 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking RAG in Long Videos: What to Retrieve and How to Use It?
Jun 11, 2026Retrieval-augmented generation is moving beyond text into long, egocentric video, where systems must select query-relevant chunks across multiple modalities and temporal granularities. Yet progress in VideoRAG is limited by two gaps: existing benchmarks allow queries to be answered without the video, obscuring retrieval errors, and prior methods apply a single modality-granularity configuration per query, ignoring chunk-level variability. We address both by introducing V-RAGBench, a benchmark of $\langle$query, evidence chunk, answer$\rangle$ triplets that enables faithful, decoupled evaluation of retrieval and generation, and CARVE, a simple method that runs parallel retrievers across configurations and employs chunk-adaptive reranking to identify the winning configuration for each chunk. Each chunk then enters the generator under its winning configuration selected during retrieval, yielding an interleaved evidence form where the chunk-level decision propagates across both stages. CARVE outperforms eight recent VideoRAG baselines, with the chunks supplied to the generator interleaving multiple configurations rather than sharing a single one, a behavior unattainable by query-level methods.
Concept-Aware LoRA for Domain-Aligned Segmentation Dataset Generation
Mar 28, 2025This paper addresses the challenge of data scarcity in semantic segmentation by generating datasets through text-to-image (T2I) generation models, reducing image acquisition and labeling costs. Segmentation dataset generation faces two key challenges: 1) aligning generated samples with the target domain and 2) producing informative samples beyond the training data. Fine-tuning T2I models can help generate samples aligned with the target domain. However, it often overfits and memorizes training data, limiting their ability to generate diverse and well-aligned samples. To overcome these issues, we propose Concept-Aware LoRA (CA-LoRA), a novel fine-tuning approach that selectively identifies and updates only the weights associated with necessary concepts (e.g., style or viewpoint) for domain alignment while preserving the pretrained knowledge of the T2I model to produce informative samples. We demonstrate its effectiveness in generating datasets for urban-scene segmentation, outperforming baseline and state-of-the-art methods in in-domain (few-shot and fully-supervised) settings, as well as in domain generalization tasks, especially under challenging conditions such as adverse weather and varying illumination, further highlighting its superiority.
Knowledge Distillation from Non-streaming to Streaming ASR Encoder using Auxiliary Non-streaming Layer
Aug 31, 2023Streaming automatic speech recognition (ASR) models are restricted from accessing future context, which results in worse performance compared to the non-streaming models. To improve the performance of streaming ASR, knowledge distillation (KD) from the non-streaming to streaming model has been studied, mainly focusing on aligning the output token probabilities. In this paper, we propose a layer-to-layer KD from the teacher encoder to the student encoder. To ensure that features are extracted using the same context, we insert auxiliary non-streaming branches to the student and perform KD from the non-streaming teacher layer to the non-streaming auxiliary layer. We design a special KD loss that leverages the autoregressive predictive coding (APC) mechanism to encourage the streaming model to predict unseen future contexts. Experimental results show that the proposed method can significantly reduce the word error rate compared to previous token probability distillation methods.
SubSpectral Normalization for Neural Audio Data Processing
Mar 25, 2021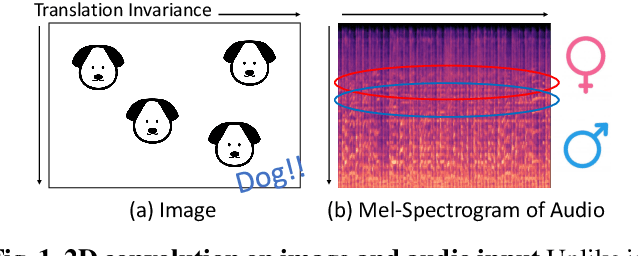

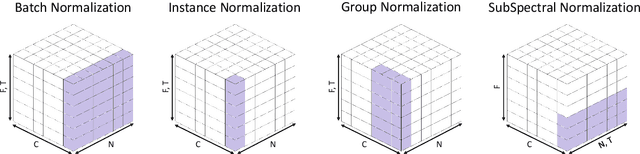
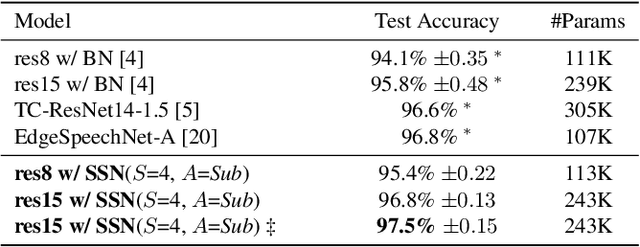
Convolutional Neural Networks are widely used in various machine learning domains. In image processing, the features can be obtained by applying 2D convolution to all spatial dimensions of the input. However, in the audio case, frequency domain input like Mel-Spectrogram has different and unique characteristics in the frequency dimension. Thus, there is a need for a method that allows the 2D convolution layer to handle the frequency dimension differently. In this work, we introduce SubSpectral Normalization (SSN), which splits the input frequency dimension into several groups (sub-bands) and performs a different normalization for each group. SSN also includes an affine transformation that can be applied to each group. Our method removes the inter-frequency deflection while the network learns a frequency-aware characteristic. In the experiments with audio data, we observed that SSN can efficiently improve the network's performance.
Query-by-example on-device keyword spotting
Oct 22, 2019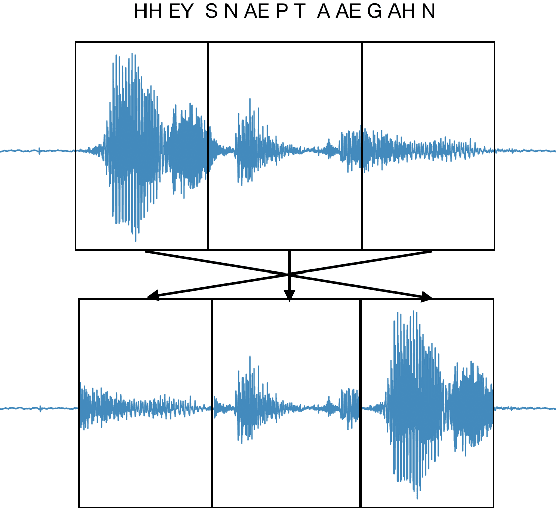
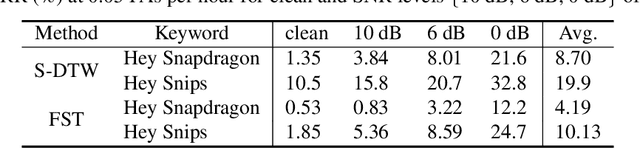
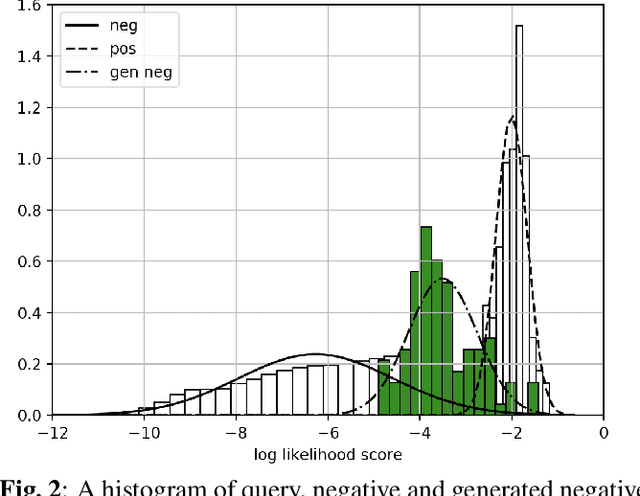
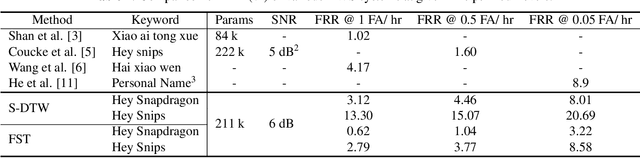
A keyword spotting (KWS) system determines the existence of, usually predefined, keyword in a continuous speech stream. This paper presents a query-by-example on-device KWS system which is user-specific. The proposed system consists of two main steps: query enrollment and testing. In query enrollment step, phonetic posteriors are output by a small-footprint automatic speech recognition model based on connectionist temporal classification. Using the phonetic-level posteriorgram, hypothesis graph of finite-state transducer (FST) is built, thus can enroll any keywords thus avoiding an out-of-vocabulary problem. In testing, a log-likelihood is scored for input audio using the FST. We propose a threshold prediction method while using the user-specific keyword hypothesis only. The system generates query-specific negatives by rearranging each query utterance in waveform. The threshold is decided based on the enrollment queries and generated negatives. We tested two keywords in English, and the proposed work shows promising performance while preserving simplicity.
Weakly Labeled Sound Event Detection Using Tri-training and Adversarial Learning
Oct 14, 2019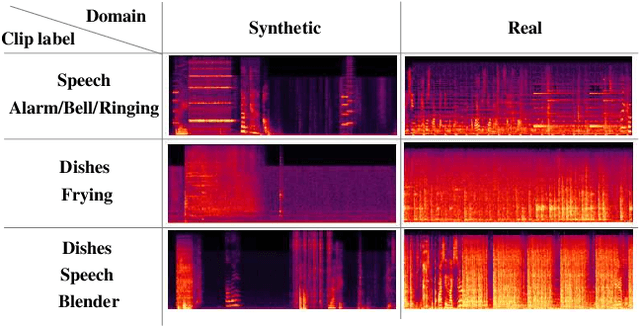
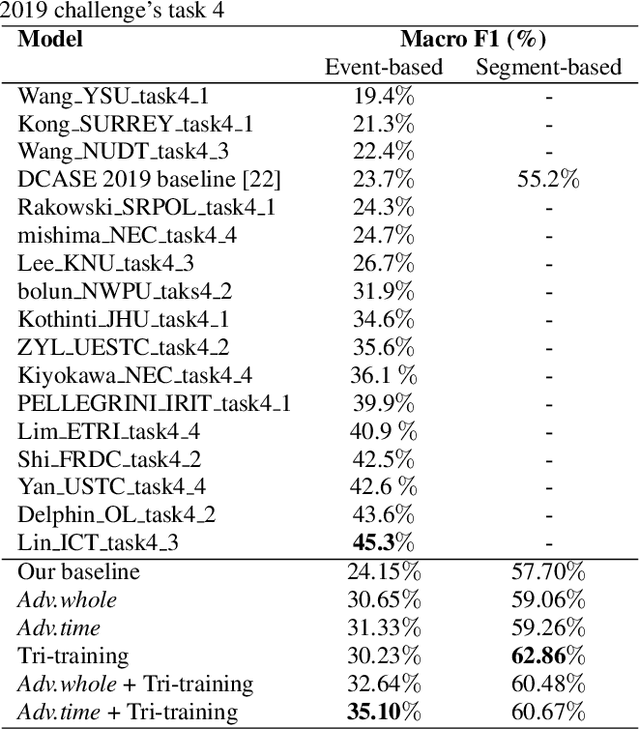
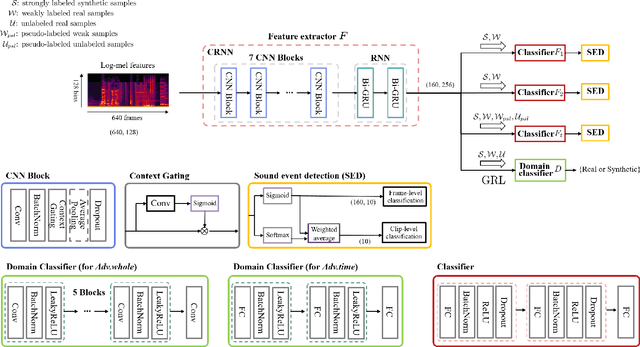
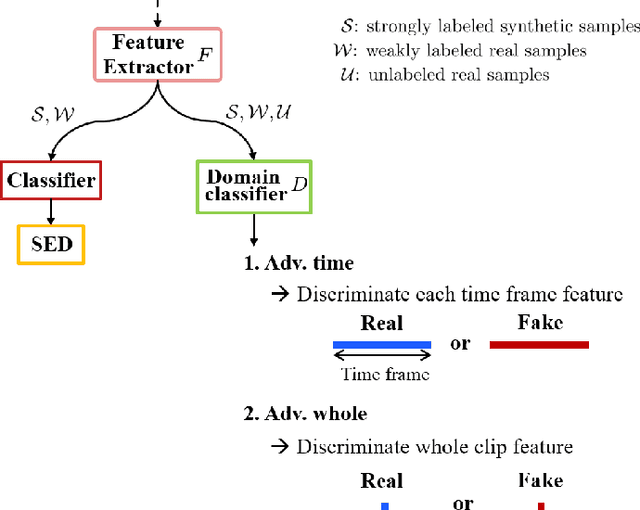
This paper considers a semi-supervised learning framework for weakly labeled polyphonic sound event detection problems for the DCASE 2019 challenge's task4 by combining both the tri-training and adversarial learning. The goal of the task4 is to detect onsets and offsets of multiple sound events in a single audio clip. The entire dataset consists of the synthetic data with a strong label (sound event labels with boundaries) and real data with weakly labeled (sound event labels) and unlabeled dataset. Given this dataset, we apply the tri-training where two different classifiers are used to obtain pseudo labels on the weakly labeled and unlabeled dataset, and the final classifier is trained using the strongly labeled dataset and weakly/unlabeled dataset with pseudo labels. Also, we apply the adversarial learning to reduce the domain gap between the real and synthetic dataset. We evaluated our learning framework using the validation set of the task4 dataset, and in the experiments, our learning framework shows a considerable performance improvement over the baseline model.
Acoustic Scene Classification Based on a Large-margin Factorized CNN
Oct 14, 2019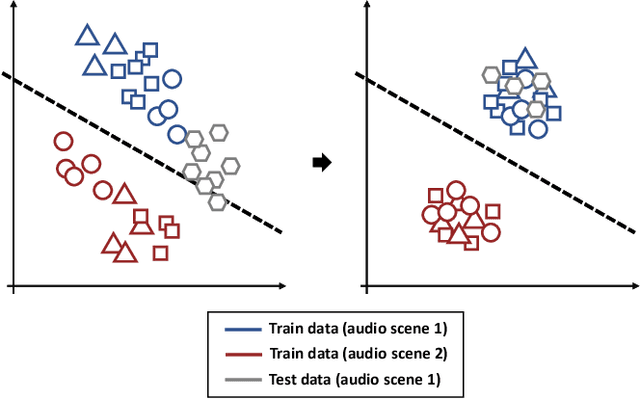
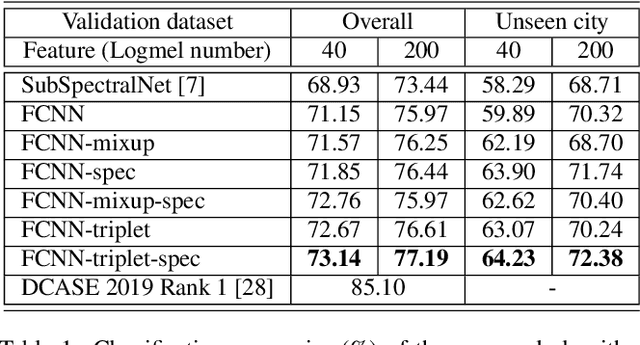
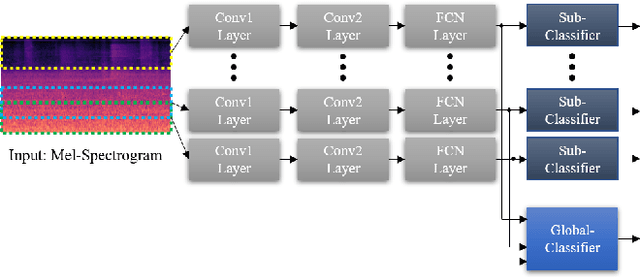
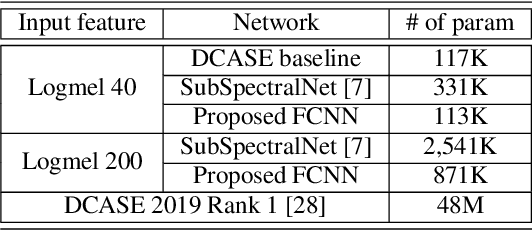
In this paper, we present an acoustic scene classification framework based on a large-margin factorized convolutional neural network (CNN). We adopt the factorized CNN to learn the patterns in the time-frequency domain by factorizing the 2D kernel into two separate 1D kernels. The factorized kernel leads to learn the main component of two patterns: the long-term ambient and short-term event sounds which are the key patterns of the audio scene classification. In training our model, we consider the loss function based on the triplet sampling such that the same audio scene samples from different environments are minimized, and simultaneously the different audio scene samples are maximized. With this loss function, the samples from the same audio scene are clustered independently of the environment, and thus we can get the classifier with better generalization ability in an unseen environment. We evaluated our audio scene classification framework using the dataset of the DCASE challenge 2019 task1A. Experimental results show that the proposed algorithm improves the performance of the baseline network and reduces the number of parameters to one third. Furthermore, the performance gain is higher on unseen data, and it shows that the proposed algorithm has better generalization ability.
Orthogonality Constrained Multi-Head Attention For Keyword Spotting
Oct 10, 2019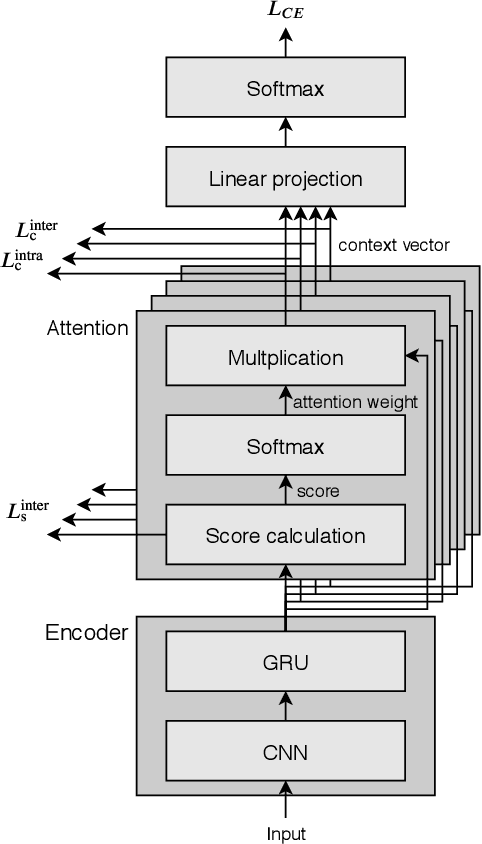
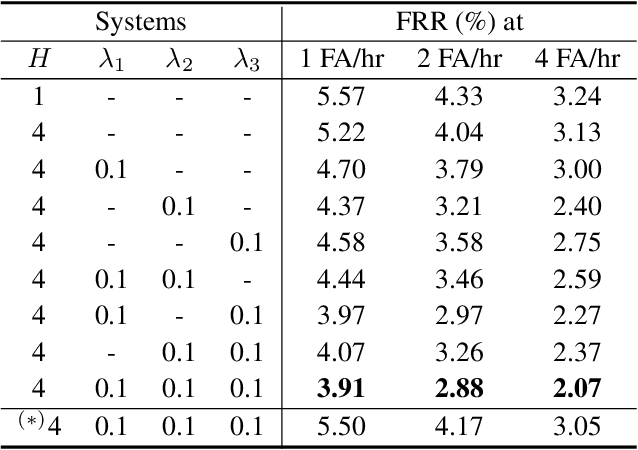
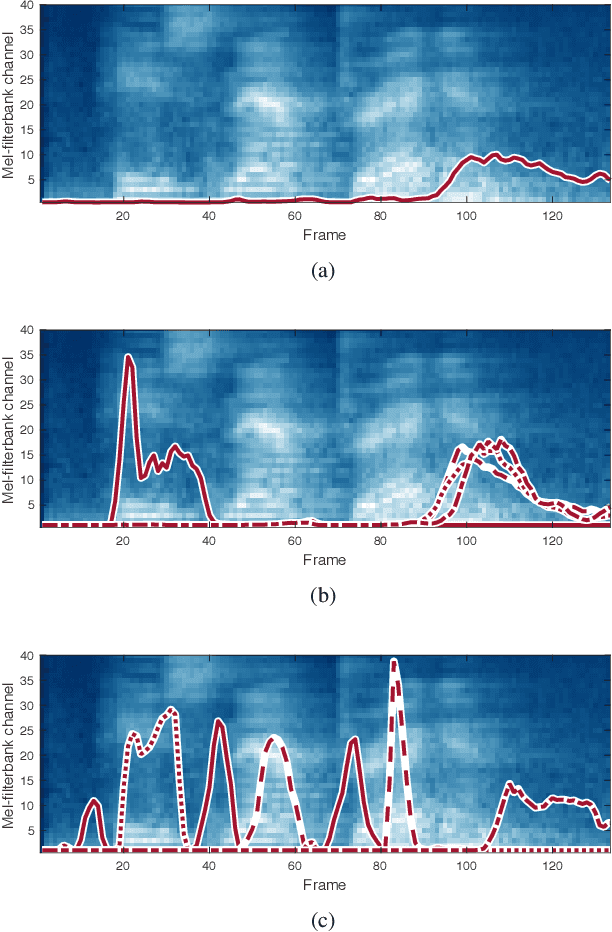

Multi-head attention mechanism is capable of learning various representations from sequential data while paying attention to different subsequences, e.g., word-pieces or syllables in a spoken word. From the subsequences, it retrieves richer information than a single-head attention which only summarizes the whole sequence into one context vector. However, a naive use of the multi-head attention does not guarantee such richness as the attention heads may have positional and representational redundancy. In this paper, we propose a regularization technique for multi-head attention mechanism in an end-to-end neural keyword spotting system. Augmenting regularization terms which penalize positional and contextual non-orthogonality between the attention heads encourages to output different representations from separate subsequences, which in turn enables leveraging structured information without explicit sequence models such as hidden Markov models. In addition, intra-head contextual non-orthogonality regularization encourages each attention head to have similar representations across keyword examples, which helps classification by reducing feature variability. The experimental results demonstrate that the proposed regularization technique significantly improves the keyword spotting performance for the keyword "Hey Snapdragon".
An End-to-End Text-independent Speaker Verification Framework with a Keyword Adversarial Network
Aug 06, 2019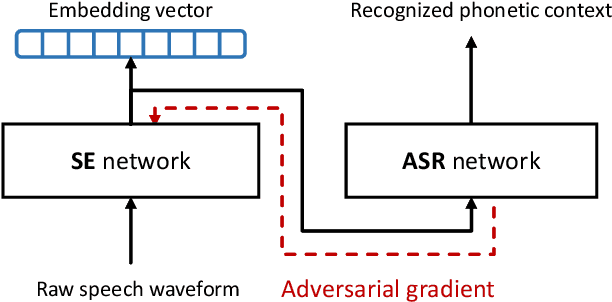

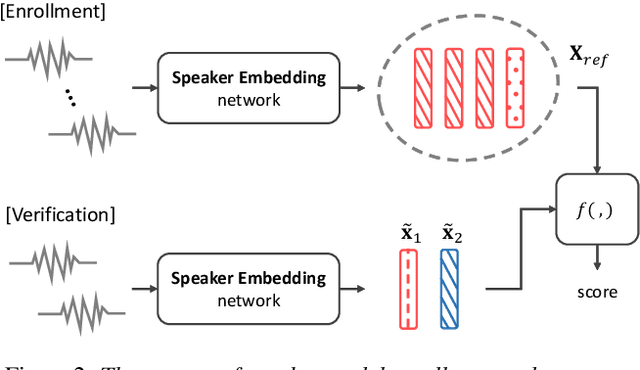
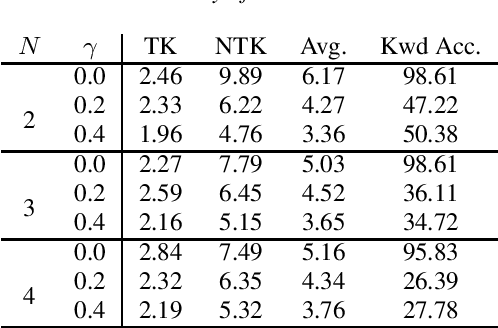
This paper presents an end-to-end text-independent speaker verification framework by jointly considering the speaker embedding (SE) network and automatic speech recognition (ASR) network. The SE network learns to output an embedding vector which distinguishes the speaker characteristics of the input utterance, while the ASR network learns to recognize the phonetic context of the input. In training our speaker verification framework, we consider both the triplet loss minimization and adversarial gradient of the ASR network to obtain more discriminative and text-independent speaker embedding vectors. With the triplet loss, the distances between the embedding vectors of the same speaker are minimized while those of different speakers are maximized. Also, with the adversarial gradient of the ASR network, the text-dependency of the speaker embedding vector can be reduced. In the experiments, we evaluated our speaker verification framework using the LibriSpeech and CHiME 2013 dataset, and the evaluation results show that our speaker verification framework shows lower equal error rate and better text-independency compared to the other approaches.