 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Cloud Agents Meet Device Agents: Lessons from Hybrid Multi-Agent Systems
May 28, 2026The design space of agentic AI inference spans two extremes: frontier large language models (LLMs), typically hosted in the cloud and offering strong performance across a wide range of tasks at substantially high cost, and more cost-efficient small language models (SLMs), which are amenable to on-device inference. Hybrid multi-agent systems (MASs) combining on-device and cloud models offer a promising middle ground, but they also introduce a complex and poorly understood design space in which task accuracy, monetary cost, and edge energy consumption are tightly coupled; in the absence of general design principles, hybrid components, although not the most prevalent choice, are typically introduced through ad hoc decisions tailored to specific domains. In this work, we examine this design space more systematically. We adapt two representative MAS architectures to support hybrid inference and study how individual design choices shift the operating point along the Pareto frontier of power, cost, and performance. Our findings paint a nuanced picture of hybrid MAS design: while SLMs can effectively benefit from LLM assistance, the optimal architecture is highly task-dependent, and greater frontier-level compute does not consistently translate to better performance.
LaneRoPE: Positional Encoding for Collaborative Parallel Reasoning and Generation
May 26, 2026Parallel LLM test-time scaling techniques (e.g., best-of-$N$) require drawing $N>1$ sequences conditioned on the same input prompt. These methods boost accuracy while exploiting the computational efficiency of batching $N$ generations. However, each sequence in the batch is traditionally generated independently and hence does not reuse intermediate generations, computations, or observations from other sequences. In this paper, we propose LaneRoPE to enable coordination and collaboration among $N>1$ sequences at generation time. LaneRoPE involves two key ideas: (a) an inter-sequence attention mask to make sampling of sequences dependent on one another; and (b) a RoPE extension that injects positional information that captures relative positions between tokens, both within and outside a particular sequence. We evaluate our approach on mathematical reasoning tasks and find promising results: LaneRoPE enables collaboration among sequences, yielding additional accuracy gains under limited generated sequence length. Importantly, since LaneRoPE enables coordination with minimal changes to the underlying LLM architecture and introduces a negligible overhead at inference time, it is appealing to rapidly incorporate parallel reasoning into existing LLM inference pipelines.
Efficient Reasoning on the Edge
Mar 17, 2026Large language models (LLMs) with chain-of-thought reasoning achieve state-of-the-art performance across complex problem-solving tasks, but their verbose reasoning traces and large context requirements make them impractical for edge deployment. These challenges include high token generation costs, large KV-cache footprints, and inefficiencies when distilling reasoning capabilities into smaller models for mobile devices. Existing approaches often rely on distilling reasoning traces from larger models into smaller models, which are verbose and stylistically redundant, undesirable for on-device inference. In this work, we propose a lightweight approach to enable reasoning in small LLMs using LoRA adapters combined with supervised fine-tuning. We further introduce budget forcing via reinforcement learning on these adapters, significantly reducing response length with minimal accuracy loss. To address memory-bound decoding, we exploit parallel test-time scaling, improving accuracy at minor latency increase. Finally, we present a dynamic adapter-switching mechanism that activates reasoning only when needed and a KV-cache sharing strategy during prompt encoding, reducing time-to-first-token for on-device inference. Experiments on Qwen2.5-7B demonstrate that our method achieves efficient, accurate reasoning under strict resource constraints, making LLM reasoning practical for mobile scenarios. Videos demonstrating our solution running on mobile devices are available on our project page.
Reasoning as Compression: Unifying Budget Forcing via the Conditional Information Bottleneck
Mar 09, 2026Chain-of-Thought (CoT) prompting improves LLM accuracy on complex tasks but often increases token usage and inference cost. Existing "Budget Forcing" methods reducing cost via fine-tuning with heuristic length penalties, suppress both essential reasoning and redundant filler. We recast efficient reasoning as a lossy compression problem under the Information Bottleneck (IB) principle, and identify a key theoretical gap when applying naive IB to transformers: attention violates the Markov property between prompt, reasoning trace, and response. To resolve this issue, we model CoT generation under the Conditional Information Bottleneck (CIB) principle, where the reasoning trace Z acts as a computational bridge that contains only the information about the response Y that is not directly accessible from the prompt X. This yields a general Reinforcement Learning objective: maximize task reward while compressing completions under a prior over reasoning traces, subsuming common heuristics (e.g., length penalties) as special cases (e.g., uniform priors). In contrast to naive token-counting-based approaches, we introduce a semantic prior that measures token cost by surprisal under a language model prior. Empirically, our CIB objective prunes cognitive bloat while preserving fluency and logic, improving accuracy at moderate compression and enabling aggressive compression with minimal accuracy drop.
LUMINA: Long-horizon Understanding for Multi-turn Interactive Agents
Jan 23, 2026Large language models can perform well on many isolated tasks, yet they continue to struggle on multi-turn, long-horizon agentic problems that require skills such as planning, state tracking, and long context processing. In this work, we aim to better understand the relative importance of advancing these underlying capabilities for success on such tasks. We develop an oracle counterfactual framework for multi-turn problems that asks: how would an agent perform if it could leverage an oracle to perfectly perform a specific task? The change in the agent's performance due to this oracle assistance allows us to measure the criticality of such oracle skill in the future advancement of AI agents. We introduce a suite of procedurally generated, game-like tasks with tunable complexity. These controlled environments allow us to provide precise oracle interventions, such as perfect planning or flawless state tracking, and make it possible to isolate the contribution of each oracle without confounding effects present in real-world benchmarks. Our results show that while some interventions (e.g., planning) consistently improve performance across settings, the usefulness of other skills is dependent on the properties of the environment and language model. Our work sheds light on the challenges of multi-turn agentic environments to guide the future efforts in the development of AI agents and language models.
Fundamental bounds on efficiency-confidence trade-off for transductive conformal prediction
Sep 04, 2025Transductive conformal prediction addresses the simultaneous prediction for multiple data points. Given a desired confidence level, the objective is to construct a prediction set that includes the true outcomes with the prescribed confidence. We demonstrate a fundamental trade-off between confidence and efficiency in transductive methods, where efficiency is measured by the size of the prediction sets. Specifically, we derive a strict finite-sample bound showing that any non-trivial confidence level leads to exponential growth in prediction set size for data with inherent uncertainty. The exponent scales linearly with the number of samples and is proportional to the conditional entropy of the data. Additionally, the bound includes a second-order term, dispersion, defined as the variance of the log conditional probability distribution. We show that this bound is achievable in an idealized setting. Finally, we examine a special case of transductive prediction where all test data points share the same label. We show that this scenario reduces to the hypothesis testing problem with empirically observed statistics and provide an asymptotically optimal confidence predictor, along with an analysis of the error exponent.
ReQuestNet: A Foundational Learning model for Channel Estimation
Aug 12, 2025In this paper, we present a novel neural architecture for channel estimation (CE) in 5G and beyond, the Recurrent Equivariant UERS Estimation Network (ReQuestNet). It incorporates several practical considerations in wireless communication systems, such as ability to handle variable number of resource block (RB), dynamic number of transmit layers, physical resource block groups (PRGs) bundling size (BS), demodulation reference signal (DMRS) patterns with a single unified model, thereby, drastically simplifying the CE pipeline. Besides it addresses several limitations of the legacy linear MMSE solutions, for example, by being independent of other reference signals and particularly by jointly processing MIMO layers and differently precoded channels with unknown precoding at the receiver. ReQuestNet comprises of two sub-units, CoarseNet followed by RefinementNet. CoarseNet performs per PRG, per transmit-receive (Tx-Rx) stream channel estimation, while RefinementNet refines the CoarseNet channel estimate by incorporating correlations across differently precoded PRGs, and correlation across multiple input multiple output (MIMO) channel spatial dimensions (cross-MIMO). Simulation results demonstrate that ReQuestNet significantly outperforms genie minimum mean squared error (MMSE) CE across a wide range of channel conditions, delay-Doppler profiles, achieving up to 10dB gain at high SNRs. Notably, ReQuestNet generalizes effectively to unseen channel profiles, efficiently exploiting inter-PRG and cross-MIMO correlations under dynamic PRG BS and varying transmit layer allocations.
Local Look-Ahead Guidance via Verifier-in-the-Loop for Automated Theorem Proving
Mar 12, 2025



The most promising recent methods for AI reasoning require applying variants of reinforcement learning (RL) either on rolled out trajectories from the model, even for the step-wise rewards, or large quantities of human annotated trajectory data. The reliance on the rolled-out trajectory renders the compute cost and time prohibitively high. In particular, the correctness of a reasoning trajectory can typically only be judged at its completion, leading to sparse rewards in RL or requiring expensive synthetic data generation in expert iteration-like methods. In this work, we focus on the Automatic Theorem Proving (ATP) task and propose a novel verifier-in-the-loop design, which unlike existing approaches that leverage feedback on the entire reasoning trajectory, employs an automated verifier to give intermediate feedback at each step of the reasoning process. Using Lean as the verifier, we empirically show that the step-by-step local verification produces a global improvement in the model's reasoning accuracy and efficiency.
On the Sample Complexity of One Hidden Layer Networks with Equivariance, Locality and Weight Sharing
Nov 21, 2024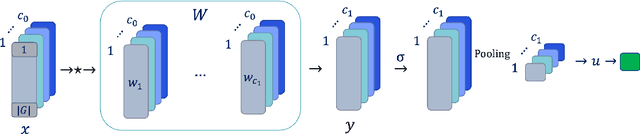

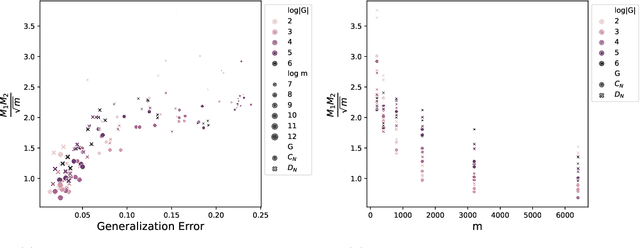
Weight sharing, equivariance, and local filters, as in convolutional neural networks, are believed to contribute to the sample efficiency of neural networks. However, it is not clear how each one of these design choices contribute to the generalization error. Through the lens of statistical learning theory, we aim to provide an insight into this question by characterizing the relative impact of each choice on the sample complexity. We obtain lower and upper sample complexity bounds for a class of single hidden layer networks. It is shown that the gain of equivariance is directly manifested in the bound, while getting a similar increase for weight sharing depends on the sharing mechanism. Among our results, we obtain a completely dimension-free bound for equivariant networks for a class of pooling operations. We show that the bound depends merely on the norm of filters, which is tighter than using the spectral norm of the respective matrix. We also characterize the trade-off in sample complexity between the parametrization of filters in spatial and frequency domains, particularly when spatial filters are localized as in vanilla convolutional neural networks.
Multi-Draft Speculative Sampling: Canonical Architectures and Theoretical Limits
Oct 23, 2024We consider multi-draft speculative sampling, where the proposal sequences are sampled independently from different draft models. At each step, a token-level draft selection scheme takes a list of valid tokens as input and produces an output token whose distribution matches that of the target model. Previous works have demonstrated that the optimal scheme (which maximizes the probability of accepting one of the input tokens) can be cast as a solution to a linear program. In this work we show that the optimal scheme can be decomposed into a two-step solution: in the first step an importance sampling (IS) type scheme is used to select one intermediate token; in the second step (single-draft) speculative sampling is applied to generate the output token. For the case of two identical draft models we further 1) establish a necessary and sufficient condition on the distributions of the target and draft models for the acceptance probability to equal one and 2) provide an explicit expression for the optimal acceptance probability. Our theoretical analysis also motives a new class of token-level selection scheme based on weighted importance sampling. Our experimental results demonstrate consistent improvements in the achievable block efficiency and token rates over baseline schemes in a number of scenarios.