 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreaming Interventions: Can Video Large Language Models Correct Mistakes as They Occur?
Jun 08, 2026Learning everyday skills, like cooking a dish, relies increasingly on instructional media such as online videos. This opens the door to the use of video (and multimodal) large language models (LLMs) as task guidance assistants. A crucial capability for the real-world success of a prospective task guidance assistant is it's ability to intervene proactively as soon as a mistake is apparent in order to guide the user. To evaluate this crucial capability, we introduce Ego-MC-Bench (Mistake Corrections), a benchmark for evaluating reactive, step-by-step task guidance in realistic cooking scenarios. Extensive experiments show that Ego-MC-Bench is highly challenging for state-of-the-art video LLMs. We argue that a key reason is the limited availability of training data for fine-tuning models on this task. Although there exists a wide range of cooking video datasets, existing datasets lack examples of mistakes along with appropriately timed interventions. To help address this data limitation, we also introduce Ego-CoMist, a counterfactual synthetic dataset created by transforming non -interactive cooking videos into supervised training examples showing proactive interventions. We show that fine-tuning on Ego-CoMist yields performance gains especially for smaller and more efficient video LLMs that are well suited for delivering assistance on edge devices.
MAPLE: Latent Multi-Agent Play for End-to-End Autonomous Driving
May 13, 2026Vision-language-action (VLA) models are effective as end-to-end motion planners, but can be brittle when evaluated in closed-loop settings due to being trained under traditional imitation learning framework. Existing closed-loop supervision approaches lack scalability and fail to completely model a reactive environment. We propose MAPLE, a novel framework for reactive, multi-agent rollout of a dynamic driving scenario in the latent space of the VLA model. The ego vehicle and nearby traffic agents are independently controlled over multi-step horizons, while being reactive to other agents in the scene, enabling closed-loop training. MAPLE consists of two training stages: (1) supervised fine-tuning on the latent rollouts based on ground-truth trajectories, followed by (2) reinforcement learning with global and agent -specific rewards that encourage safety, progress, and interaction realism. We further propose diversity rewards that encourage the model to generate planning behaviors that may not be present in logged driving data. Notably, our closed-loop training framework is scalable and does not require external simulators, which can be computationally expensive to run and have limited visual fidelity to the real-world. MAPLE achieves state-of-the-art driving performance on Bench2Drive and demonstrates scalable, closed-loop multi-agent play for robust E2E autonomous driving systems.
Generative Scenario Rollouts for End-to-End Autonomous Driving
Jan 16, 2026Vision-Language-Action (VLA) models are emerging as highly effective planning models for end-to-end autonomous driving systems. However, current works mostly rely on imitation learning from sparse trajectory annotations and under-utilize their potential as generative models. We propose Generative Scenario Rollouts (GeRo), a plug-and-play framework for VLA models that jointly performs planning and generation of language-grounded future traffic scenes through an autoregressive rollout strategy. First, a VLA model is trained to encode ego vehicle and agent dynamics into latent tokens under supervision from planning, motion, and language tasks, facilitating text-aligned generation. Next, GeRo performs language-conditioned autoregressive generation. Given multi-view images, a scenario description, and ego-action questions, it generates future latent tokens and textual responses to guide long-horizon rollouts. A rollout-consistency loss stabilizes predictions using ground truth or pseudo-labels, mitigating drift and preserving text-action alignment. This design enables GeRo to perform temporally consistent, language-grounded rollouts that support long-horizon reasoning and multi-agent planning. On Bench2Drive, GeRo improves driving score and success rate by +15.7 and +26.2, respectively. By integrating reinforcement learning with generative rollouts, GeRo achieves state-of-the-art closed-loop and open-loop performance, demonstrating strong zero-shot robustness. These results highlight the promise of generative, language-conditioned reasoning as a foundation for safer and more interpretable end-to-end autonomous driving.
RoCA: Robust Cross-Domain End-to-End Autonomous Driving
Jun 11, 2025End-to-end (E2E) autonomous driving has recently emerged as a new paradigm, offering significant potential. However, few studies have looked into the practical challenge of deployment across domains (e.g., cities). Although several works have incorporated Large Language Models (LLMs) to leverage their open-world knowledge, LLMs do not guarantee cross-domain driving performance and may incur prohibitive retraining costs during domain adaptation. In this paper, we propose RoCA, a novel framework for robust cross-domain E2E autonomous driving. RoCA formulates the joint probabilistic distribution over the tokens that encode ego and surrounding vehicle information in the E2E pipeline. Instantiating with a Gaussian process (GP), RoCA learns a set of basis tokens with corresponding trajectories, which span diverse driving scenarios. Then, given any driving scene, it is able to probabilistically infer the future trajectory. By using RoCA together with a base E2E model in source-domain training, we improve the generalizability of the base model, without requiring extra inference computation. In addition, RoCA enables robust adaptation on new target domains, significantly outperforming direct finetuning. We extensively evaluate RoCA on various cross-domain scenarios and show that it achieves strong domain generalization and adaptation performance.
DySS: Dynamic Queries and State-Space Learning for Efficient 3D Object Detection from Multi-Camera Videos
Jun 11, 2025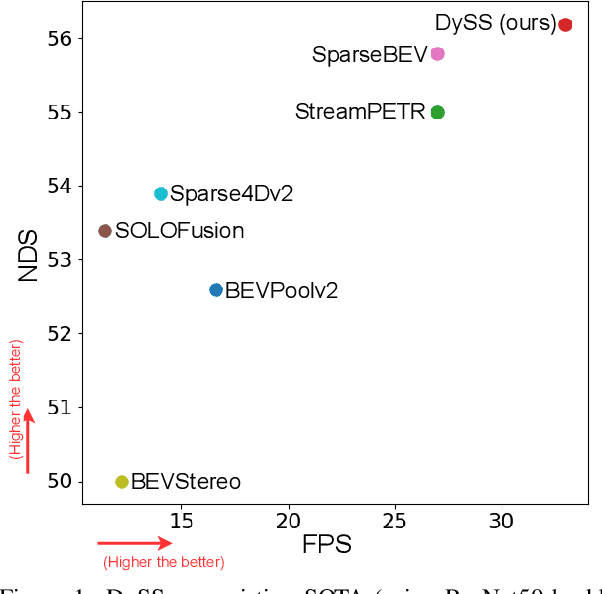
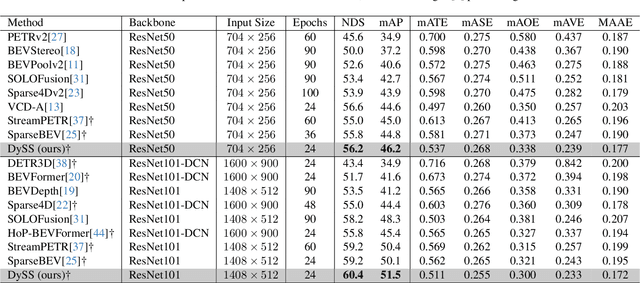
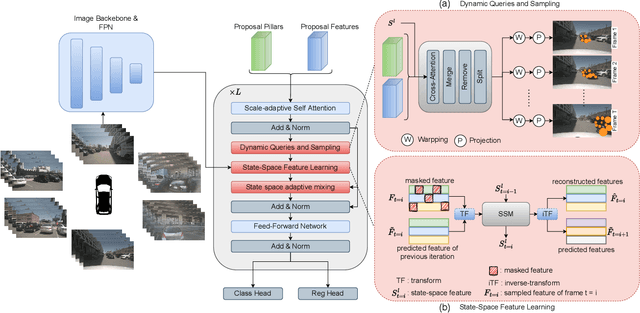
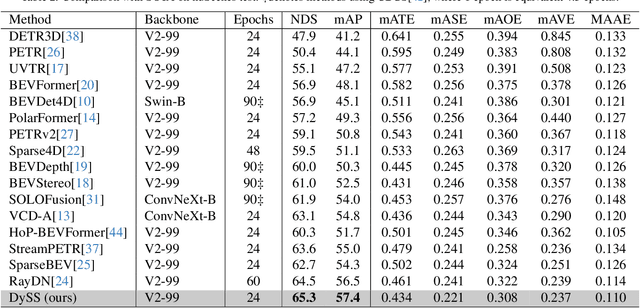
Camera-based 3D object detection in Bird's Eye View (BEV) is one of the most important perception tasks in autonomous driving. Earlier methods rely on dense BEV features, which are costly to construct. More recent works explore sparse query-based detection. However, they still require a large number of queries and can become expensive to run when more video frames are used. In this paper, we propose DySS, a novel method that employs state-space learning and dynamic queries. More specifically, DySS leverages a state-space model (SSM) to sequentially process the sampled features over time steps. In order to encourage the model to better capture the underlying motion and correspondence information, we introduce auxiliary tasks of future prediction and masked reconstruction to better train the SSM. The state of the SSM then provides an informative yet efficient summarization of the scene. Based on the state-space learned features, we dynamically update the queries via merge, remove, and split operations, which help maintain a useful, lean set of detection queries throughout the network. Our proposed DySS achieves both superior detection performance and efficient inference. Specifically, on the nuScenes test split, DySS achieves 65.31 NDS and 57.4 mAP, outperforming the latest state of the art. On the val split, DySS achieves 56.2 NDS and 46.2 mAP, as well as a real-time inference speed of 33 FPS.
Distilling Multi-modal Large Language Models for Autonomous Driving
Jan 16, 2025
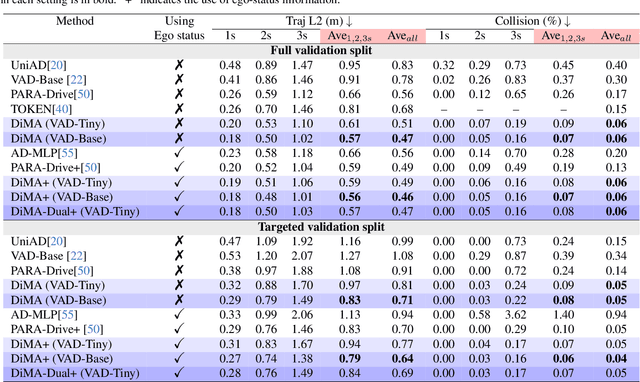

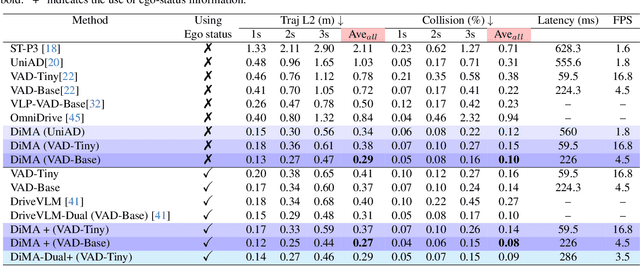
Autonomous driving demands safe motion planning, especially in critical "long-tail" scenarios. Recent end-to-end autonomous driving systems leverage large language models (LLMs) as planners to improve generalizability to rare events. However, using LLMs at test time introduces high computational costs. To address this, we propose DiMA, an end-to-end autonomous driving system that maintains the efficiency of an LLM-free (or vision-based) planner while leveraging the world knowledge of an LLM. DiMA distills the information from a multi-modal LLM to a vision-based end-to-end planner through a set of specially designed surrogate tasks. Under a joint training strategy, a scene encoder common to both networks produces structured representations that are semantically grounded as well as aligned to the final planning objective. Notably, the LLM is optional at inference, enabling robust planning without compromising on efficiency. Training with DiMA results in a 37% reduction in the L2 trajectory error and an 80% reduction in the collision rate of the vision-based planner, as well as a 44% trajectory error reduction in longtail scenarios. DiMA also achieves state-of-the-art performance on the nuScenes planning benchmark.
ToSA: Token Selective Attention for Efficient Vision Transformers
Jun 13, 2024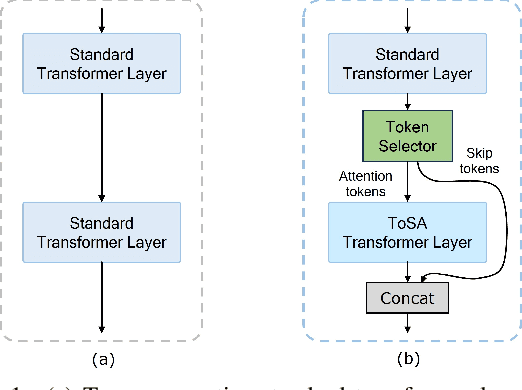
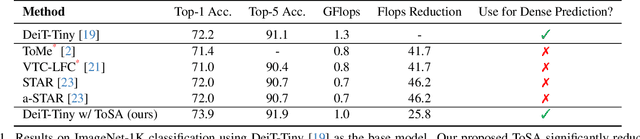
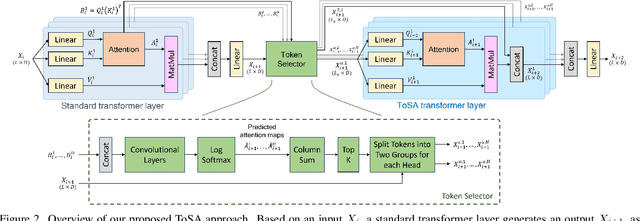

In this paper, we propose a novel token selective attention approach, ToSA, which can identify tokens that need to be attended as well as those that can skip a transformer layer. More specifically, a token selector parses the current attention maps and predicts the attention maps for the next layer, which are then used to select the important tokens that should participate in the attention operation. The remaining tokens simply bypass the next layer and are concatenated with the attended ones to re-form a complete set of tokens. In this way, we reduce the quadratic computation and memory costs as fewer tokens participate in self-attention while maintaining the features for all the image patches throughout the network, which allows it to be used for dense prediction tasks. Our experiments show that by applying ToSA, we can significantly reduce computation costs while maintaining accuracy on the ImageNet classification benchmark. Furthermore, we evaluate on the dense prediction task of monocular depth estimation on NYU Depth V2, and show that we can achieve similar depth prediction accuracy using a considerably lighter backbone with ToSA.
FutureDepth: Learning to Predict the Future Improves Video Depth Estimation
Mar 19, 2024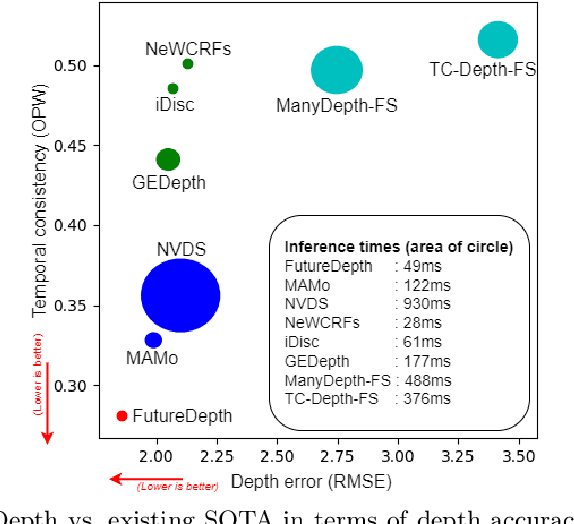
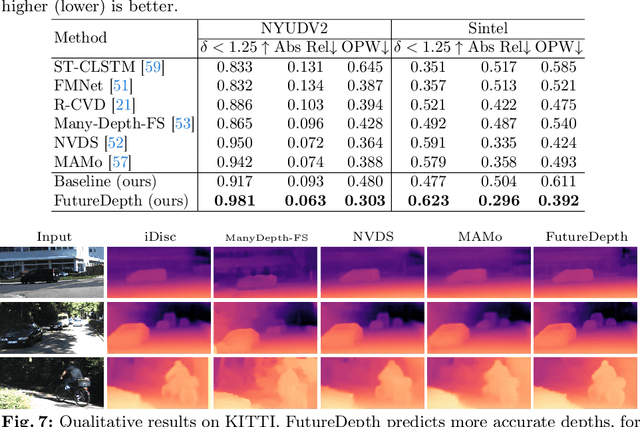
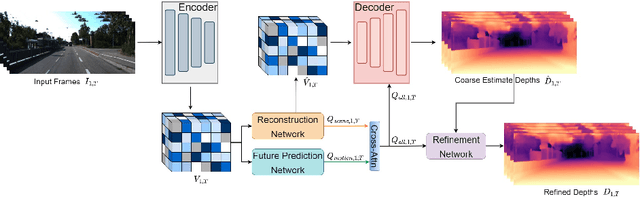
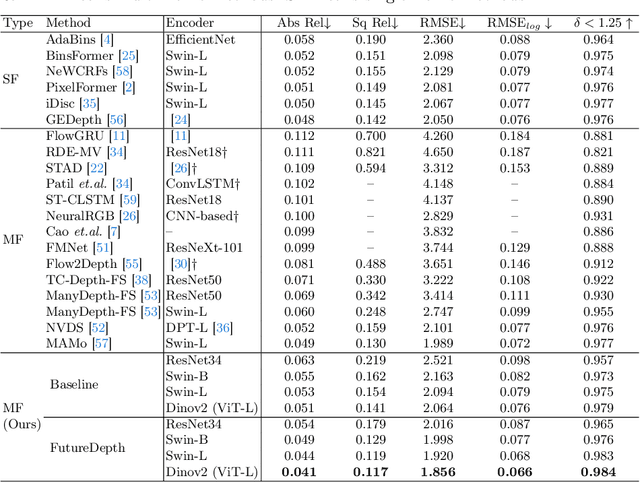
In this paper, we propose a novel video depth estimation approach, FutureDepth, which enables the model to implicitly leverage multi-frame and motion cues to improve depth estimation by making it learn to predict the future at training. More specifically, we propose a future prediction network, F-Net, which takes the features of multiple consecutive frames and is trained to predict multi-frame features one time step ahead iteratively. In this way, F-Net learns the underlying motion and correspondence information, and we incorporate its features into the depth decoding process. Additionally, to enrich the learning of multiframe correspondence cues, we further leverage a reconstruction network, R-Net, which is trained via adaptively masked auto-encoding of multiframe feature volumes. At inference time, both F-Net and R-Net are used to produce queries to work with the depth decoder, as well as a final refinement network. Through extensive experiments on several benchmarks, i.e., NYUDv2, KITTI, DDAD, and Sintel, which cover indoor, driving, and open-domain scenarios, we show that FutureDepth significantly improves upon baseline models, outperforms existing video depth estimation methods, and sets new state-of-the-art (SOTA) accuracy. Furthermore, FutureDepth is more efficient than existing SOTA video depth estimation models and has similar latencies when comparing to monocular models
HexaGen3D: StableDiffusion is just one step away from Fast and Diverse Text-to-3D Generation
Jan 15, 2024Despite the latest remarkable advances in generative modeling, efficient generation of high-quality 3D assets from textual prompts remains a difficult task. A key challenge lies in data scarcity: the most extensive 3D datasets encompass merely millions of assets, while their 2D counterparts contain billions of text-image pairs. To address this, we propose a novel approach which harnesses the power of large, pretrained 2D diffusion models. More specifically, our approach, HexaGen3D, fine-tunes a pretrained text-to-image model to jointly predict 6 orthographic projections and the corresponding latent triplane. We then decode these latents to generate a textured mesh. HexaGen3D does not require per-sample optimization, and can infer high-quality and diverse objects from textual prompts in 7 seconds, offering significantly better quality-to-latency trade-offs when comparing to existing approaches. Furthermore, HexaGen3D demonstrates strong generalization to new objects or compositions.
MAMo: Leveraging Memory and Attention for Monocular Video Depth Estimation
Jul 26, 2023We propose MAMo, a novel memory and attention frame-work for monocular video depth estimation. MAMo can augment and improve any single-image depth estimation networks into video depth estimation models, enabling them to take advantage of the temporal information to predict more accurate depth. In MAMo, we augment model with memory which aids the depth prediction as the model streams through the video. Specifically, the memory stores learned visual and displacement tokens of the previous time instances. This allows the depth network to cross-reference relevant features from the past when predicting depth on the current frame. We introduce a novel scheme to continuously update the memory, optimizing it to keep tokens that correspond with both the past and the present visual information. We adopt attention-based approach to process memory features where we first learn the spatio-temporal relation among the resultant visual and displacement memory tokens using self-attention module. Further, the output features of self-attention are aggregated with the current visual features through cross-attention. The cross-attended features are finally given to a decoder to predict depth on the current frame. Through extensive experiments on several benchmarks, including KITTI, NYU-Depth V2, and DDAD, we show that MAMo consistently improves monocular depth estimation networks and sets new state-of-the-art (SOTA) accuracy. Notably, our MAMo video depth estimation provides higher accuracy with lower latency, when omparing to SOTA cost-volume-based video depth models.