 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Training-Free Multi-Token Prediction via Embedding-Space Probing
Mar 18, 2026Large language models (LLMs) exhibit latent multi-token prediction (MTP) capabilities despite being trained solely for next-token generation. We propose a simple, training-free MTP approach that probes an LLM using on-the-fly mask tokens drawn from its embedding space, enabling parallel prediction of future tokens without modifying model weights or relying on auxiliary draft models. Our method constructs a speculative token tree by sampling top-K candidates from mask-token logits and applies a lightweight pruning strategy to retain high-probability continuations. During decoding, candidate predictions are verified in parallel, resulting in lossless generation while substantially reducing the number of model calls and improving token throughput. Across benchmarks, our probing-based MTP consistently outperforms existing training-free baselines, increasing acceptance length by approximately 12\% on LLaMA3 and 8--12\% on Qwen3, and achieving throughput gains of up to 15--19\%. Finally, we provide theoretical insights and empirical evidence showing that decoder layers naturally align mask-token representations with next-token states, enabling accurate multi-step prediction without retraining or auxiliary models.
ConFu: Contemplate the Future for Better Speculative Sampling
Mar 09, 2026Speculative decoding has emerged as a powerful approach to accelerate large language model (LLM) inference by employing lightweight draft models to propose candidate tokens that are subsequently verified by the target model. The effectiveness of this paradigm critically depends on the quality of the draft model. While recent advances such as the EAGLE series achieve state-of-the-art speedup, existing draft models remain limited by error accumulation: they condition only on the current prefix, causing their predictions to drift from the target model over steps. In this work, we propose \textbf{ConFu} (Contemplate the Future), a novel speculative decoding framework that enables draft models to anticipate the future direction of generation. ConFu introduces (i) contemplate tokens and soft prompts that allow the draft model to leverage future-oriented signals from the target model at negligible cost, (ii) a dynamic contemplate token mechanism with MoE to enable context-aware future prediction, and (iii) a training framework with anchor token sampling and future prediction replication that learns robust future prediction. Experiments demonstrate that ConFu improves token acceptance rates and generation speed over EAGLE-3 by 8--11% across various downstream tasks with Llama-3 3B and 8B models. We believe our work is the first to bridge speculative decoding with continuous reasoning tokens, offering a new direction for accelerating LLM inference.
QUOKA: Query-Oriented KV Selection For Efficient LLM Prefill
Feb 09, 2026We present QUOKA: Query-oriented KV selection for efficient attention, a training-free and hardware agnostic sparse attention algorithm for accelerating transformer inference under chunked prefill. While many queries focus on a smaller group of keys in the attention operator, we observe that queries with low cosine similarity with respect to the mean query interact more strongly with more keys and have the greatest contribution to final attention logits. By prioritizing these low cosine similarity queries, the behavior of full attention during the prefill stage can be closely approximated. QUOKA leverages this observation, accelerating attention by (1) first retaining a small set of representative queries and (2) then subselectin the keys most aligned with those queries. Through experiments on Needle-In-A-Haystack, LongBench, RULER, and Math500, we show that, while realizing a 3x reduction in time-to-first-token, 5x speedup in attention on Nvidia GPUs and up to nearly a 7x speedup on Intel Xeon CPUs, QUOKA achieves near-baseline accuracy, utilizing 88% fewer key-value pairs per attention evaluation.
Double-P: Hierarchical Top-P Sparse Attention for Long-Context LLMs
Feb 05, 2026As long-context inference becomes central to large language models (LLMs), attention over growing key-value caches emerges as a dominant decoding bottleneck, motivating sparse attention for scalable inference. Fixed-budget top-k sparse attention cannot adapt to heterogeneous attention distributions across heads and layers, whereas top-p sparse attention directly preserves attention mass and provides stronger accuracy guarantees. Existing top-p methods, however, fail to jointly optimize top-p accuracy, selection overhead, and sparse attention cost, which limits their overall efficiency. We present Double-P, a hierarchical sparse attention framework that optimizes all three stages. Double-P first performs coarse-grained top-p estimation at the cluster level using size-weighted centroids, then adaptively refines computation through a second top-p stage that allocates token-level attention only when needed. Across long-context benchmarks, Double-P consistently achieves near-zero accuracy drop, reducing attention computation overhead by up to 1.8x and delivers up to 1.3x end-to-end decoding speedup over state-of-the-art fixed-budget sparse attention methods.
Fast Forward: Accelerating LLM Prefill with Predictive FFN Sparsity
Jan 30, 2026The prefill stage of large language model (LLM) inference is a key computational bottleneck for long-context workloads. At short-to-moderate context lengths (1K--16K tokens), Feed-Forward Networks (FFNs) dominate this cost, accounting for most of the total FLOPs. Existing FFN sparsification methods, designed for autoregressive decoding, fail to exploit the prefill stage's parallelism and often degrade accuracy. To address this, we introduce FastForward, a predictive sparsity framework that accelerates LLM prefill through block-wise, context-aware FFN sparsity. FastForward combines (1) a lightweight expert predictor to select high-importance neurons per block, (2) an error compensation network to correct sparsity-induced errors, and (3) a layer-wise sparsity scheduler to allocate compute based on token-mixing importance. Across LLaMA and Qwen models up to 8B parameters, FastForward delivers up to 1.45$\times$ compute-bound speedup at 50% FFN sparsity with $<$ 6% accuracy loss compared to the dense baseline on LongBench, substantially reducing Time-to-First-Token (TTFT) for efficient, long-context LLM inference on constrained hardware.
KeyDiff: Key Similarity-Based KV Cache Eviction for Long-Context LLM Inference in Resource-Constrained Environments
Apr 23, 2025In this work, we demonstrate that distinctive keys during LLM inference tend to have high attention scores. We explore this phenomenon and propose KeyDiff, a training-free KV cache eviction method based on key similarity. This method facilitates the deployment of LLM-based application requiring long input prompts in resource-constrained environments with limited memory and compute budgets. Unlike other KV cache eviction methods, KeyDiff can process arbitrarily long prompts within strict resource constraints and efficiently generate responses. We demonstrate that KeyDiff computes the optimal solution to a KV cache selection problem that maximizes key diversity, providing a theoretical understanding of KeyDiff. Notably,KeyDiff does not rely on attention scores, allowing the use of optimized attention mechanisms like FlashAttention. We demonstrate the effectiveness of KeyDiff across diverse tasks and models, illustrating a performance gap of less than 0.04\% with 8K cache budget ($\sim$ 23\% KV cache reduction) from the non-evicting baseline on the LongBench benchmark for Llama 3.1-8B and Llama 3.2-3B.
KeDiff: Key Similarity-Based KV Cache Eviction for Long-Context LLM Inference in Resource-Constrained Environments
Apr 21, 2025In this work, we demonstrate that distinctive keys during LLM inference tend to have high attention scores. We explore this phenomenon and propose KeyDiff, a training-free KV cache eviction method based on key similarity. This method facilitates the deployment of LLM-based application requiring long input prompts in resource-constrained environments with limited memory and compute budgets. Unlike other KV cache eviction methods, KeyDiff can process arbitrarily long prompts within strict resource constraints and efficiently generate responses. We demonstrate that KeyDiff computes the optimal solution to a KV cache selection problem that maximizes key diversity, providing a theoretical understanding of KeyDiff. Notably,KeyDiff does not rely on attention scores, allowing the use of optimized attention mechanisms like FlashAttention. We demonstrate the effectiveness of KeyDiff across diverse tasks and models, illustrating a performance gap of less than 0.04\% with 8K cache budget ($\sim$ 23\% KV cache reduction) from the non-evicting baseline on the LongBench benchmark for Llama 3.1-8B and Llama 3.2-3B.
CAOTE: KV Caching through Attention Output Error based Token Eviction
Apr 18, 2025While long context support of large language models has extended their abilities, it also incurs challenges in memory and compute which becomes crucial bottlenecks in resource-restricted devices. Token eviction, a widely adopted post-training methodology designed to alleviate the bottlenecks by evicting less important tokens from the cache, typically uses attention scores as proxy metrics for token importance. However, one major limitation of attention score as a token-wise importance metrics is that it lacks the information about contribution of tokens to the attention output. In this paper, we propose a simple eviction criterion based on the contribution of cached tokens to attention outputs. Our method, CAOTE, optimizes for eviction error due to token eviction, by seamlessly integrating attention scores and value vectors. This is the first method which uses value vector information on top of attention-based eviction scores. Additionally, CAOTE can act as a meta-heuristic method with flexible usage with any token eviction method. We show that CAOTE, when combined with the state-of-the-art attention score-based methods, always improves accuracies on the downstream task, indicating the importance of leveraging information from values during token eviction process.
AdaEDL: Early Draft Stopping for Speculative Decoding of Large Language Models via an Entropy-based Lower Bound on Token Acceptance Probability
Oct 24, 2024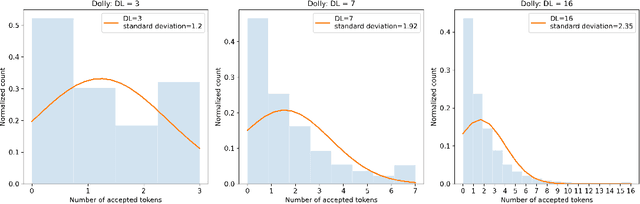
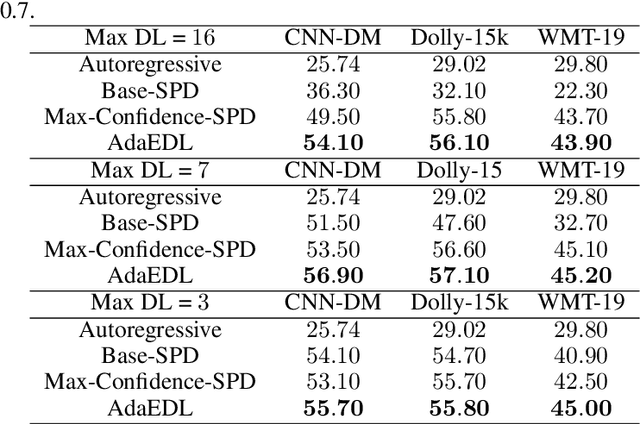
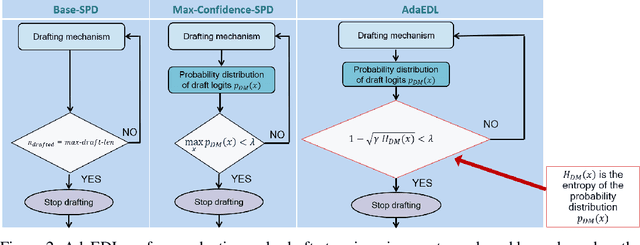
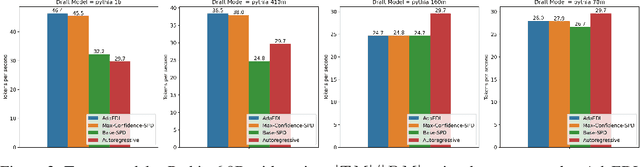
Speculative decoding is a powerful technique that attempts to circumvent the autoregressive constraint of modern Large Language Models (LLMs). The aim of speculative decoding techniques is to improve the average inference time of a large, target model without sacrificing its accuracy, by using a more efficient draft model to propose draft tokens which are then verified in parallel. The number of draft tokens produced in each drafting round is referred to as the draft length and is often a static hyperparameter chosen based on the acceptance rate statistics of the draft tokens. However, setting a static draft length can negatively impact performance, especially in scenarios where drafting is expensive and there is a high variance in the number of tokens accepted. Adaptive Entropy-based Draft Length (AdaEDL) is a simple, training and parameter-free criteria which allows for early stopping of the token drafting process by approximating a lower bound on the expected acceptance probability of the drafted token based on the currently observed entropy of the drafted logits. We show that AdaEDL consistently outperforms static draft-length speculative decoding by 10%-57% as well as other training-free draft-stopping techniques by upto 10% in a variety of settings and datasets. At the same time, we show that AdaEDL is more robust than these techniques and preserves performance in high-sampling-temperature scenarios. Since it is training-free, in contrast to techniques that rely on the training of dataset-specific draft-stopping predictors, AdaEDL can seamlessly be integrated into a variety of pre-existing LLM systems.
Live Fitness Coaching as a Testbed for Situated Interaction
Jul 11, 2024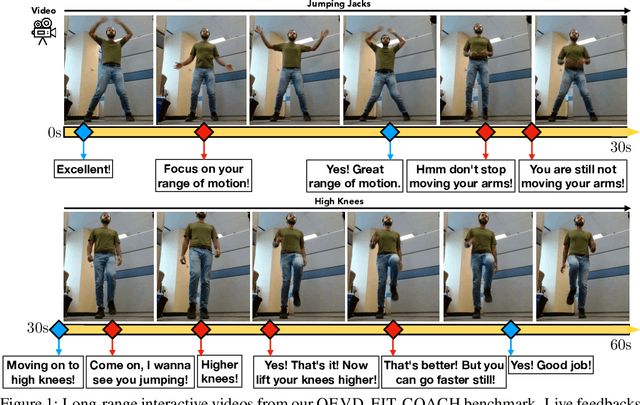



Tasks at the intersection of vision and language have had a profound impact in advancing the capabilities of vision-language models such as dialog-based assistants. However, models trained on existing tasks are largely limited to turn-based interactions, where each turn must be stepped (i.e., prompted) by the user. Open-ended, asynchronous interactions where an AI model may proactively deliver timely responses or feedback based on the unfolding situation in real-time are an open challenge. In this work, we present the QEVD benchmark and dataset which explores human-AI interaction in the challenging, yet controlled, real-world domain of fitness coaching - a task which intrinsically requires monitoring live user activity and providing timely feedback. It is the first benchmark that requires assistive vision-language models to recognize complex human actions, identify mistakes grounded in those actions, and provide appropriate feedback. Our experiments reveal the limitations of existing state of the art vision-language models for such asynchronous situated interactions. Motivated by this, we propose a simple end-to-end streaming baseline that can respond asynchronously to human actions with appropriate feedbacks at the appropriate time.