasks and significantly outperforms Low Rank Adaptation (LoRA). We also show that SHiRA is orthogonal to advanced LoRA methods such as DoRA and can be easily combined with existing techniques.
Sparse High Rank Adapters
Jun 19, 2024
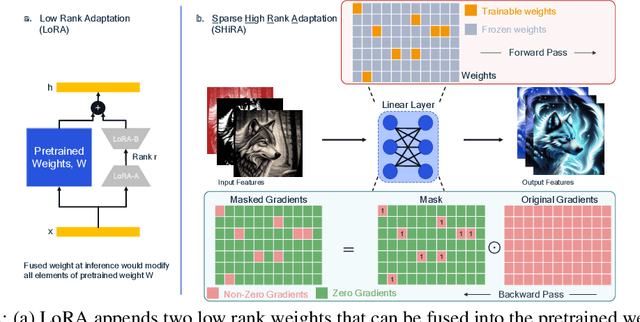
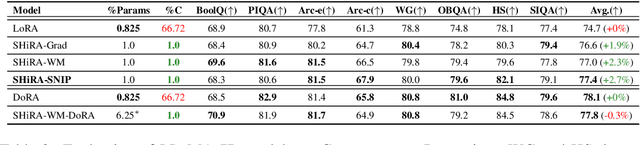
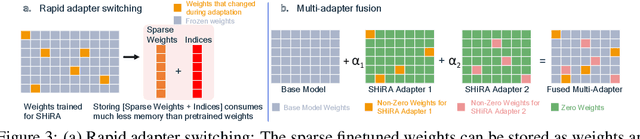
Low Rank Adaptation (LoRA) has gained massive attention in the recent generative AI research. One of the main advantages of LoRA is its ability to be fused with pretrained models adding no overhead during inference. However, from a mobile deployment standpoint, we can either avoid inference overhead in the fused mode but lose the ability to switch adapters rapidly, or suffer significant (up to 30% higher) inference latency while enabling rapid switching in the unfused mode. LoRA also exhibits concept-loss when multiple adapters are used concurrently. In this paper, we propose Sparse High Rank Adapters (SHiRA), a new paradigm which incurs no inference overhead, enables rapid switching, and significantly reduces concept-loss. Specifically, SHiRA can be trained by directly tuning only 1-2% of the base model weights while leaving others unchanged. This results in a highly sparse adapter which can be switched directly in the fused mode. We further provide theoretical and empirical insights on how high sparsity in SHiRA can aid multi-adapter fusion by reducing concept loss. Our extensive experiments on LVMs and LLMs demonstrate that finetuning only a small fraction of the parameters in the base model is sufficient for many tasks while enabling both rapid switching and multi-adapter fusion. Finally, we provide a latency- and memory-efficient SHiRA implementation based on Parameter-Efficient Finetuning (PEFT) Library. This implementation trains at nearly the same speed as LoRA while consuming lower peak GPU memory, thus making SHiRA easy to adopt for practical use cases.
FouRA: Fourier Low Rank Adaptation
Jun 13, 2024



While Low-Rank Adaptation (LoRA) has proven beneficial for efficiently fine-tuning large models, LoRA fine-tuned text-to-image diffusion models lack diversity in the generated images, as the model tends to copy data from the observed training samples. This effect becomes more pronounced at higher values of adapter strength and for adapters with higher ranks which are fine-tuned on smaller datasets. To address these challenges, we present FouRA, a novel low-rank method that learns projections in the Fourier domain along with learning a flexible input-dependent adapter rank selection strategy. Through extensive experiments and analysis, we show that FouRA successfully solves the problems related to data copying and distribution collapse while significantly improving the generated image quality. We demonstrate that FouRA enhances the generalization of fine-tuned models thanks to its adaptive rank selection. We further show that the learned projections in the frequency domain are decorrelated and prove effective when merging multiple adapters. While FouRA is motivated for vision tasks, we also demonstrate its merits for language tasks on the GLUE benchmark.
PosSAM: Panoptic Open-vocabulary Segment Anything
Mar 14, 2024
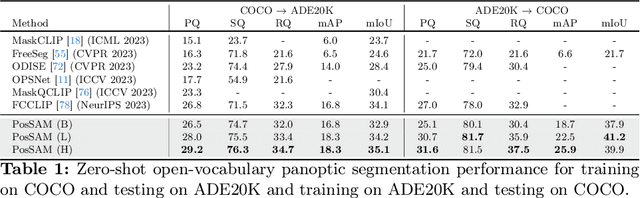

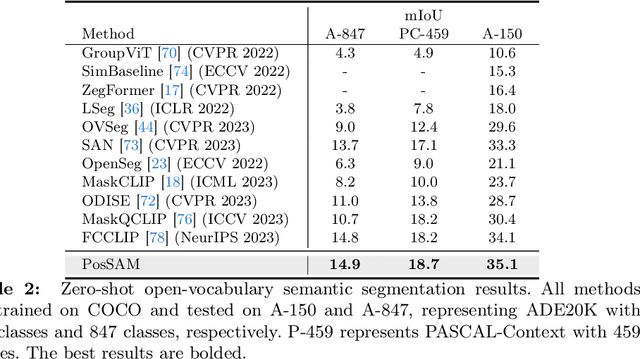
In this paper, we introduce an open-vocabulary panoptic segmentation model that effectively unifies the strengths of the Segment Anything Model (SAM) with the vision-language CLIP model in an end-to-end framework. While SAM excels in generating spatially-aware masks, it's decoder falls short in recognizing object class information and tends to oversegment without additional guidance. Existing approaches address this limitation by using multi-stage techniques and employing separate models to generate class-aware prompts, such as bounding boxes or segmentation masks. Our proposed method, PosSAM is an end-to-end model which leverages SAM's spatially rich features to produce instance-aware masks and harnesses CLIP's semantically discriminative features for effective instance classification. Specifically, we address the limitations of SAM and propose a novel Local Discriminative Pooling (LDP) module leveraging class-agnostic SAM and class-aware CLIP features for unbiased open-vocabulary classification. Furthermore, we introduce a Mask-Aware Selective Ensembling (MASE) algorithm that adaptively enhances the quality of generated masks and boosts the performance of open-vocabulary classification during inference for each image. We conducted extensive experiments to demonstrate our methods strong generalization properties across multiple datasets, achieving state-of-the-art performance with substantial improvements over SOTA open-vocabulary panoptic segmentation methods. In both COCO to ADE20K and ADE20K to COCO settings, PosSAM outperforms the previous state-of-the-art methods by a large margin, 2.4 PQ and 4.6 PQ, respectively. Project Website: https://vibashan.github.io/possam-web/.
Multi-camera Bird's Eye View Perception for Autonomous Driving
Sep 19, 2023Most automated driving systems comprise a diverse sensor set, including several cameras, Radars, and LiDARs, ensuring a complete 360\deg coverage in near and far regions. Unlike Radar and LiDAR, which measure directly in 3D, cameras capture a 2D perspective projection with inherent depth ambiguity. However, it is essential to produce perception outputs in 3D to enable the spatial reasoning of other agents and structures for optimal path planning. The 3D space is typically simplified to the BEV space by omitting the less relevant Z-coordinate, which corresponds to the height dimension.The most basic approach to achieving the desired BEV representation from a camera image is IPM, assuming a flat ground surface. Surround vision systems that are pretty common in new vehicles use the IPM principle to generate a BEV image and to show it on display to the driver. However, this approach is not suited for autonomous driving since there are severe distortions introduced by this too-simplistic transformation method. More recent approaches use deep neural networks to output directly in BEV space. These methods transform camera images into BEV space using geometric constraints implicitly or explicitly in the network. As CNN has more context information and a learnable transformation can be more flexible and adapt to image content, the deep learning-based methods set the new benchmark for BEV transformation and achieve state-of-the-art performance. First, this chapter discusses the contemporary trends of multi-camera-based DNN (deep neural network) models outputting object representations directly in the BEV space. Then, we discuss how this approach can extend to effective sensor fusion and coupling downstream tasks like situation analysis and prediction. Finally, we show challenges and open problems in BEV perception.
X-Align++: cross-modal cross-view alignment for Bird's-eye-view segmentation
Jun 06, 2023Bird's-eye-view (BEV) grid is a typical representation of the perception of road components, e.g., drivable area, in autonomous driving. Most existing approaches rely on cameras only to perform segmentation in BEV space, which is fundamentally constrained by the absence of reliable depth information. The latest works leverage both camera and LiDAR modalities but suboptimally fuse their features using simple, concatenation-based mechanisms. In this paper, we address these problems by enhancing the alignment of the unimodal features in order to aid feature fusion, as well as enhancing the alignment between the cameras' perspective view (PV) and BEV representations. We propose X-Align, a novel end-to-end cross-modal and cross-view learning framework for BEV segmentation consisting of the following components: (i) a novel Cross-Modal Feature Alignment (X-FA) loss, (ii) an attention-based Cross-Modal Feature Fusion (X-FF) module to align multi-modal BEV features implicitly, and (iii) an auxiliary PV segmentation branch with Cross-View Segmentation Alignment (X-SA) losses to improve the PV-to-BEV transformation. We evaluate our proposed method across two commonly used benchmark datasets, i.e., nuScenes and KITTI-360. Notably, X-Align significantly outperforms the state-of-the-art by 3 absolute mIoU points on nuScenes. We also provide extensive ablation studies to demonstrate the effectiveness of the individual components.