 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDevice-Directed Speech Detection: Regularization via Distillation for Weakly-Supervised Models
Mar 30, 2022


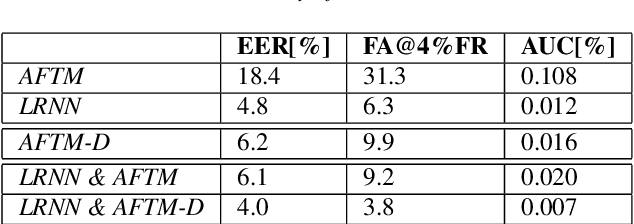
We address the problem of detecting speech directed to a device that does not contain a specific wake-word. Specifically, we focus on audio coming from a touch-based invocation. Mitigating virtual assistants (VAs) activation due to accidental button presses is critical for user experience. While the majority of approaches to false trigger mitigation (FTM) are designed to detect the presence of a target keyword, inferring user intent in absence of keyword is difficult. This also poses a challenge when creating the training/evaluation data for such systems due to inherent ambiguity in the user's data. To this end, we propose a novel FTM approach that uses weakly-labeled training data obtained with a newly introduced data sampling strategy. While this sampling strategy reduces data annotation efforts, the data labels are noisy as the data are not annotated manually. We use these data to train an acoustics-only model for the FTM task by regularizing its loss function via knowledge distillation from an ASR-based (LatticeRNN) model. This improves the model decisions, resulting in 66% gain in accuracy, as measured by equal-error-rate (EER), over the base acoustics-only model. We also show that the ensemble of the LatticeRNN and acoustic-distilled models brings further accuracy improvement of 20%.
Streaming on-device detection of device directed speech from voice and touch-based invocation
Oct 09, 2021
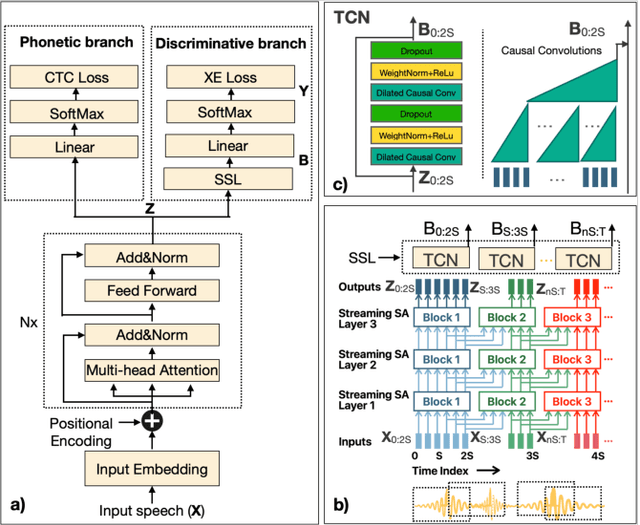
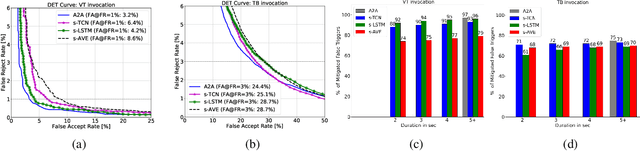
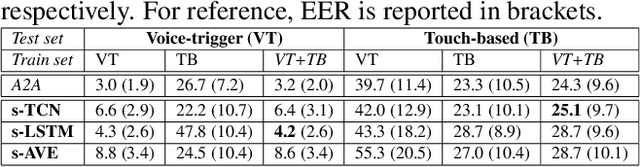
When interacting with smart devices such as mobile phones or wearables, the user typically invokes a virtual assistant (VA) by saying a keyword or by pressing a button on the device. However, in many cases, the VA can accidentally be invoked by the keyword-like speech or accidental button press, which may have implications on user experience and privacy. To this end, we propose an acoustic false-trigger-mitigation (FTM) approach for on-device device-directed speech detection that simultaneously handles the voice-trigger and touch-based invocation. To facilitate the model deployment on-device, we introduce a new streaming decision layer, derived using the notion of temporal convolutional networks (TCN) [1], known for their computational efficiency. To the best of our knowledge, this is the first approach that can detect device-directed speech from more than one invocation type in a streaming fashion. We compare this approach with streaming alternatives based on vanilla Average layer, and canonical LSTMs, and show: (i) that all the models show only a small degradation in accuracy compared with the invocation-specific models, and (ii) that the newly introduced streaming TCN consistently performs better or comparable with the alternatives, while mitigating device undirected speech faster in time, and with (relative) reduction in runtime peak-memory over the LSTM-based approach of 33% vs. 7%, when compared to a non-streaming counterpart.
Toward Personalized Affect-Aware Socially Assistive Robot Tutors in Long-Term Interventions for Children with Autism
Jan 30, 2021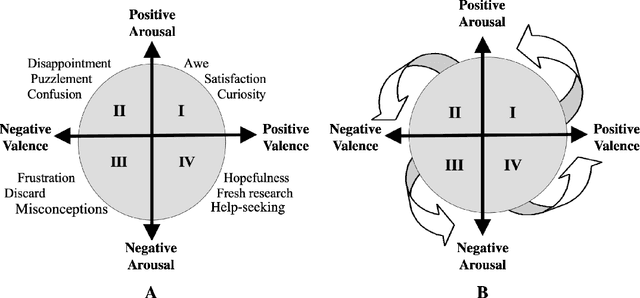
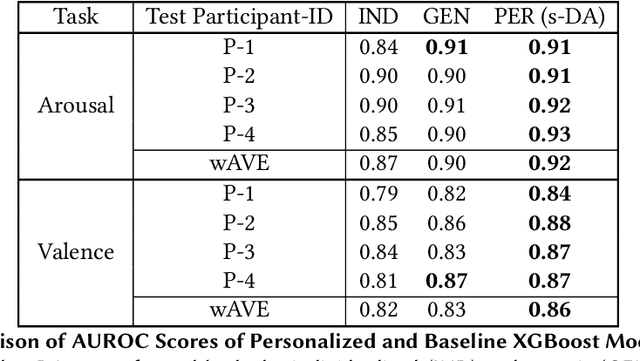

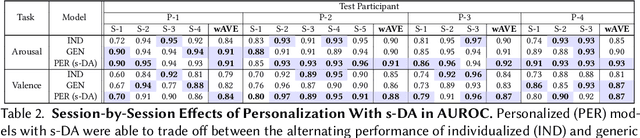
Affect-aware socially assistive robotics (SAR) has shown great potential for augmenting interventions for children with autism spectrum disorders (ASD). However, current SAR cannot yet perceive the unique and diverse set of atypical cognitive-affective behaviors from children with ASD in an automatic and personalized fashion in long-term (multi-session) real-world interactions. To bridge this gap, this work designed and validated personalized models of arousal and valence for children with ASD using a multi-session in-home dataset of SAR interventions. By training machine learning (ML) algorithms with supervised domain adaptation (s-DA), the personalized models were able to trade off between the limited individual data and the more abundant less personal data pooled from other study participants. We evaluated the effects of personalization on a long-term multimodal dataset consisting of 4 children with ASD with a total of 19 sessions, and derived inter-rater reliability (IR) scores for binary arousal (IR = 83%) and valence (IR = 81%) labels between human annotators. Our results show that personalized Gradient Boosted Decision Trees (XGBoost) models with s-DA outperformed two non-personalized individualized and generic model baselines not only on the weighted average of all sessions, but also statistically (p < .05) across individual sessions. This work paves the way for the development of personalized autonomous SAR systems tailored toward individuals with atypical cognitive-affective and socio-emotional needs.
Personalized Federated Deep Learning for Pain Estimation From Face Images
Jan 12, 2021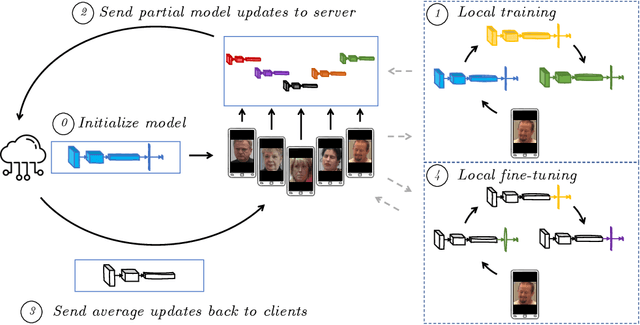
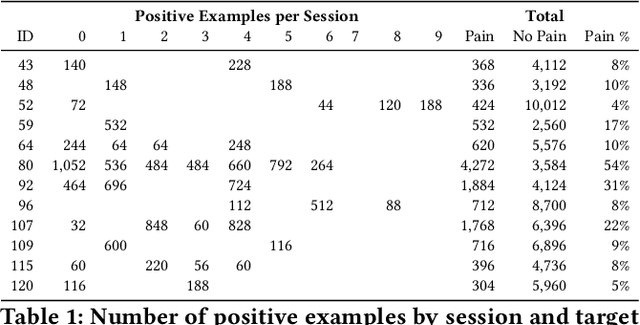

Standard machine learning approaches require centralizing the users' data in one computer or a shared database, which raises data privacy and confidentiality concerns. Therefore, limiting central access is important, especially in healthcare settings, where data regulations are strict. A potential approach to tackling this is Federated Learning (FL), which enables multiple parties to collaboratively learn a shared prediction model by using parameters of locally trained models while keeping raw training data locally. In the context of AI-assisted pain-monitoring, we wish to enable confidentiality-preserving and unobtrusive pain estimation for long-term pain-monitoring and reduce the burden on the nursing staff who perform frequent routine check-ups. To this end, we propose a novel Personalized Federated Deep Learning (PFDL) approach for pain estimation from face images. PFDL performs collaborative training of a deep model, implemented using a lightweight CNN architecture, across different clients (i.e., subjects) without sharing their face images. Instead of sharing all parameters of the model, as in standard FL, PFDL retains the last layer locally (used to personalize the pain estimates). This (i) adds another layer of data confidentiality, making it difficult for an adversary to infer pain levels of the target subject, while (ii) personalizing the pain estimation to each subject through local parameter tuning. We show using a publicly available dataset of face videos of pain (UNBC-McMaster Shoulder Pain Database), that PFDL performs comparably or better than the standard centralized and FL algorithms, while further enhancing data privacy. This, has the potential to improve traditional pain monitoring by making it more secure, computationally efficient, and scalable to a large number of individuals (e.g., for in-home pain monitoring), providing timely and unobtrusive pain measurement.
Multi-modal Active Learning From Human Data: A Deep Reinforcement Learning Approach
Jun 07, 2019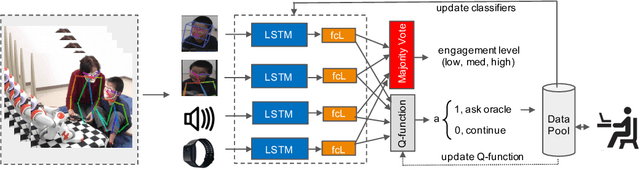


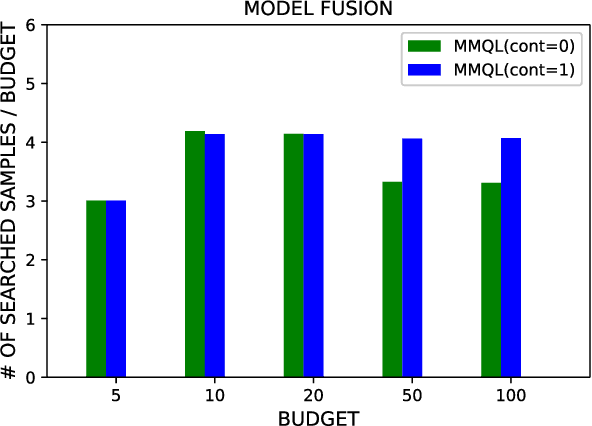
Human behavior expression and experience are inherently multi-modal, and characterized by vast individual and contextual heterogeneity. To achieve meaningful human-computer and human-robot interactions, multi-modal models of the users states (e.g., engagement) are therefore needed. Most of the existing works that try to build classifiers for the users states assume that the data to train the models are fully labeled. Nevertheless, data labeling is costly and tedious, and also prone to subjective interpretations by the human coders. This is even more pronounced when the data are multi-modal (e.g., some users are more expressive with their facial expressions, some with their voice). Thus, building models that can accurately estimate the users states during an interaction is challenging. To tackle this, we propose a novel multi-modal active learning (AL) approach that uses the notion of deep reinforcement learning (RL) to find an optimal policy for active selection of the users data, needed to train the target (modality-specific) models. We investigate different strategies for multi-modal data fusion, and show that the proposed model-level fusion coupled with RL outperforms the feature-level and modality-specific models, and the naive AL strategies such as random sampling, and the standard heuristics such as uncertainty sampling. We show the benefits of this approach on the task of engagement estimation from real-world child-robot interactions during an autism therapy. Importantly, we show that the proposed multi-modal AL approach can be used to efficiently personalize the engagement classifiers to the target user using a small amount of actively selected users data.
Meta-Weighted Gaussian Process Experts for Personalized Forecasting of AD Cognitive Changes
Apr 19, 2019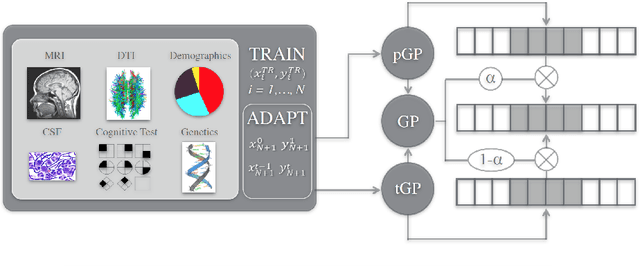
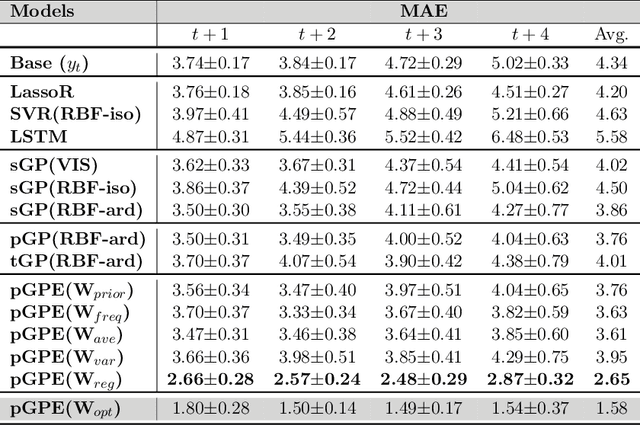
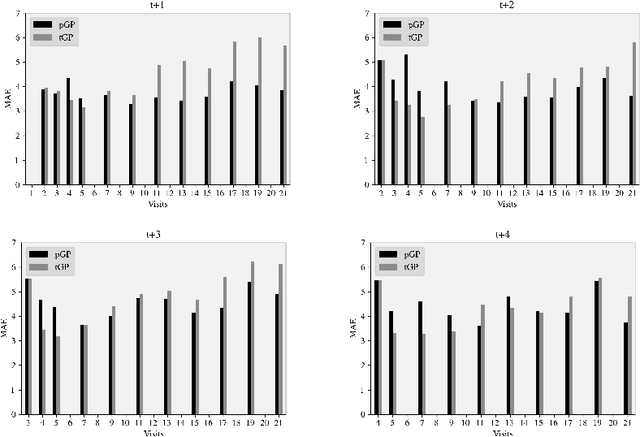
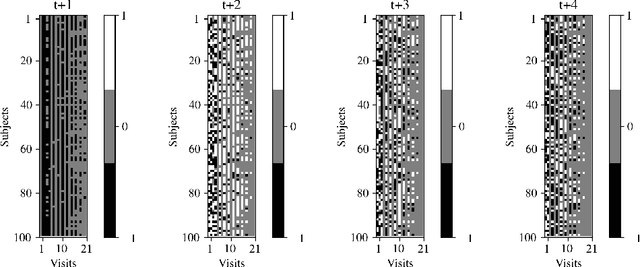
We introduce a novel personalized Gaussian Process Experts (pGPE) model for predicting per-subject ADAS-Cog13 cognitive scores -- a significant predictor of Alzheimer's Disease (AD) in the cognitive domain -- over the future 6, 12, 18, and 24 months. We start by training a population-level model using multi-modal data from previously seen subjects using a base Gaussian Process (GP) regression. Then, we personalize this model by adapting the base GP sequentially over time to a new (target) subject using domain adaptive GPs, and also by training subject-specific GP. While we show that these models achieve improved performance when selectively applied to the forecasting task (one performs better than the other on different subjects/visits), the average performance per model is suboptimal. To this end, we used the notion of meta learning in the proposed pGPE to design a regression-based weighting of these expert models, where the expert weights are optimized for each subject and his/her future visit. The results on a cohort of subjects from the ADNI dataset show that this newly introduced personalized weighting of the expert models leads to large improvements in accurately forecasting future ADAS-Cog13 scores and their fine-grained changes associated with the AD progression. This approach has potential to help identify at-risk patients early and improve the construction of clinical trials for AD.
Unsupervised Multi-Target Domain Adaptation: An Information Theoretic Approach
Oct 26, 2018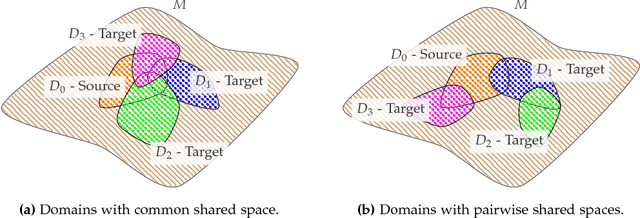
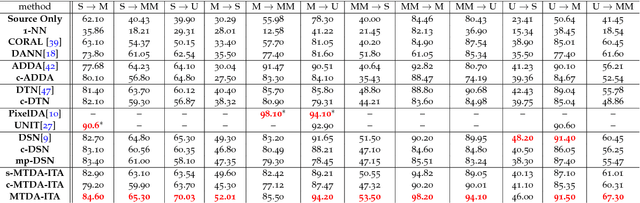
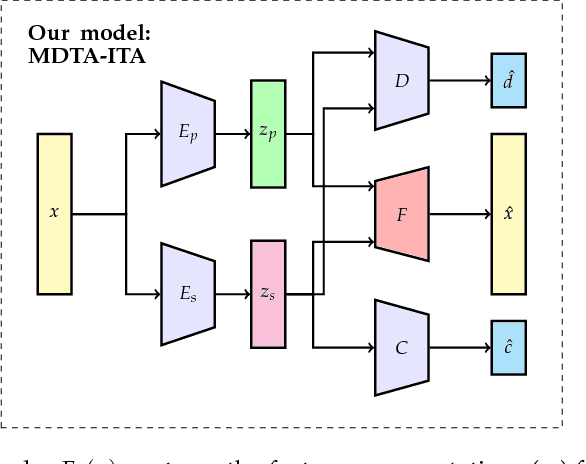

Unsupervised domain adaptation (uDA) models focus on pairwise adaptation settings where there is a single, labeled, source and a single target domain. However, in many real-world settings one seeks to adapt to multiple, but somewhat similar, target domains. Applying pairwise adaptation approaches to this setting may be suboptimal, as they fail to leverage shared information among multiple domains. In this work we propose an information theoretic approach for domain adaptation in the novel context of multiple target domains with unlabeled instances and one source domain with labeled instances. Our model aims to find a shared latent space common to all domains, while simultaneously accounting for the remaining private, domain-specific factors. Disentanglement of shared and private information is accomplished using a unified information-theoretic approach, which also serves to establish a stronger link between the latent representations and the observed data. The resulting model, accompanied by an efficient optimization algorithm, allows simultaneous adaptation from a single source to multiple target domains. We test our approach on three challenging publicly-available datasets, showing that it outperforms several popular domain adaptation methods.
Personalized Machine Learning for Robot Perception of Affect and Engagement in Autism Therapy
Jun 19, 2018Robots have great potential to facilitate future therapies for children on the autism spectrum. However, existing robots lack the ability to automatically perceive and respond to human affect, which is necessary for establishing and maintaining engaging interactions. Moreover, their inference challenge is made harder by the fact that many individuals with autism have atypical and unusually diverse styles of expressing their affective-cognitive states. To tackle the heterogeneity in behavioral cues of children with autism, we use the latest advances in deep learning to formulate a personalized machine learning (ML) framework for automatic perception of the childrens affective states and engagement during robot-assisted autism therapy. The key to our approach is a novel shift from the traditional ML paradigm - instead of using 'one-size-fits-all' ML models, our personalized ML framework is optimized for each child by leveraging relevant contextual information (demographics and behavioral assessment scores) and individual characteristics of each child. We designed and evaluated this framework using a dataset of multi-modal audio, video and autonomic physiology data of 35 children with autism (age 3-13) and from 2 cultures (Asia and Europe), participating in a 25-minute child-robot interaction (~500k datapoints). Our experiments confirm the feasibility of the robot perception of affect and engagement, showing clear improvements due to the model personalization. The proposed approach has potential to improve existing therapies for autism by offering more efficient monitoring and summarization of the therapy progress.
Personalized Gaussian Processes for Forecasting of Alzheimer's Disease Assessment Scale-Cognition Sub-Scale (ADAS-Cog13)
May 04, 2018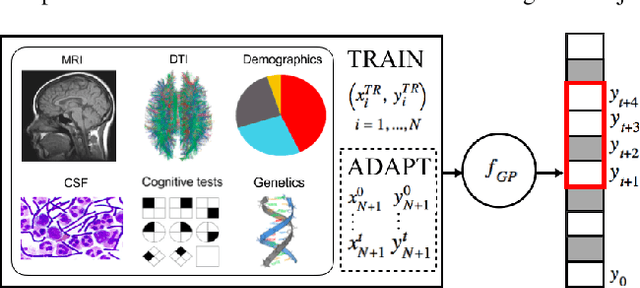
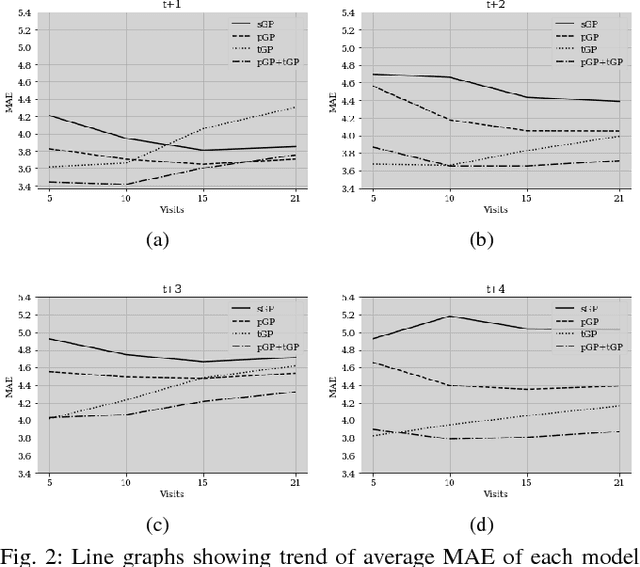

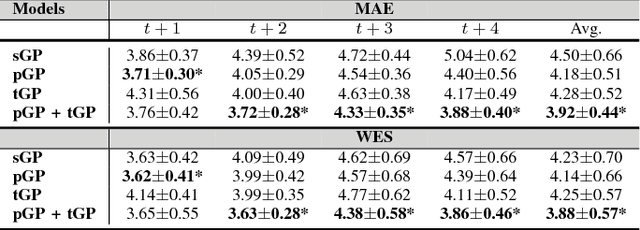
In this paper, we introduce the use of a personalized Gaussian Process model (pGP) to predict per-patient changes in ADAS-Cog13 -- a significant predictor of Alzheimer's Disease (AD) in the cognitive domain -- using data from each patient's previous visits, and testing on future (held-out) data. We start by learning a population-level model using multi-modal data from previously seen patients using a base Gaussian Process (GP) regression. The personalized GP (pGP) is formed by adapting the base GP sequentially over time to a new (target) patient using domain adaptive GPs. We extend this personalized approach to predict the values of ADAS-Cog13 over the future 6, 12, 18, and 24 months. We compare this approach to a GP model trained only on past data of the target patients (tGP), as well as to a new approach that combines pGP with tGP. We find that the new approach, combining pGP with tGP, leads to large improvements in accurately forecasting future ADAS-Cog13 scores.
Personalized Gaussian Processes for Future Prediction of Alzheimer's Disease Progression
May 04, 2018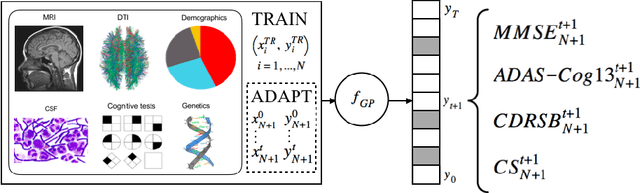
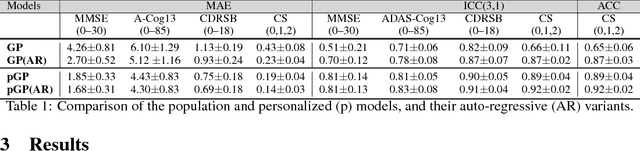

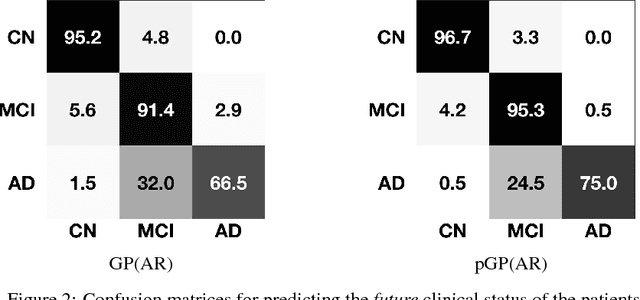
In this paper, we introduce the use of a personalized Gaussian Process model (pGP) to predict the key metrics of Alzheimer's Disease progression (MMSE, ADAS-Cog13, CDRSB and CS) based on each patient's previous visits. We start by learning a population-level model using multi-modal data from previously seen patients using the base Gaussian Process (GP) regression. Then, this model is adapted sequentially over time to a new patient using domain adaptive GPs to form the patient's pGP. We show that this new approach, together with an auto-regressive formulation, leads to significant improvements in forecasting future clinical status and cognitive scores for target patients when compared to modeling the population with traditional GPs.