 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDouble-P: Hierarchical Top-P Sparse Attention for Long-Context LLMs
Feb 05, 2026As long-context inference becomes central to large language models (LLMs), attention over growing key-value caches emerges as a dominant decoding bottleneck, motivating sparse attention for scalable inference. Fixed-budget top-k sparse attention cannot adapt to heterogeneous attention distributions across heads and layers, whereas top-p sparse attention directly preserves attention mass and provides stronger accuracy guarantees. Existing top-p methods, however, fail to jointly optimize top-p accuracy, selection overhead, and sparse attention cost, which limits their overall efficiency. We present Double-P, a hierarchical sparse attention framework that optimizes all three stages. Double-P first performs coarse-grained top-p estimation at the cluster level using size-weighted centroids, then adaptively refines computation through a second top-p stage that allocates token-level attention only when needed. Across long-context benchmarks, Double-P consistently achieves near-zero accuracy drop, reducing attention computation overhead by up to 1.8x and delivers up to 1.3x end-to-end decoding speedup over state-of-the-art fixed-budget sparse attention methods.
Generative Scenario Rollouts for End-to-End Autonomous Driving
Jan 16, 2026Vision-Language-Action (VLA) models are emerging as highly effective planning models for end-to-end autonomous driving systems. However, current works mostly rely on imitation learning from sparse trajectory annotations and under-utilize their potential as generative models. We propose Generative Scenario Rollouts (GeRo), a plug-and-play framework for VLA models that jointly performs planning and generation of language-grounded future traffic scenes through an autoregressive rollout strategy. First, a VLA model is trained to encode ego vehicle and agent dynamics into latent tokens under supervision from planning, motion, and language tasks, facilitating text-aligned generation. Next, GeRo performs language-conditioned autoregressive generation. Given multi-view images, a scenario description, and ego-action questions, it generates future latent tokens and textual responses to guide long-horizon rollouts. A rollout-consistency loss stabilizes predictions using ground truth or pseudo-labels, mitigating drift and preserving text-action alignment. This design enables GeRo to perform temporally consistent, language-grounded rollouts that support long-horizon reasoning and multi-agent planning. On Bench2Drive, GeRo improves driving score and success rate by +15.7 and +26.2, respectively. By integrating reinforcement learning with generative rollouts, GeRo achieves state-of-the-art closed-loop and open-loop performance, demonstrating strong zero-shot robustness. These results highlight the promise of generative, language-conditioned reasoning as a foundation for safer and more interpretable end-to-end autonomous driving.
Do-Undo: Generating and Reversing Physical Actions in Vision-Language Models
Dec 15, 2025We introduce the Do-Undo task and benchmark to address a critical gap in vision-language models: understanding and generating physically plausible scene transformations driven by real-world actions. Unlike prior work focused on object-level edits, Do-Undo requires models to simulate the outcome of a physical action and then accurately reverse it, reflecting true cause-and-effect in the visual world. We curate a large-scale dataset of reversible actions from real-world videos and design a training strategy enforcing consistency for robust action grounding. Our experiments reveal that current models struggle with physical reversibility, underscoring the importance of this task for embodied AI, robotics, and physics-aware generative modeling. Do-Undo establishes an intuitive testbed for evaluating and advancing physical reasoning in multimodal systems.
Neodragon: Mobile Video Generation using Diffusion Transformer
Nov 08, 2025We introduce Neodragon, a text-to-video system capable of generating 2s (49 frames @24 fps) videos at the 640x1024 resolution directly on a Qualcomm Hexagon NPU in a record 6.7s (7 FPS). Differing from existing transformer-based offline text-to-video generation models, Neodragon is the first to have been specifically optimised for mobile hardware to achieve efficient and high-fidelity video synthesis. We achieve this through four key technical contributions: (1) Replacing the original large 4.762B T5xxl Text-Encoder with a much smaller 0.2B DT5 (DistilT5) with minimal quality loss, enabled through a novel Text-Encoder Distillation procedure. (2) Proposing an Asymmetric Decoder Distillation approach allowing us to replace the native codec-latent-VAE decoder with a more efficient one, without disturbing the generative latent-space of the generation pipeline. (3) Pruning of MMDiT blocks within the denoiser backbone based on their relative importance, with recovery of original performance through a two-stage distillation process. (4) Reducing the NFE (Neural Functional Evaluation) requirement of the denoiser by performing step distillation using DMD adapted for pyramidal flow-matching, thereby substantially accelerating video generation. When paired with an optimised SSD1B first-frame image generator and QuickSRNet for 2x super-resolution, our end-to-end Neodragon system becomes a highly parameter (4.945B full model), memory (3.5GB peak RAM usage), and runtime (6.7s E2E latency) efficient mobile-friendly model, while achieving a VBench total score of 81.61. By enabling low-cost, private, and on-device text-to-video synthesis, Neodragon democratizes AI-based video content creation, empowering creators to generate high-quality videos without reliance on cloud services. Code and model will be made publicly available at our website: https://qualcomm-ai-research.github.io/neodragon
DisCo: Reinforcement with Diversity Constraints for Multi-Human Generation
Oct 01, 2025State-of-the-art text-to-image models excel at realism but collapse on multi-human prompts - duplicating faces, merging identities, and miscounting individuals. We introduce DisCo (Reinforcement with Diversity Constraints), the first RL-based framework to directly optimize identity diversity in multi-human generation. DisCo fine-tunes flow-matching models via Group-Relative Policy Optimization (GRPO) with a compositional reward that (i) penalizes intra-image facial similarity, (ii) discourages cross-sample identity repetition, (iii) enforces accurate person counts, and (iv) preserves visual fidelity through human preference scores. A single-stage curriculum stabilizes training as complexity scales, requiring no extra annotations. On the DiverseHumans Testset, DisCo achieves 98.6 Unique Face Accuracy and near-perfect Global Identity Spread - surpassing both open-source and proprietary methods (e.g., Gemini, GPT-Image) while maintaining competitive perceptual quality. Our results establish DisCo as a scalable, annotation-free solution that resolves the long-standing identity crisis in generative models and sets a new benchmark for compositional multi-human generation.
MultiHuman-Testbench: Benchmarking Image Generation for Multiple Humans
Jun 25, 2025Generation of images containing multiple humans, performing complex actions, while preserving their facial identities, is a significant challenge. A major factor contributing to this is the lack of a a dedicated benchmark. To address this, we introduce MultiHuman-Testbench, a novel benchmark for rigorously evaluating generative models for multi-human generation. The benchmark comprises 1800 samples, including carefully curated text prompts, describing a range of simple to complex human actions. These prompts are matched with a total of 5,550 unique human face images, sampled uniformly to ensure diversity across age, ethnic background, and gender. Alongside captions, we provide human-selected pose conditioning images which accurately match the prompt. We propose a multi-faceted evaluation suite employing four key metrics to quantify face count, ID similarity, prompt alignment, and action detection. We conduct a thorough evaluation of a diverse set of models, including zero-shot approaches and training-based methods, with and without regional priors. We also propose novel techniques to incorporate image and region isolation using human segmentation and Hungarian matching, significantly improving ID similarity. Our proposed benchmark and key findings provide valuable insights and a standardized tool for advancing research in multi-human image generation.
ODG: Occupancy Prediction Using Dual Gaussians
Jun 12, 2025Occupancy prediction infers fine-grained 3D geometry and semantics from camera images of the surrounding environment, making it a critical perception task for autonomous driving. Existing methods either adopt dense grids as scene representation, which is difficult to scale to high resolution, or learn the entire scene using a single set of sparse queries, which is insufficient to handle the various object characteristics. In this paper, we present ODG, a hierarchical dual sparse Gaussian representation to effectively capture complex scene dynamics. Building upon the observation that driving scenes can be universally decomposed into static and dynamic counterparts, we define dual Gaussian queries to better model the diverse scene objects. We utilize a hierarchical Gaussian transformer to predict the occupied voxel centers and semantic classes along with the Gaussian parameters. Leveraging the real-time rendering capability of 3D Gaussian Splatting, we also impose rendering supervision with available depth and semantic map annotations injecting pixel-level alignment to boost occupancy learning. Extensive experiments on the Occ3D-nuScenes and Occ3D-Waymo benchmarks demonstrate our proposed method sets new state-of-the-art results while maintaining low inference cost.
RoCA: Robust Cross-Domain End-to-End Autonomous Driving
Jun 11, 2025End-to-end (E2E) autonomous driving has recently emerged as a new paradigm, offering significant potential. However, few studies have looked into the practical challenge of deployment across domains (e.g., cities). Although several works have incorporated Large Language Models (LLMs) to leverage their open-world knowledge, LLMs do not guarantee cross-domain driving performance and may incur prohibitive retraining costs during domain adaptation. In this paper, we propose RoCA, a novel framework for robust cross-domain E2E autonomous driving. RoCA formulates the joint probabilistic distribution over the tokens that encode ego and surrounding vehicle information in the E2E pipeline. Instantiating with a Gaussian process (GP), RoCA learns a set of basis tokens with corresponding trajectories, which span diverse driving scenarios. Then, given any driving scene, it is able to probabilistically infer the future trajectory. By using RoCA together with a base E2E model in source-domain training, we improve the generalizability of the base model, without requiring extra inference computation. In addition, RoCA enables robust adaptation on new target domains, significantly outperforming direct finetuning. We extensively evaluate RoCA on various cross-domain scenarios and show that it achieves strong domain generalization and adaptation performance.
DySS: Dynamic Queries and State-Space Learning for Efficient 3D Object Detection from Multi-Camera Videos
Jun 11, 2025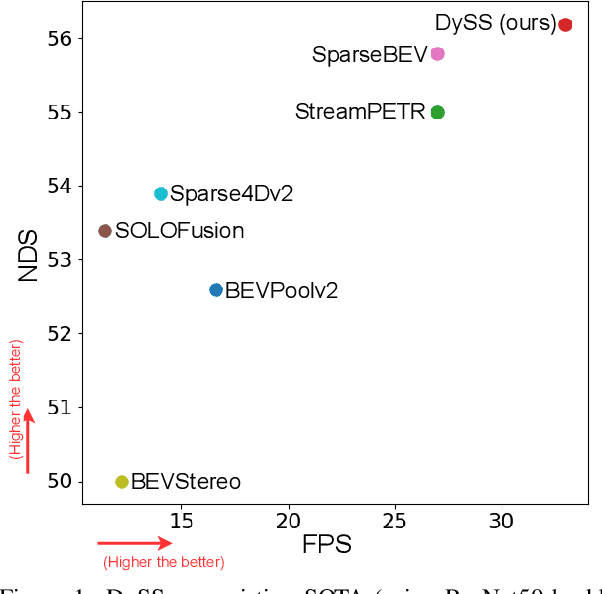
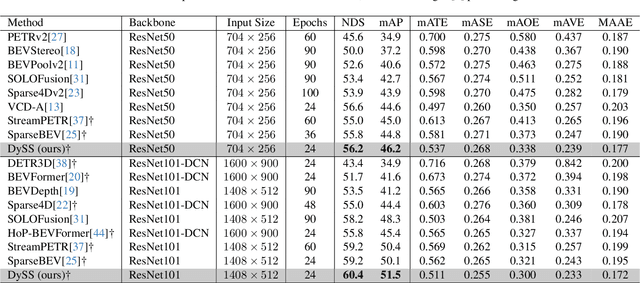
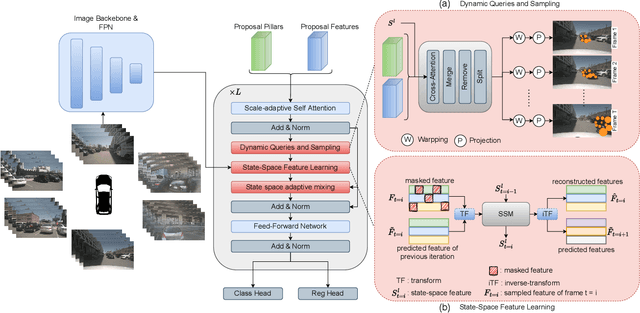
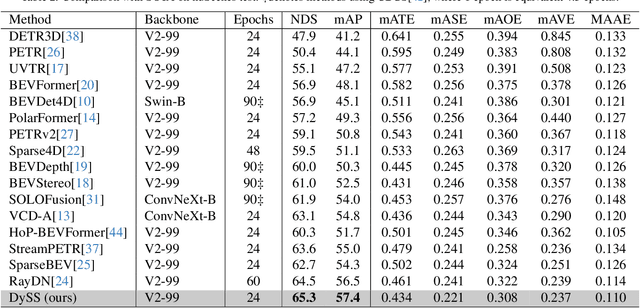
Camera-based 3D object detection in Bird's Eye View (BEV) is one of the most important perception tasks in autonomous driving. Earlier methods rely on dense BEV features, which are costly to construct. More recent works explore sparse query-based detection. However, they still require a large number of queries and can become expensive to run when more video frames are used. In this paper, we propose DySS, a novel method that employs state-space learning and dynamic queries. More specifically, DySS leverages a state-space model (SSM) to sequentially process the sampled features over time steps. In order to encourage the model to better capture the underlying motion and correspondence information, we introduce auxiliary tasks of future prediction and masked reconstruction to better train the SSM. The state of the SSM then provides an informative yet efficient summarization of the scene. Based on the state-space learned features, we dynamically update the queries via merge, remove, and split operations, which help maintain a useful, lean set of detection queries throughout the network. Our proposed DySS achieves both superior detection performance and efficient inference. Specifically, on the nuScenes test split, DySS achieves 65.31 NDS and 57.4 mAP, outperforming the latest state of the art. On the val split, DySS achieves 56.2 NDS and 46.2 mAP, as well as a real-time inference speed of 33 FPS.
BePo: Leveraging Birds Eye View and Sparse Points for Efficient and Accurate 3D Occupancy Prediction
Jun 08, 20253D occupancy provides fine-grained 3D geometry and semantics for scene understanding which is critical for autonomous driving. Most existing methods, however, carry high compute costs, requiring dense 3D feature volume and cross-attention to effectively aggregate information. More recent works have adopted Bird's Eye View (BEV) or sparse points as scene representation with much reduced cost, but still suffer from their respective shortcomings. More concretely, BEV struggles with small objects that often experience significant information loss after being projected to the ground plane. On the other hand, points can flexibly model little objects in 3D, but is inefficient at capturing flat surfaces or large objects. To address these challenges, in this paper, we present a novel 3D occupancy prediction approach, BePo, which combines BEV and sparse points based representations. We propose a dual-branch design: a query-based sparse points branch and a BEV branch. The 3D information learned in the sparse points branch is shared with the BEV stream via cross-attention, which enriches the weakened signals of difficult objects on the BEV plane. The outputs of both branches are finally fused to generate predicted 3D occupancy. We conduct extensive experiments on the Occ3D-nuScenes and Occ3D-Waymo benchmarks that demonstrate the superiority of our proposed BePo. Moreover, BePo also delivers competitive inference speed when compared to the latest efficient approaches.