 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaEDL: Early Draft Stopping for Speculative Decoding of Large Language Models via an Entropy-based Lower Bound on Token Acceptance Probability
Oct 24, 2024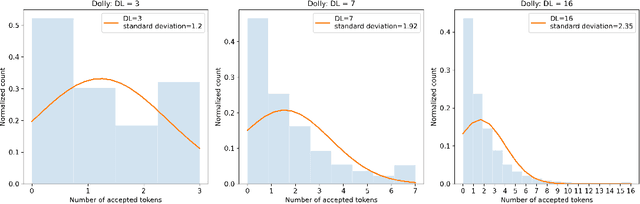
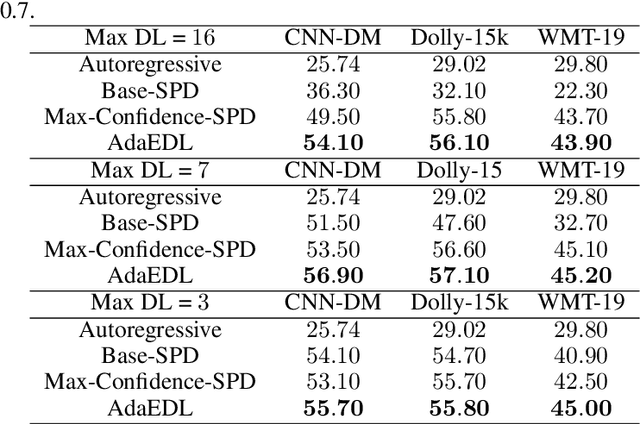
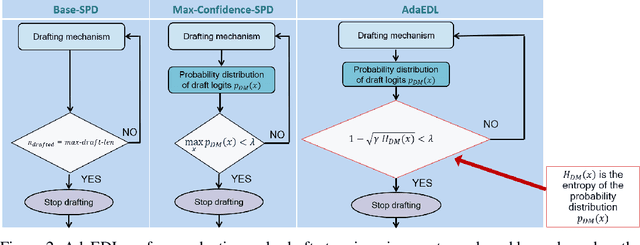
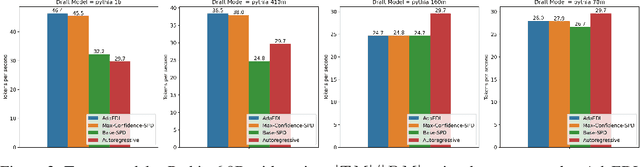
Speculative decoding is a powerful technique that attempts to circumvent the autoregressive constraint of modern Large Language Models (LLMs). The aim of speculative decoding techniques is to improve the average inference time of a large, target model without sacrificing its accuracy, by using a more efficient draft model to propose draft tokens which are then verified in parallel. The number of draft tokens produced in each drafting round is referred to as the draft length and is often a static hyperparameter chosen based on the acceptance rate statistics of the draft tokens. However, setting a static draft length can negatively impact performance, especially in scenarios where drafting is expensive and there is a high variance in the number of tokens accepted. Adaptive Entropy-based Draft Length (AdaEDL) is a simple, training and parameter-free criteria which allows for early stopping of the token drafting process by approximating a lower bound on the expected acceptance probability of the drafted token based on the currently observed entropy of the drafted logits. We show that AdaEDL consistently outperforms static draft-length speculative decoding by 10%-57% as well as other training-free draft-stopping techniques by upto 10% in a variety of settings and datasets. At the same time, we show that AdaEDL is more robust than these techniques and preserves performance in high-sampling-temperature scenarios. Since it is training-free, in contrast to techniques that rely on the training of dataset-specific draft-stopping predictors, AdaEDL can seamlessly be integrated into a variety of pre-existing LLM systems.
ExPT: Synthetic Pretraining for Few-Shot Experimental Design
Oct 30, 2023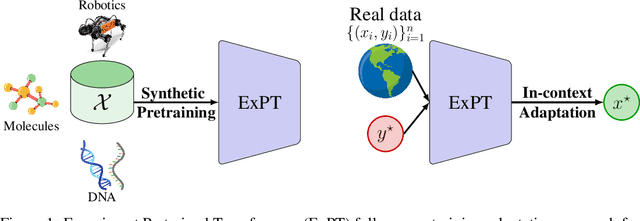
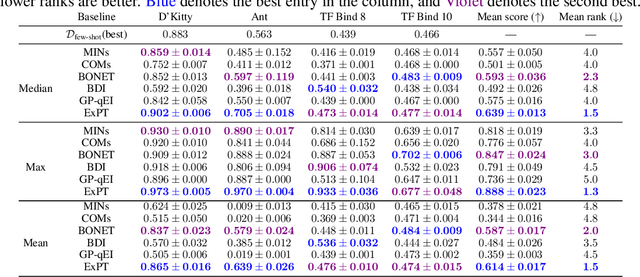
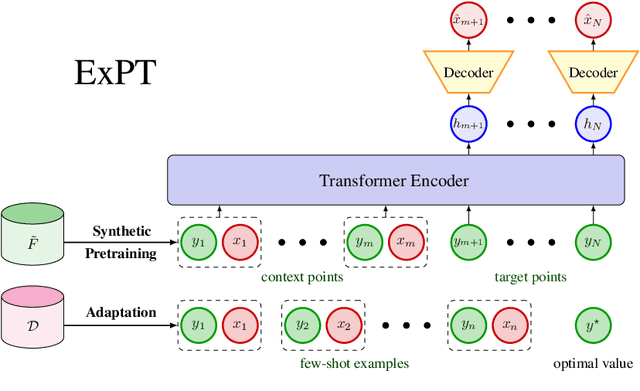
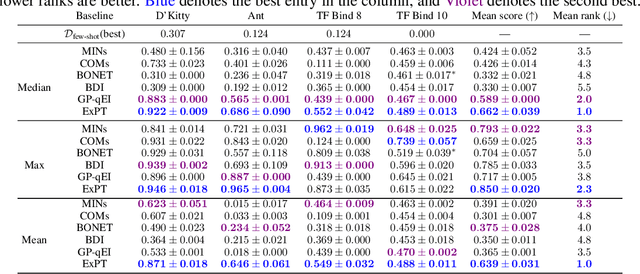
Experimental design is a fundamental problem in many science and engineering fields. In this problem, sample efficiency is crucial due to the time, money, and safety costs of real-world design evaluations. Existing approaches either rely on active data collection or access to large, labeled datasets of past experiments, making them impractical in many real-world scenarios. In this work, we address the more challenging yet realistic setting of few-shot experimental design, where only a few labeled data points of input designs and their corresponding values are available. We approach this problem as a conditional generation task, where a model conditions on a few labeled examples and the desired output to generate an optimal input design. To this end, we introduce Experiment Pretrained Transformers (ExPT), a foundation model for few-shot experimental design that employs a novel combination of synthetic pretraining with in-context learning. In ExPT, we only assume knowledge of a finite collection of unlabelled data points from the input domain and pretrain a transformer neural network to optimize diverse synthetic functions defined over this domain. Unsupervised pretraining allows ExPT to adapt to any design task at test time in an in-context fashion by conditioning on a few labeled data points from the target task and generating the candidate optima. We evaluate ExPT on few-shot experimental design in challenging domains and demonstrate its superior generality and performance compared to existing methods. The source code is available at https://github.com/tung-nd/ExPT.git.