 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Bi-Linear State Transitions in Recurrent Neural Networks
May 27, 2025The role of hidden units in recurrent neural networks is typically seen as modeling memory, with research focusing on enhancing information retention through gating mechanisms. A less explored perspective views hidden units as active participants in the computation performed by the network, rather than passive memory stores. In this work, we revisit bi-linear operations, which involve multiplicative interactions between hidden units and input embeddings. We demonstrate theoretically and empirically that they constitute a natural inductive bias for representing the evolution of hidden states in state tracking tasks. These are the simplest type of task that require hidden units to actively contribute to the behavior of the network. We also show that bi-linear state updates form a natural hierarchy corresponding to state tracking tasks of increasing complexity, with popular linear recurrent networks such as Mamba residing at the lowest-complexity center of that hierarchy.
Can Vision-Language Models Answer Face to Face Questions in the Real-World?
Mar 25, 2025AI models have made significant strides in recent years in their ability to describe and answer questions about real-world images. They have also made progress in the ability to converse with users in real-time using audio input. This raises the question: have we reached the point where AI models, connected to a camera and microphone, can converse with users in real-time about scenes and events that are unfolding live in front of the camera? This has been a long-standing goal in AI and is a prerequisite for real-world AI assistants and humanoid robots to interact with humans in everyday situations. In this work, we introduce a new dataset and benchmark, the Qualcomm Interactive Video Dataset (IVD), which allows us to assess the extent to which existing models can support these abilities, and to what degree these capabilities can be instilled through fine-tuning. The dataset is based on a simple question-answering setup, where users ask questions that the system has to answer, in real-time, based on the camera and audio input. We show that existing models fall far behind human performance on this task, and we identify the main sources for the performance gap. However, we also show that for many of the required perceptual skills, fine-tuning on this form of data can significantly reduce this gap.
ClevrSkills: Compositional Language and Visual Reasoning in Robotics
Nov 13, 2024



Robotics tasks are highly compositional by nature. For example, to perform a high-level task like cleaning the table a robot must employ low-level capabilities of moving the effectors to the objects on the table, pick them up and then move them off the table one-by-one, while re-evaluating the consequently dynamic scenario in the process. Given that large vision language models (VLMs) have shown progress on many tasks that require high level, human-like reasoning, we ask the question: if the models are taught the requisite low-level capabilities, can they compose them in novel ways to achieve interesting high-level tasks like cleaning the table without having to be explicitly taught so? To this end, we present ClevrSkills - a benchmark suite for compositional reasoning in robotics. ClevrSkills is an environment suite developed on top of the ManiSkill2 simulator and an accompanying dataset. The dataset contains trajectories generated on a range of robotics tasks with language and visual annotations as well as multi-modal prompts as task specification. The suite includes a curriculum of tasks with three levels of compositional understanding, starting with simple tasks requiring basic motor skills. We benchmark multiple different VLM baselines on ClevrSkills and show that even after being pre-trained on large numbers of tasks, these models fail on compositional reasoning in robotics tasks.
Multi-Draft Speculative Sampling: Canonical Architectures and Theoretical Limits
Oct 23, 2024We consider multi-draft speculative sampling, where the proposal sequences are sampled independently from different draft models. At each step, a token-level draft selection scheme takes a list of valid tokens as input and produces an output token whose distribution matches that of the target model. Previous works have demonstrated that the optimal scheme (which maximizes the probability of accepting one of the input tokens) can be cast as a solution to a linear program. In this work we show that the optimal scheme can be decomposed into a two-step solution: in the first step an importance sampling (IS) type scheme is used to select one intermediate token; in the second step (single-draft) speculative sampling is applied to generate the output token. For the case of two identical draft models we further 1) establish a necessary and sufficient condition on the distributions of the target and draft models for the acceptance probability to equal one and 2) provide an explicit expression for the optimal acceptance probability. Our theoretical analysis also motives a new class of token-level selection scheme based on weighted importance sampling. Our experimental results demonstrate consistent improvements in the achievable block efficiency and token rates over baseline schemes in a number of scenarios.
AirLetters: An Open Video Dataset of Characters Drawn in the Air
Oct 03, 2024
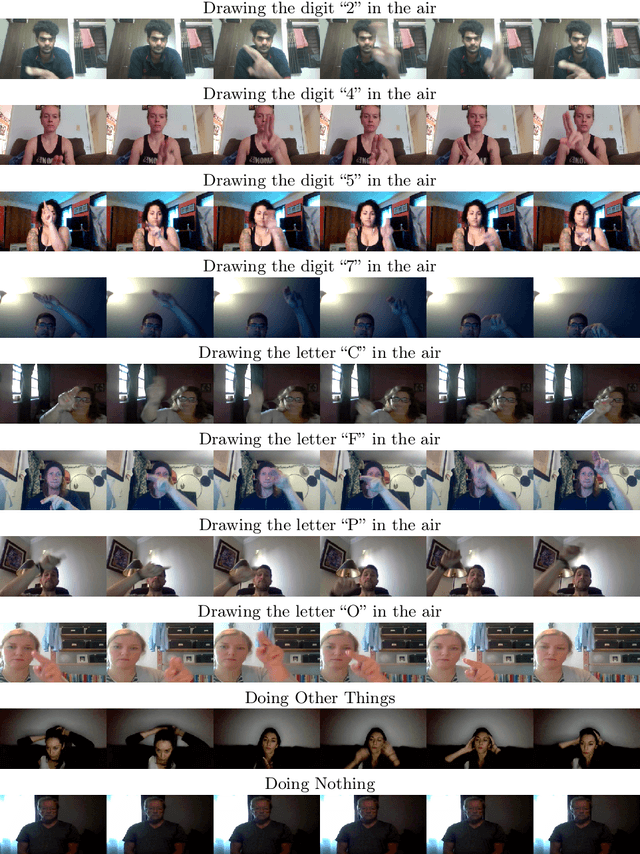


We introduce AirLetters, a new video dataset consisting of real-world videos of human-generated, articulated motions. Specifically, our dataset requires a vision model to predict letters that humans draw in the air. Unlike existing video datasets, accurate classification predictions for AirLetters rely critically on discerning motion patterns and on integrating long-range information in the video over time. An extensive evaluation of state-of-the-art image and video understanding models on AirLetters shows that these methods perform poorly and fall far behind a human baseline. Our work shows that, despite recent progress in end-to-end video understanding, accurate representations of complex articulated motions -- a task that is trivial for humans -- remains an open problem for end-to-end learning.
Your Context Is Not an Array: Unveiling Random Access Limitations in Transformers
Aug 10, 2024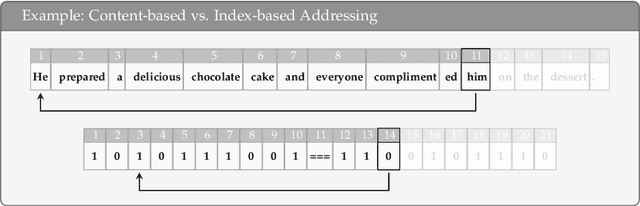



Despite their recent successes, Transformer-based large language models show surprising failure modes. A well-known example of such failure modes is their inability to length-generalize: solving problem instances at inference time that are longer than those seen during training. In this work, we further explore the root cause of this failure by performing a detailed analysis of model behaviors on the simple parity task. Our analysis suggests that length generalization failures are intricately related to a model's inability to perform random memory accesses within its context window. We present supporting evidence for this hypothesis by demonstrating the effectiveness of methodologies that circumvent the need for indexing or that enable random token access indirectly, through content-based addressing. We further show where and how the failure to perform random memory access manifests through attention map visualizations.
Live Fitness Coaching as a Testbed for Situated Interaction
Jul 11, 2024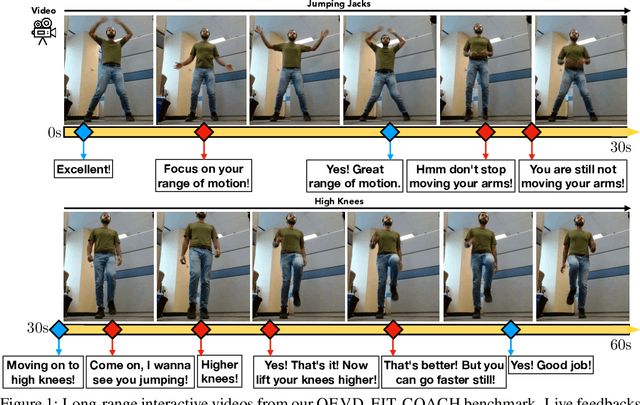



Tasks at the intersection of vision and language have had a profound impact in advancing the capabilities of vision-language models such as dialog-based assistants. However, models trained on existing tasks are largely limited to turn-based interactions, where each turn must be stepped (i.e., prompted) by the user. Open-ended, asynchronous interactions where an AI model may proactively deliver timely responses or feedback based on the unfolding situation in real-time are an open challenge. In this work, we present the QEVD benchmark and dataset which explores human-AI interaction in the challenging, yet controlled, real-world domain of fitness coaching - a task which intrinsically requires monitoring live user activity and providing timely feedback. It is the first benchmark that requires assistive vision-language models to recognize complex human actions, identify mistakes grounded in those actions, and provide appropriate feedback. Our experiments reveal the limitations of existing state of the art vision-language models for such asynchronous situated interactions. Motivated by this, we propose a simple end-to-end streaming baseline that can respond asynchronously to human actions with appropriate feedbacks at the appropriate time.
Unleashing the Creative Mind: Language Model As Hierarchical Policy For Improved Exploration on Challenging Problem Solving
Nov 01, 2023



Large Language Models (LLMs) have achieved tremendous progress, yet they still often struggle with challenging reasoning problems. Current approaches address this challenge by sampling or searching detailed and low-level reasoning chains. However, these methods are still limited in their exploration capabilities, making it challenging for correct solutions to stand out in the huge solution space. In this work, we unleash LLMs' creative potential for exploring multiple diverse problem solving strategies by framing an LLM as a hierarchical policy via in-context learning. This policy comprises of a visionary leader that proposes multiple diverse high-level problem-solving tactics as hints, accompanied by a follower that executes detailed problem-solving processes following each of the high-level instruction. The follower uses each of the leader's directives as a guide and samples multiple reasoning chains to tackle the problem, generating a solution group for each leader proposal. Additionally, we propose an effective and efficient tournament-based approach to select among these explored solution groups to reach the final answer. Our approach produces meaningful and inspiring hints, enhances problem-solving strategy exploration, and improves the final answer accuracy on challenging problems in the MATH dataset. Code will be released at https://github.com/lz1oceani/LLM-As-Hierarchical-Policy.
Painter: Teaching Auto-regressive Language Models to Draw Sketches
Aug 16, 2023
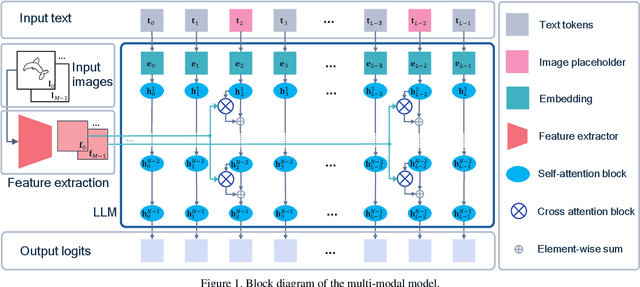

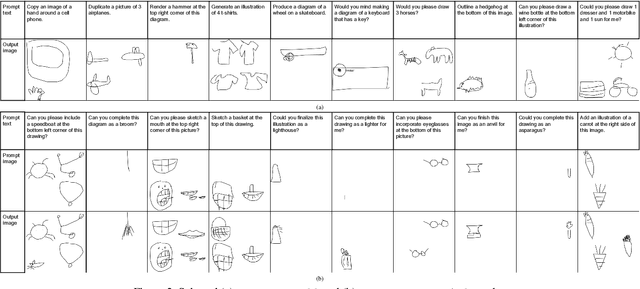
Large language models (LLMs) have made tremendous progress in natural language understanding and they have also been successfully adopted in other domains such as computer vision, robotics, reinforcement learning, etc. In this work, we apply LLMs to image generation tasks by directly generating the virtual brush strokes to paint an image. We present Painter, an LLM that can convert user prompts in text description format to sketches by generating the corresponding brush strokes in an auto-regressive way. We construct Painter based on off-the-shelf LLM that is pre-trained on a large text corpus, by fine-tuning it on the new task while preserving language understanding capabilities. We create a dataset of diverse multi-object sketches paired with textual prompts that covers several object types and tasks. Painter can generate sketches from text descriptions, remove objects from canvas, and detect and classify objects in sketches. Although this is an unprecedented pioneering work in using LLMs for auto-regressive image generation, the results are very encouraging.
Look, Remember and Reason: Visual Reasoning with Grounded Rationales
Jun 30, 2023



Large language models have recently shown human level performance on a variety of reasoning tasks. However, the ability of these models to perform complex visual reasoning has not been studied in detail yet. A key challenge in many visual reasoning tasks is that the visual information needs to be tightly integrated in the reasoning process. We propose to address this challenge by drawing inspiration from human visual problem solving which depends on a variety of low-level visual capabilities. It can often be cast as the three step-process of ``Look, Remember, Reason'': visual information is incrementally extracted using low-level visual routines in a step-by-step fashion until a final answer is reached. We follow the same paradigm to enable existing large language models, with minimal changes to the architecture, to solve visual reasoning problems. To this end, we introduce rationales over the visual input that allow us to integrate low-level visual capabilities, such as object recognition and tracking, as surrogate tasks. We show competitive performance on diverse visual reasoning tasks from the CLEVR, CATER, and ACRE datasets over state-of-the-art models designed specifically for these tasks.