 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreaming on-device detection of device directed speech from voice and touch-based invocation
Oct 09, 2021
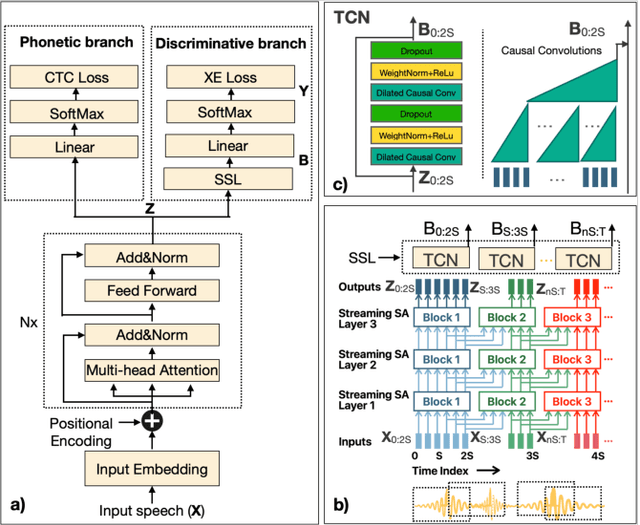
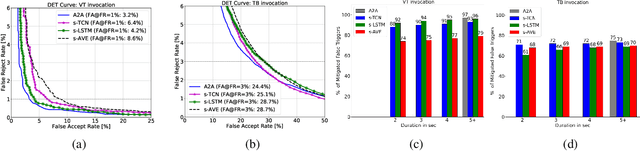
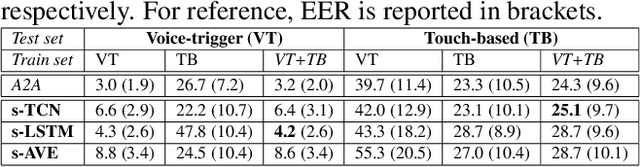
When interacting with smart devices such as mobile phones or wearables, the user typically invokes a virtual assistant (VA) by saying a keyword or by pressing a button on the device. However, in many cases, the VA can accidentally be invoked by the keyword-like speech or accidental button press, which may have implications on user experience and privacy. To this end, we propose an acoustic false-trigger-mitigation (FTM) approach for on-device device-directed speech detection that simultaneously handles the voice-trigger and touch-based invocation. To facilitate the model deployment on-device, we introduce a new streaming decision layer, derived using the notion of temporal convolutional networks (TCN) [1], known for their computational efficiency. To the best of our knowledge, this is the first approach that can detect device-directed speech from more than one invocation type in a streaming fashion. We compare this approach with streaming alternatives based on vanilla Average layer, and canonical LSTMs, and show: (i) that all the models show only a small degradation in accuracy compared with the invocation-specific models, and (ii) that the newly introduced streaming TCN consistently performs better or comparable with the alternatives, while mitigating device undirected speech faster in time, and with (relative) reduction in runtime peak-memory over the LSTM-based approach of 33% vs. 7%, when compared to a non-streaming counterpart.
Streaming Transformer for Hardware Efficient Voice Trigger Detection and False Trigger Mitigation
May 14, 2021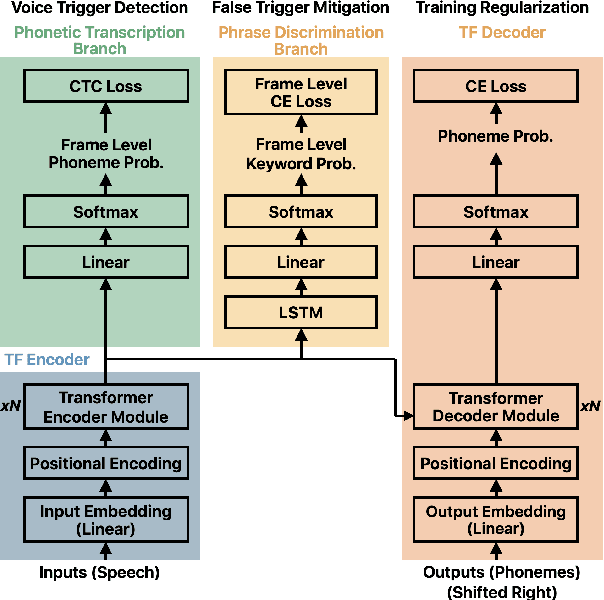
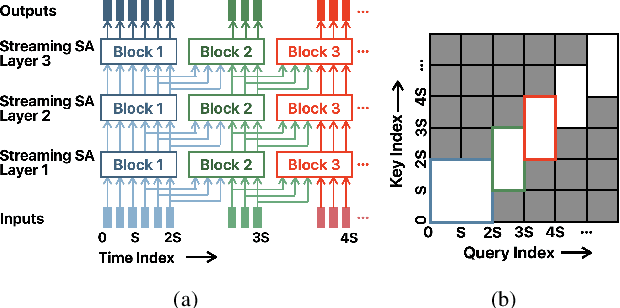

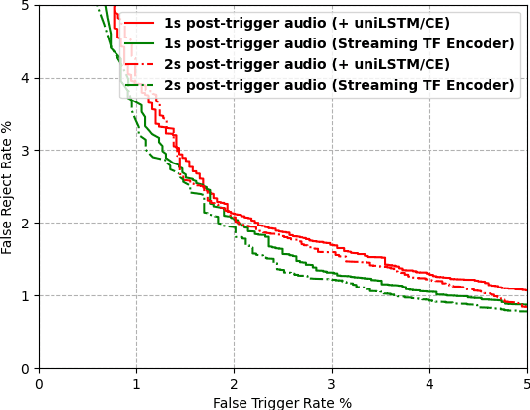
We present a unified and hardware efficient architecture for two stage voice trigger detection (VTD) and false trigger mitigation (FTM) tasks. Two stage VTD systems of voice assistants can get falsely activated to audio segments acoustically similar to the trigger phrase of interest. FTM systems cancel such activations by using post trigger audio context. Traditional FTM systems rely on automatic speech recognition lattices which are computationally expensive to obtain on device. We propose a streaming transformer (TF) encoder architecture, which progressively processes incoming audio chunks and maintains audio context to perform both VTD and FTM tasks using only acoustic features. The proposed joint model yields an average 18% relative reduction in false reject rate (FRR) for the VTD task at a given false alarm rate. Moreover, our model suppresses 95% of the false triggers with an additional one second of post-trigger audio. Finally, on-device measurements show 32% reduction in runtime memory and 56% reduction in inference time compared to non-streaming version of the model.
Hybrid Transformer/CTC Networks for Hardware Efficient Voice Triggering
Aug 05, 2020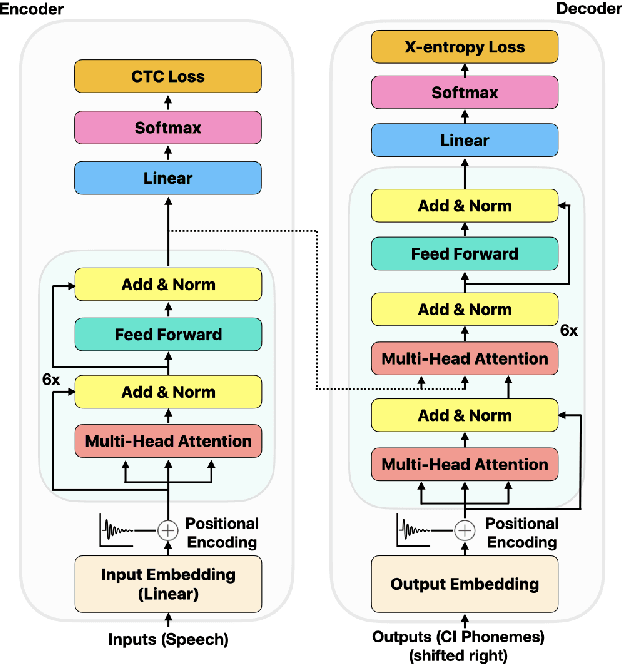
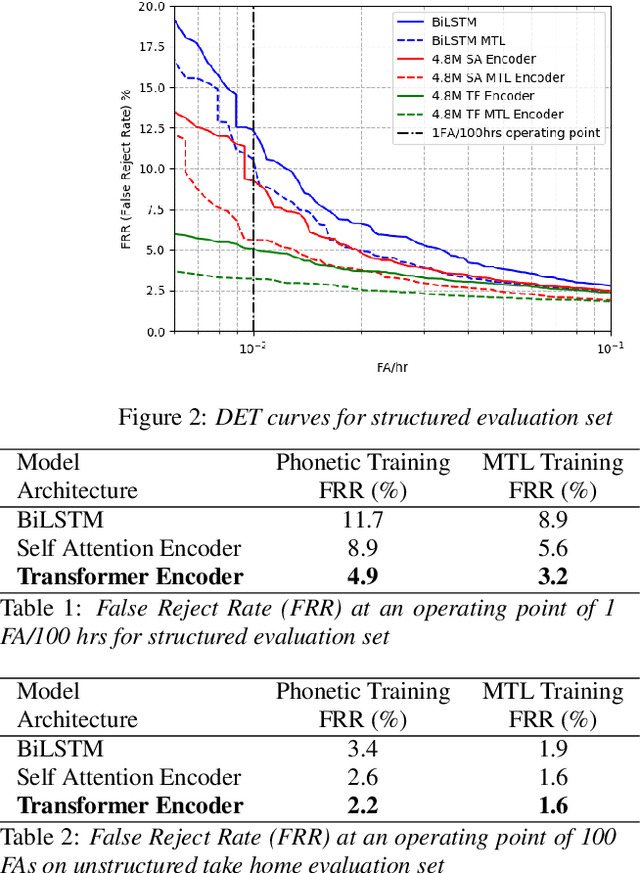
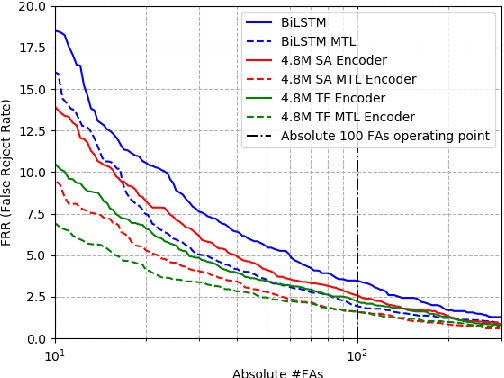
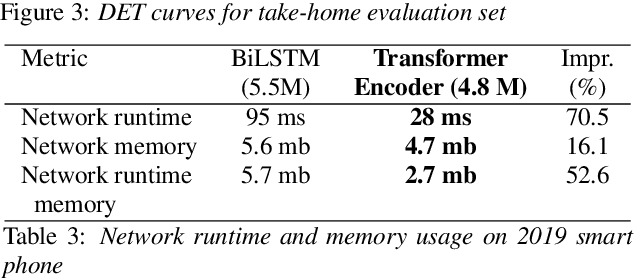
We consider the design of two-pass voice trigger detection systems. We focus on the networks in the second pass that are used to re-score candidate segments obtained from the first-pass. Our baseline is an acoustic model(AM), with BiLSTM layers, trained by minimizing the CTC loss. We replace the BiLSTM layers with self-attention layers. Results on internal evaluation sets show that self-attention networks yield better accuracy while requiring fewer parameters. We add an auto-regressive decoder network on top of the self-attention layers and jointly minimize the CTC loss on the encoder and the cross-entropy loss on the decoder. This design yields further improvements over the baseline. We retrain all the models above in a multi-task learning(MTL) setting, where one branch of a shared network is trained as an AM, while the second branch classifies the whole sequence to be true-trigger or not. Results demonstrate that networks with self-attention layers yield $\sim$60% relative reduction in false reject rates for a given false-alarm rate, while requiring 10% fewer parameters. When trained in the MTL setup, self-attention networks yield further accuracy improvements. On-device measurements show that we observe 70% relative reduction in inference time. Additionally, the proposed network architectures are $\sim$5X faster to train.