 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreaming Transformer for Hardware Efficient Voice Trigger Detection and False Trigger Mitigation
May 14, 2021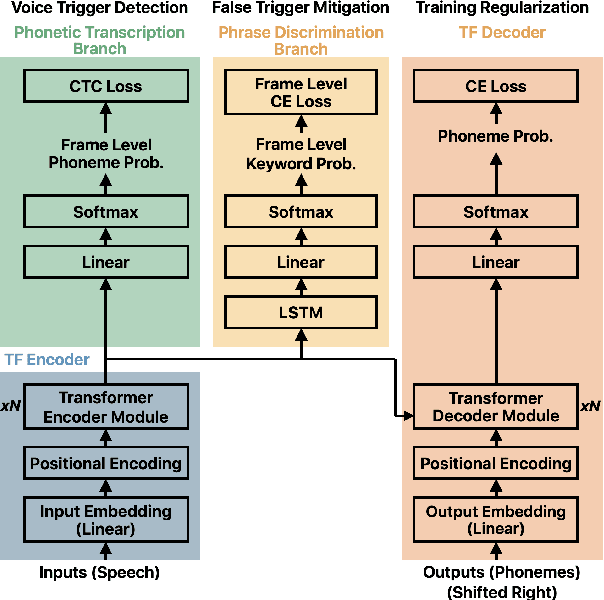
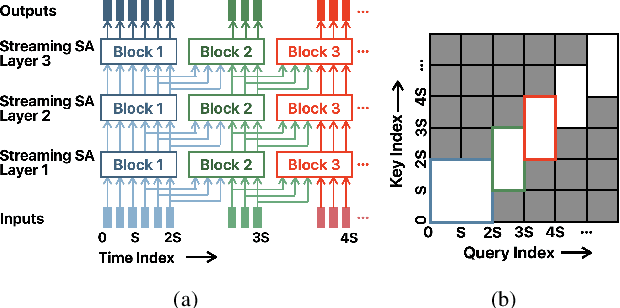

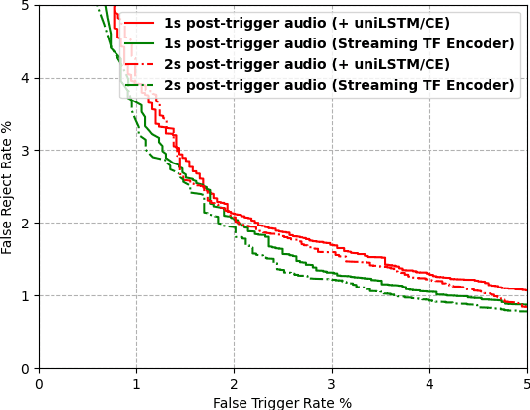
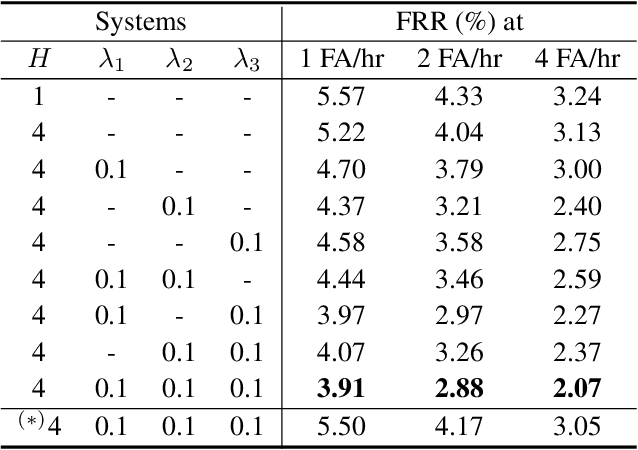
We present a unified and hardware efficient architecture for two stage voice trigger detection (VTD) and false trigger mitigation (FTM) tasks. Two stage VTD systems of voice assistants can get falsely activated to audio segments acoustically similar to the trigger phrase of interest. FTM systems cancel such activations by using post trigger audio context. Traditional FTM systems rely on automatic speech recognition lattices which are computationally expensive to obtain on device. We propose a streaming transformer (TF) encoder architecture, which progressively processes incoming audio chunks and maintains audio context to perform both VTD and FTM tasks using only acoustic features. The proposed joint model yields an average 18% relative reduction in false reject rate (FRR) for the VTD task at a given false alarm rate. Moreover, our model suppresses 95% of the false triggers with an additional one second of post-trigger audio. Finally, on-device measurements show 32% reduction in runtime memory and 56% reduction in inference time compared to non-streaming version of the model.
Orthogonality Constrained Multi-Head Attention For Keyword Spotting
Oct 10, 2019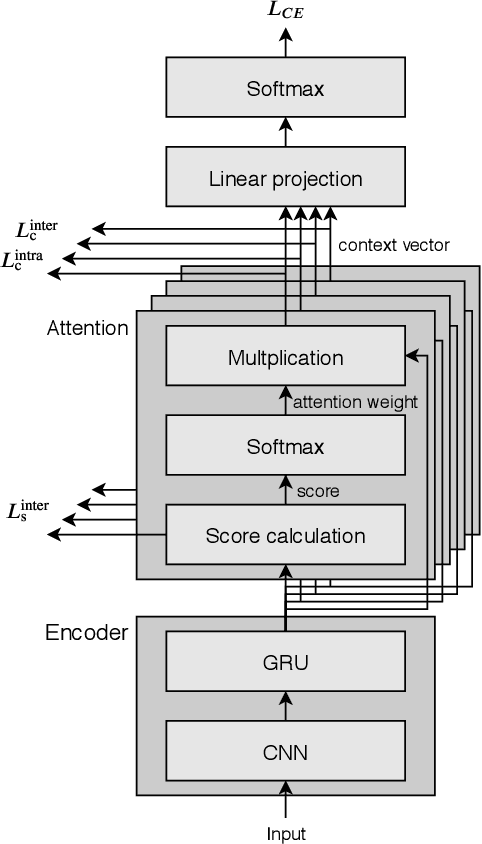
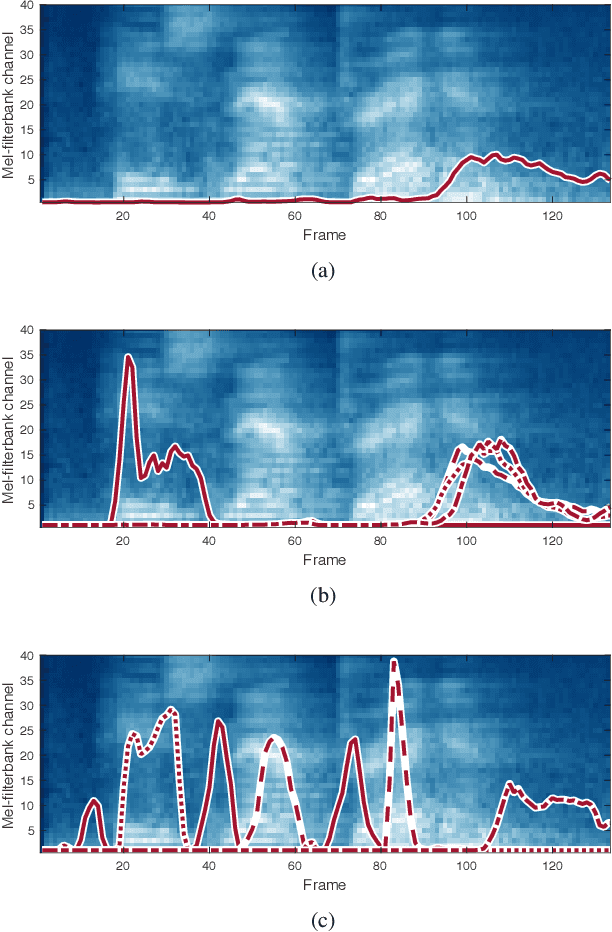

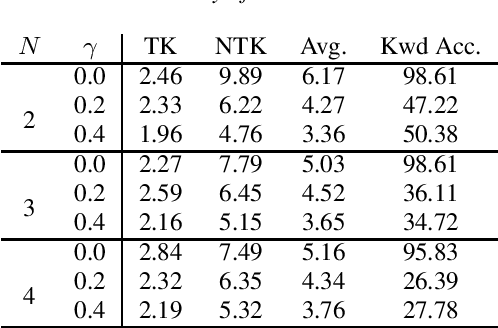
Multi-head attention mechanism is capable of learning various representations from sequential data while paying attention to different subsequences, e.g., word-pieces or syllables in a spoken word. From the subsequences, it retrieves richer information than a single-head attention which only summarizes the whole sequence into one context vector. However, a naive use of the multi-head attention does not guarantee such richness as the attention heads may have positional and representational redundancy. In this paper, we propose a regularization technique for multi-head attention mechanism in an end-to-end neural keyword spotting system. Augmenting regularization terms which penalize positional and contextual non-orthogonality between the attention heads encourages to output different representations from separate subsequences, which in turn enables leveraging structured information without explicit sequence models such as hidden Markov models. In addition, intra-head contextual non-orthogonality regularization encourages each attention head to have similar representations across keyword examples, which helps classification by reducing feature variability. The experimental results demonstrate that the proposed regularization technique significantly improves the keyword spotting performance for the keyword "Hey Snapdragon".
An End-to-End Text-independent Speaker Verification Framework with a Keyword Adversarial Network
Aug 06, 2019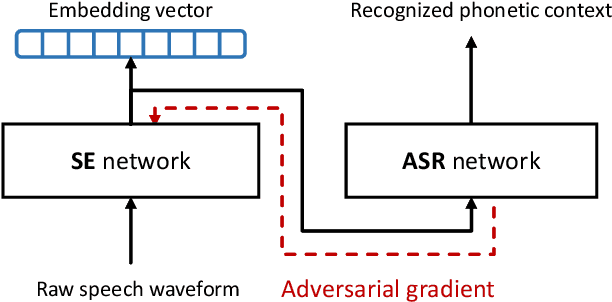

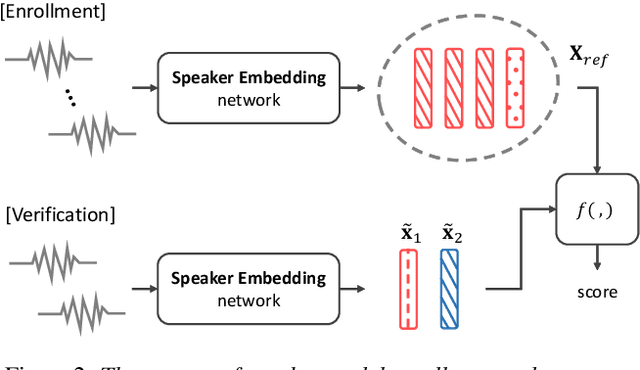
This paper presents an end-to-end text-independent speaker verification framework by jointly considering the speaker embedding (SE) network and automatic speech recognition (ASR) network. The SE network learns to output an embedding vector which distinguishes the speaker characteristics of the input utterance, while the ASR network learns to recognize the phonetic context of the input. In training our speaker verification framework, we consider both the triplet loss minimization and adversarial gradient of the ASR network to obtain more discriminative and text-independent speaker embedding vectors. With the triplet loss, the distances between the embedding vectors of the same speaker are minimized while those of different speakers are maximized. Also, with the adversarial gradient of the ASR network, the text-dependency of the speaker embedding vector can be reduced. In the experiments, we evaluated our speaker verification framework using the LibriSpeech and CHiME 2013 dataset, and the evaluation results show that our speaker verification framework shows lower equal error rate and better text-independency compared to the other approaches.