 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeodragon: Mobile Video Generation using Diffusion Transformer
Nov 08, 2025We introduce Neodragon, a text-to-video system capable of generating 2s (49 frames @24 fps) videos at the 640x1024 resolution directly on a Qualcomm Hexagon NPU in a record 6.7s (7 FPS). Differing from existing transformer-based offline text-to-video generation models, Neodragon is the first to have been specifically optimised for mobile hardware to achieve efficient and high-fidelity video synthesis. We achieve this through four key technical contributions: (1) Replacing the original large 4.762B T5xxl Text-Encoder with a much smaller 0.2B DT5 (DistilT5) with minimal quality loss, enabled through a novel Text-Encoder Distillation procedure. (2) Proposing an Asymmetric Decoder Distillation approach allowing us to replace the native codec-latent-VAE decoder with a more efficient one, without disturbing the generative latent-space of the generation pipeline. (3) Pruning of MMDiT blocks within the denoiser backbone based on their relative importance, with recovery of original performance through a two-stage distillation process. (4) Reducing the NFE (Neural Functional Evaluation) requirement of the denoiser by performing step distillation using DMD adapted for pyramidal flow-matching, thereby substantially accelerating video generation. When paired with an optimised SSD1B first-frame image generator and QuickSRNet for 2x super-resolution, our end-to-end Neodragon system becomes a highly parameter (4.945B full model), memory (3.5GB peak RAM usage), and runtime (6.7s E2E latency) efficient mobile-friendly model, while achieving a VBench total score of 81.61. By enabling low-cost, private, and on-device text-to-video synthesis, Neodragon democratizes AI-based video content creation, empowering creators to generate high-quality videos without reliance on cloud services. Code and model will be made publicly available at our website: https://qualcomm-ai-research.github.io/neodragon
Rapid Switching and Multi-Adapter Fusion via Sparse High Rank Adapters
Jul 22, 2024


In this paper, we propose Sparse High Rank Adapters (SHiRA) that directly finetune 1-2% of the base model weights while leaving others unchanged, thus, resulting in a highly sparse adapter. This high sparsity incurs no inference overhead, enables rapid switching directly in the fused mode, and significantly reduces concept-loss during multi-adapter fusion. Our extensive experiments on LVMs and LLMs demonstrate that finetuning merely 1-2% parameters in the base model is sufficient for many adapter tasks and significantly outperforms Low Rank Adaptation (LoRA). We also show that SHiRA is orthogonal to advanced LoRA methods such as DoRA and can be easily combined with existing techniques.
Sparse High Rank Adapters
Jun 19, 2024
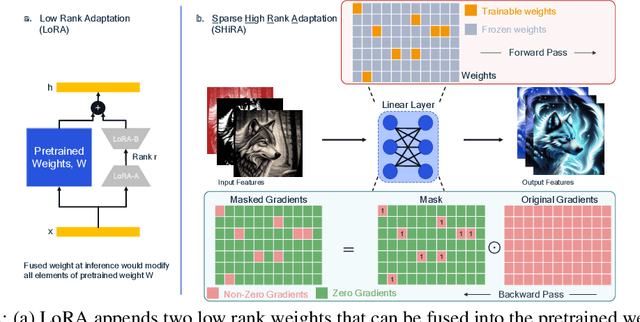
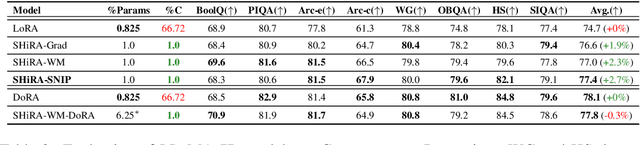
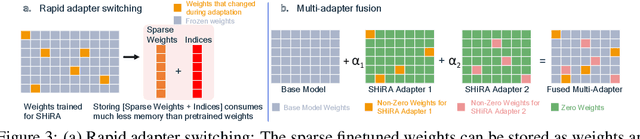
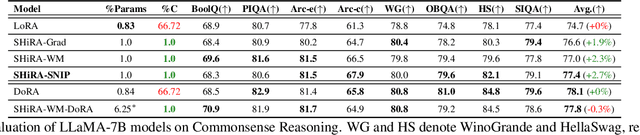
Low Rank Adaptation (LoRA) has gained massive attention in the recent generative AI research. One of the main advantages of LoRA is its ability to be fused with pretrained models adding no overhead during inference. However, from a mobile deployment standpoint, we can either avoid inference overhead in the fused mode but lose the ability to switch adapters rapidly, or suffer significant (up to 30% higher) inference latency while enabling rapid switching in the unfused mode. LoRA also exhibits concept-loss when multiple adapters are used concurrently. In this paper, we propose Sparse High Rank Adapters (SHiRA), a new paradigm which incurs no inference overhead, enables rapid switching, and significantly reduces concept-loss. Specifically, SHiRA can be trained by directly tuning only 1-2% of the base model weights while leaving others unchanged. This results in a highly sparse adapter which can be switched directly in the fused mode. We further provide theoretical and empirical insights on how high sparsity in SHiRA can aid multi-adapter fusion by reducing concept loss. Our extensive experiments on LVMs and LLMs demonstrate that finetuning only a small fraction of the parameters in the base model is sufficient for many tasks while enabling both rapid switching and multi-adapter fusion. Finally, we provide a latency- and memory-efficient SHiRA implementation based on Parameter-Efficient Finetuning (PEFT) Library. This implementation trains at nearly the same speed as LoRA while consuming lower peak GPU memory, thus making SHiRA easy to adopt for practical use cases.
FouRA: Fourier Low Rank Adaptation
Jun 13, 2024



While Low-Rank Adaptation (LoRA) has proven beneficial for efficiently fine-tuning large models, LoRA fine-tuned text-to-image diffusion models lack diversity in the generated images, as the model tends to copy data from the observed training samples. This effect becomes more pronounced at higher values of adapter strength and for adapters with higher ranks which are fine-tuned on smaller datasets. To address these challenges, we present FouRA, a novel low-rank method that learns projections in the Fourier domain along with learning a flexible input-dependent adapter rank selection strategy. Through extensive experiments and analysis, we show that FouRA successfully solves the problems related to data copying and distribution collapse while significantly improving the generated image quality. We demonstrate that FouRA enhances the generalization of fine-tuned models thanks to its adaptive rank selection. We further show that the learned projections in the frequency domain are decorrelated and prove effective when merging multiple adapters. While FouRA is motivated for vision tasks, we also demonstrate its merits for language tasks on the GLUE benchmark.