 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly Labeled Sound Event Detection Using Tri-training and Adversarial Learning
Oct 14, 2019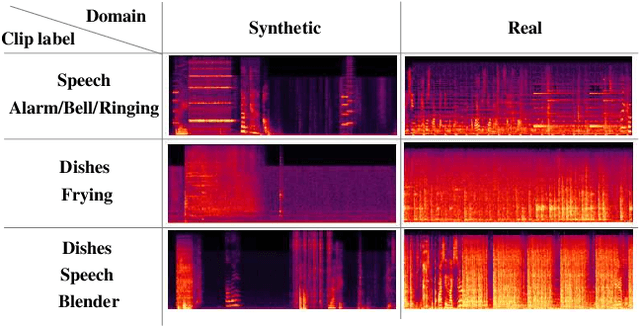
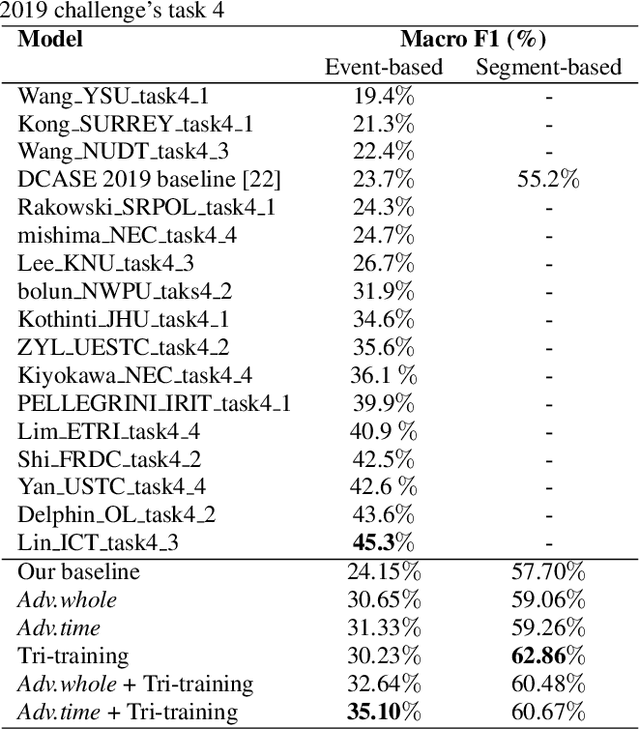
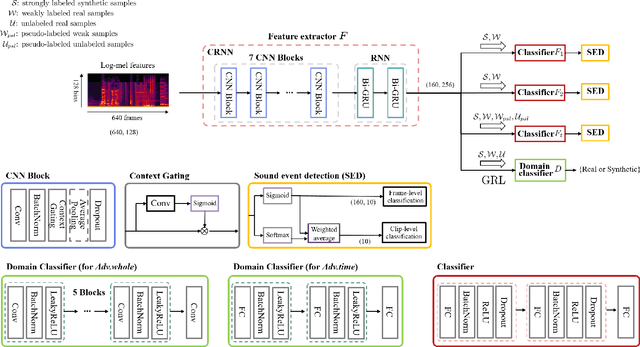
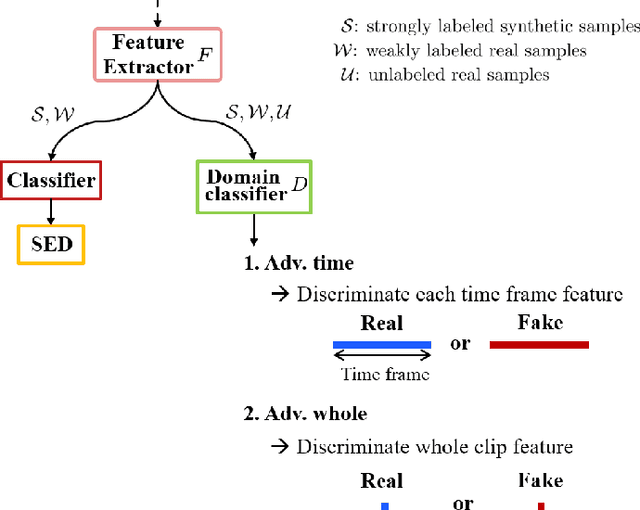
This paper considers a semi-supervised learning framework for weakly labeled polyphonic sound event detection problems for the DCASE 2019 challenge's task4 by combining both the tri-training and adversarial learning. The goal of the task4 is to detect onsets and offsets of multiple sound events in a single audio clip. The entire dataset consists of the synthetic data with a strong label (sound event labels with boundaries) and real data with weakly labeled (sound event labels) and unlabeled dataset. Given this dataset, we apply the tri-training where two different classifiers are used to obtain pseudo labels on the weakly labeled and unlabeled dataset, and the final classifier is trained using the strongly labeled dataset and weakly/unlabeled dataset with pseudo labels. Also, we apply the adversarial learning to reduce the domain gap between the real and synthetic dataset. We evaluated our learning framework using the validation set of the task4 dataset, and in the experiments, our learning framework shows a considerable performance improvement over the baseline model.
Acoustic Scene Classification Based on a Large-margin Factorized CNN
Oct 14, 2019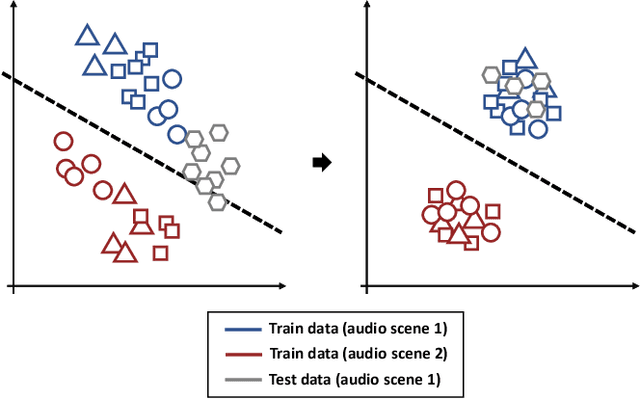
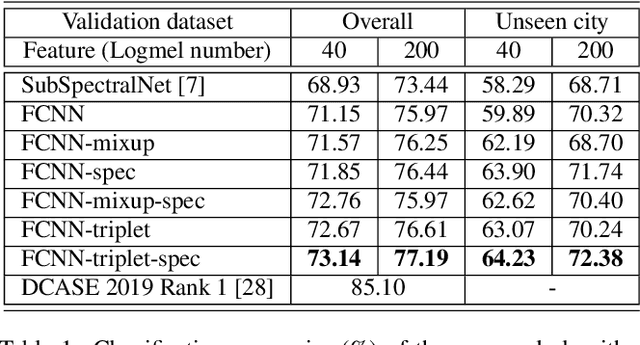
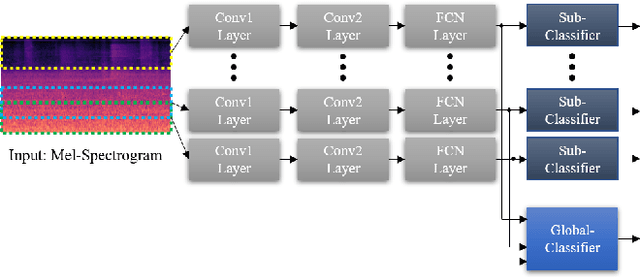
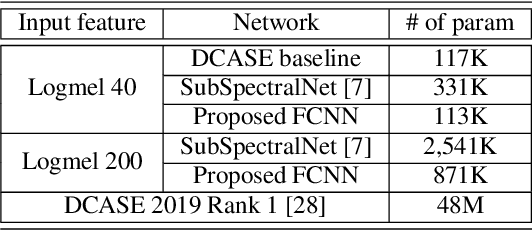
In this paper, we present an acoustic scene classification framework based on a large-margin factorized convolutional neural network (CNN). We adopt the factorized CNN to learn the patterns in the time-frequency domain by factorizing the 2D kernel into two separate 1D kernels. The factorized kernel leads to learn the main component of two patterns: the long-term ambient and short-term event sounds which are the key patterns of the audio scene classification. In training our model, we consider the loss function based on the triplet sampling such that the same audio scene samples from different environments are minimized, and simultaneously the different audio scene samples are maximized. With this loss function, the samples from the same audio scene are clustered independently of the environment, and thus we can get the classifier with better generalization ability in an unseen environment. We evaluated our audio scene classification framework using the dataset of the DCASE challenge 2019 task1A. Experimental results show that the proposed algorithm improves the performance of the baseline network and reduces the number of parameters to one third. Furthermore, the performance gain is higher on unseen data, and it shows that the proposed algorithm has better generalization ability.
An End-to-End Text-independent Speaker Verification Framework with a Keyword Adversarial Network
Aug 06, 2019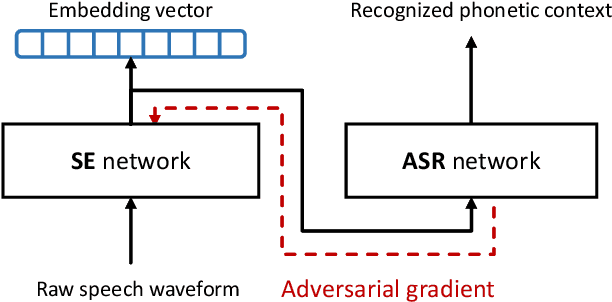

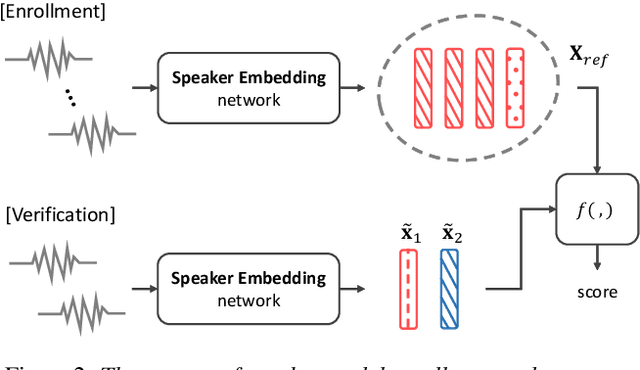
This paper presents an end-to-end text-independent speaker verification framework by jointly considering the speaker embedding (SE) network and automatic speech recognition (ASR) network. The SE network learns to output an embedding vector which distinguishes the speaker characteristics of the input utterance, while the ASR network learns to recognize the phonetic context of the input. In training our speaker verification framework, we consider both the triplet loss minimization and adversarial gradient of the ASR network to obtain more discriminative and text-independent speaker embedding vectors. With the triplet loss, the distances between the embedding vectors of the same speaker are minimized while those of different speakers are maximized. Also, with the adversarial gradient of the ASR network, the text-dependency of the speaker embedding vector can be reduced. In the experiments, we evaluated our speaker verification framework using the LibriSpeech and CHiME 2013 dataset, and the evaluation results show that our speaker verification framework shows lower equal error rate and better text-independency compared to the other approaches.