 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo-Undo: Generating and Reversing Physical Actions in Vision-Language Models
Dec 15, 2025We introduce the Do-Undo task and benchmark to address a critical gap in vision-language models: understanding and generating physically plausible scene transformations driven by real-world actions. Unlike prior work focused on object-level edits, Do-Undo requires models to simulate the outcome of a physical action and then accurately reverse it, reflecting true cause-and-effect in the visual world. We curate a large-scale dataset of reversible actions from real-world videos and design a training strategy enforcing consistency for robust action grounding. Our experiments reveal that current models struggle with physical reversibility, underscoring the importance of this task for embodied AI, robotics, and physics-aware generative modeling. Do-Undo establishes an intuitive testbed for evaluating and advancing physical reasoning in multimodal systems.
MultiHuman-Testbench: Benchmarking Image Generation for Multiple Humans
Jun 25, 2025Generation of images containing multiple humans, performing complex actions, while preserving their facial identities, is a significant challenge. A major factor contributing to this is the lack of a a dedicated benchmark. To address this, we introduce MultiHuman-Testbench, a novel benchmark for rigorously evaluating generative models for multi-human generation. The benchmark comprises 1800 samples, including carefully curated text prompts, describing a range of simple to complex human actions. These prompts are matched with a total of 5,550 unique human face images, sampled uniformly to ensure diversity across age, ethnic background, and gender. Alongside captions, we provide human-selected pose conditioning images which accurately match the prompt. We propose a multi-faceted evaluation suite employing four key metrics to quantify face count, ID similarity, prompt alignment, and action detection. We conduct a thorough evaluation of a diverse set of models, including zero-shot approaches and training-based methods, with and without regional priors. We also propose novel techniques to incorporate image and region isolation using human segmentation and Hungarian matching, significantly improving ID similarity. Our proposed benchmark and key findings provide valuable insights and a standardized tool for advancing research in multi-human image generation.
SubZero: Composing Subject, Style, and Action via Zero-Shot Personalization
Feb 27, 2025Diffusion models are increasingly popular for generative tasks, including personalized composition of subjects and styles. While diffusion models can generate user-specified subjects performing text-guided actions in custom styles, they require fine-tuning and are not feasible for personalization on mobile devices. Hence, tuning-free personalization methods such as IP-Adapters have progressively gained traction. However, for the composition of subjects and styles, these works are less flexible due to their reliance on ControlNet, or show content and style leakage artifacts. To tackle these, we present SubZero, a novel framework to generate any subject in any style, performing any action without the need for fine-tuning. We propose a novel set of constraints to enhance subject and style similarity, while reducing leakage. Additionally, we propose an orthogonalized temporal aggregation scheme in the cross-attention blocks of denoising model, effectively conditioning on a text prompt along with single subject and style images. We also propose a novel method to train customized content and style projectors to reduce content and style leakage. Through extensive experiments, we show that our proposed approach, while suitable for running on-edge, shows significant improvements over state-of-the-art works performing subject, style and action composition.
Rapid Switching and Multi-Adapter Fusion via Sparse High Rank Adapters
Jul 22, 2024


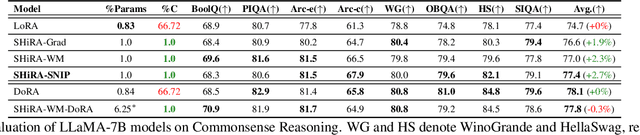
In this paper, we propose Sparse High Rank Adapters (SHiRA) that directly finetune 1-2% of the base model weights while leaving others unchanged, thus, resulting in a highly sparse adapter. This high sparsity incurs no inference overhead, enables rapid switching directly in the fused mode, and significantly reduces concept-loss during multi-adapter fusion. Our extensive experiments on LVMs and LLMs demonstrate that finetuning merely 1-2% parameters in the base model is sufficient for many adapter tasks and significantly outperforms Low Rank Adaptation (LoRA). We also show that SHiRA is orthogonal to advanced LoRA methods such as DoRA and can be easily combined with existing techniques.
Sparse High Rank Adapters
Jun 19, 2024
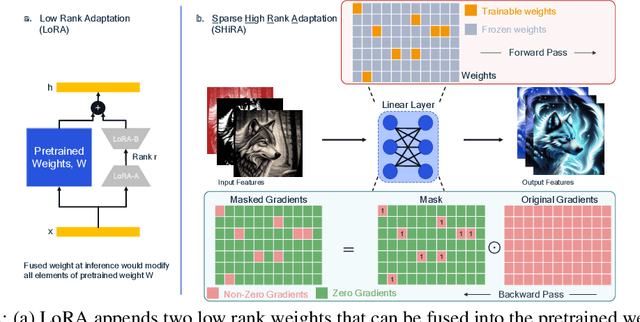
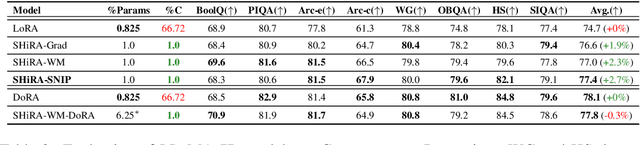
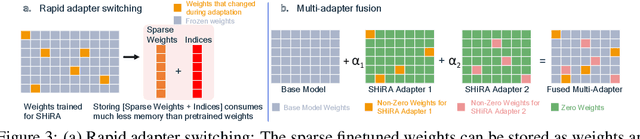
Low Rank Adaptation (LoRA) has gained massive attention in the recent generative AI research. One of the main advantages of LoRA is its ability to be fused with pretrained models adding no overhead during inference. However, from a mobile deployment standpoint, we can either avoid inference overhead in the fused mode but lose the ability to switch adapters rapidly, or suffer significant (up to 30% higher) inference latency while enabling rapid switching in the unfused mode. LoRA also exhibits concept-loss when multiple adapters are used concurrently. In this paper, we propose Sparse High Rank Adapters (SHiRA), a new paradigm which incurs no inference overhead, enables rapid switching, and significantly reduces concept-loss. Specifically, SHiRA can be trained by directly tuning only 1-2% of the base model weights while leaving others unchanged. This results in a highly sparse adapter which can be switched directly in the fused mode. We further provide theoretical and empirical insights on how high sparsity in SHiRA can aid multi-adapter fusion by reducing concept loss. Our extensive experiments on LVMs and LLMs demonstrate that finetuning only a small fraction of the parameters in the base model is sufficient for many tasks while enabling both rapid switching and multi-adapter fusion. Finally, we provide a latency- and memory-efficient SHiRA implementation based on Parameter-Efficient Finetuning (PEFT) Library. This implementation trains at nearly the same speed as LoRA while consuming lower peak GPU memory, thus making SHiRA easy to adopt for practical use cases.
FouRA: Fourier Low Rank Adaptation
Jun 13, 2024



While Low-Rank Adaptation (LoRA) has proven beneficial for efficiently fine-tuning large models, LoRA fine-tuned text-to-image diffusion models lack diversity in the generated images, as the model tends to copy data from the observed training samples. This effect becomes more pronounced at higher values of adapter strength and for adapters with higher ranks which are fine-tuned on smaller datasets. To address these challenges, we present FouRA, a novel low-rank method that learns projections in the Fourier domain along with learning a flexible input-dependent adapter rank selection strategy. Through extensive experiments and analysis, we show that FouRA successfully solves the problems related to data copying and distribution collapse while significantly improving the generated image quality. We demonstrate that FouRA enhances the generalization of fine-tuned models thanks to its adaptive rank selection. We further show that the learned projections in the frequency domain are decorrelated and prove effective when merging multiple adapters. While FouRA is motivated for vision tasks, we also demonstrate its merits for language tasks on the GLUE benchmark.
Neural 5G Indoor Localization with IMU Supervision
Feb 15, 2024



Radio signals are well suited for user localization because they are ubiquitous, can operate in the dark and maintain privacy. Many prior works learn mappings between channel state information (CSI) and position fully-supervised. However, that approach relies on position labels which are very expensive to acquire. In this work, this requirement is relaxed by using pseudo-labels during deployment, which are calculated from an inertial measurement unit (IMU). We propose practical algorithms for IMU double integration and training of the localization system. We show decimeter-level accuracy on simulated and challenging real data of 5G measurements. Our IMU-supervised method performs similarly to fully-supervised, but requires much less effort to deploy.
Neural RF SLAM for unsupervised positioning and mapping with channel state information
Mar 15, 2022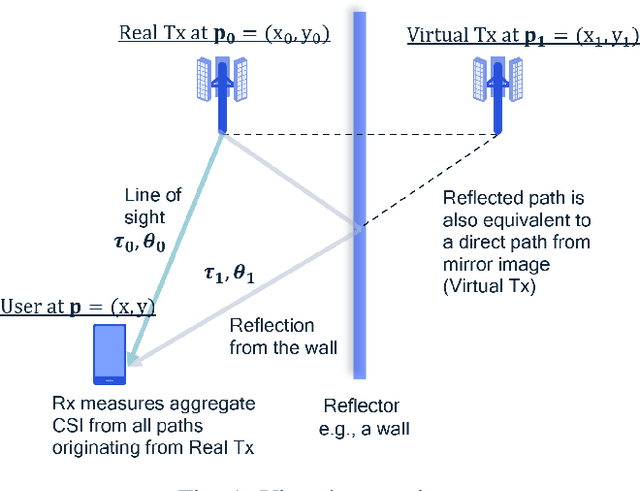
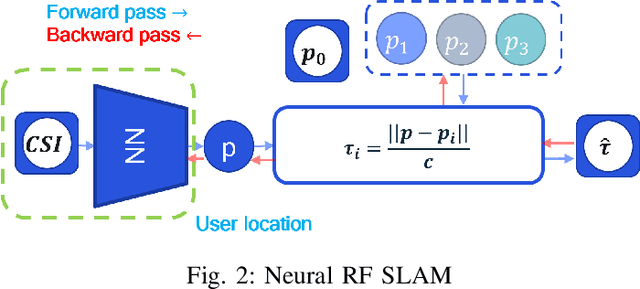

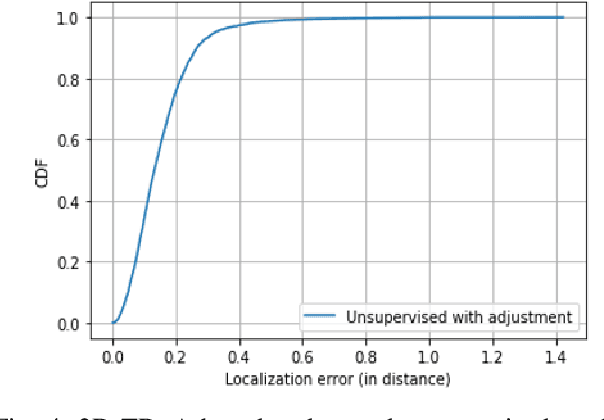
We present a neural network architecture for jointly learning user locations and environment mapping up to isometry, in an unsupervised way, from channel state information (CSI) values with no location information. The model is based on an encoder-decoder architecture. The encoder network maps CSI values to the user location. The decoder network models the physics of propagation by parametrizing the environment using virtual anchors. It aims at reconstructing, from the encoder output and virtual anchor location, the set of time of flights (ToFs) that are extracted from CSI using super-resolution methods. The neural network task is set prediction and is accordingly trained end-to-end. The proposed model learns an interpretable latent, i.e., user location, by just enforcing a physics-based decoder. It is shown that the proposed model achieves sub-meter accuracy on synthetic ray tracing based datasets with single anchor SISO setup while recovering the environment map up to 4cm median error in a 2D environment and 15cm in a 3D environment