 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRapid Switching and Multi-Adapter Fusion via Sparse High Rank Adapters
Jul 22, 2024


In this paper, we propose Sparse High Rank Adapters (SHiRA) that directly finetune 1-2% of the base model weights while leaving others unchanged, thus, resulting in a highly sparse adapter. This high sparsity incurs no inference overhead, enables rapid switching directly in the fused mode, and significantly reduces concept-loss during multi-adapter fusion. Our extensive experiments on LVMs and LLMs demonstrate that finetuning merely 1-2% parameters in the base model is sufficient for many adapter tasks and significantly outperforms Low Rank Adaptation (LoRA). We also show that SHiRA is orthogonal to advanced LoRA methods such as DoRA and can be easily combined with existing techniques.
Sparse High Rank Adapters
Jun 19, 2024
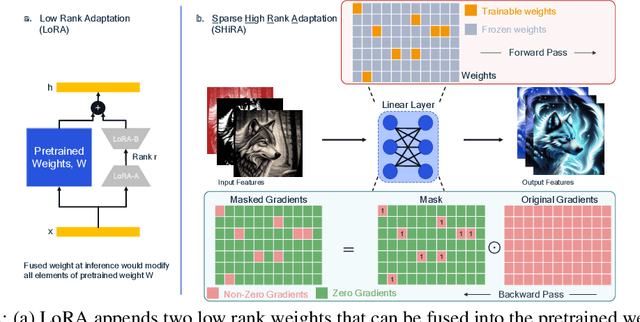
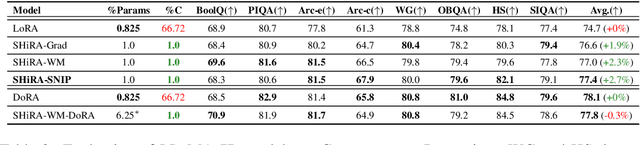
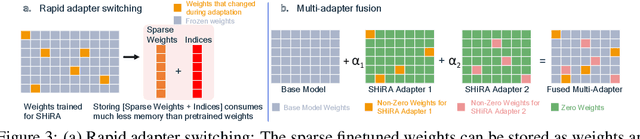
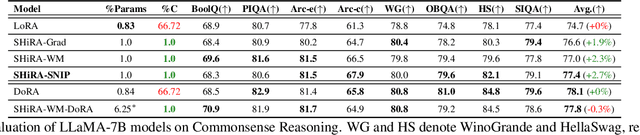
Low Rank Adaptation (LoRA) has gained massive attention in the recent generative AI research. One of the main advantages of LoRA is its ability to be fused with pretrained models adding no overhead during inference. However, from a mobile deployment standpoint, we can either avoid inference overhead in the fused mode but lose the ability to switch adapters rapidly, or suffer significant (up to 30% higher) inference latency while enabling rapid switching in the unfused mode. LoRA also exhibits concept-loss when multiple adapters are used concurrently. In this paper, we propose Sparse High Rank Adapters (SHiRA), a new paradigm which incurs no inference overhead, enables rapid switching, and significantly reduces concept-loss. Specifically, SHiRA can be trained by directly tuning only 1-2% of the base model weights while leaving others unchanged. This results in a highly sparse adapter which can be switched directly in the fused mode. We further provide theoretical and empirical insights on how high sparsity in SHiRA can aid multi-adapter fusion by reducing concept loss. Our extensive experiments on LVMs and LLMs demonstrate that finetuning only a small fraction of the parameters in the base model is sufficient for many tasks while enabling both rapid switching and multi-adapter fusion. Finally, we provide a latency- and memory-efficient SHiRA implementation based on Parameter-Efficient Finetuning (PEFT) Library. This implementation trains at nearly the same speed as LoRA while consuming lower peak GPU memory, thus making SHiRA easy to adopt for practical use cases.
FP8 Quantization: The Power of the Exponent
Aug 19, 2022
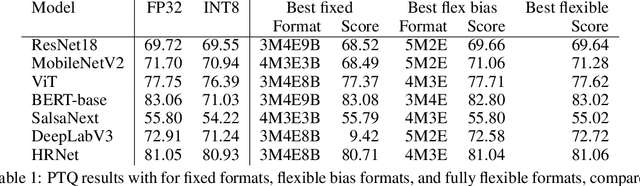
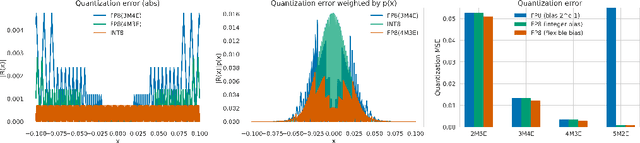
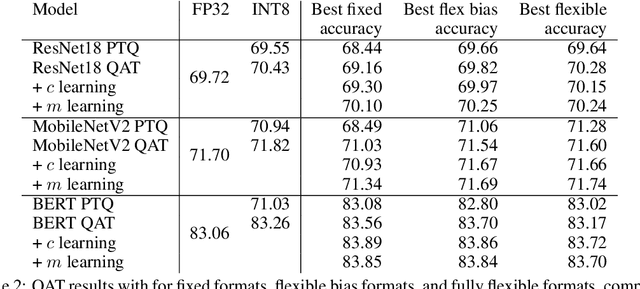
When quantizing neural networks for efficient inference, low-bit integers are the go-to format for efficiency. However, low-bit floating point numbers have an extra degree of freedom, assigning some bits to work on an exponential scale instead. This paper in-depth investigates this benefit of the floating point format for neural network inference. We detail the choices that can be made for the FP8 format, including the important choice of the number of bits for the mantissa and exponent, and show analytically in which settings these choices give better performance. Then we show how these findings translate to real networks, provide an efficient implementation for FP8 simulation, and a new algorithm that enables the learning of both the scale parameters and the number of exponent bits in the FP8 format. Our chief conclusion is that when doing post-training quantization for a wide range of networks, the FP8 format is better than INT8 in terms of accuracy, and the choice of the number of exponent bits is driven by the severity of outliers in the network. We also conduct experiments with quantization-aware training where the difference in formats disappears as the network is trained to reduce the effect of outliers.