 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Can Large Language Models Enable Better Socially Assistive Human-Robot Interaction: A Brief Survey
Apr 05, 2024Socially assistive robots (SARs) have shown great success in providing personalized cognitive-affective support for user populations with special needs such as older adults, children with autism spectrum disorder (ASD), and individuals with mental health challenges. The large body of work on SAR demonstrates its potential to provide at-home support that complements clinic-based interventions delivered by mental health professionals, making these interventions more effective and accessible. However, there are still several major technical challenges that hinder SAR-mediated interactions and interventions from reaching human-level social intelligence and efficacy. With the recent advances in large language models (LLMs), there is an increased potential for novel applications within the field of SAR that can significantly expand the current capabilities of SARs. However, incorporating LLMs introduces new risks and ethical concerns that have not yet been encountered, and must be carefully be addressed to safely deploy these more advanced systems. In this work, we aim to conduct a brief survey on the use of LLMs in SAR technologies, and discuss the potentials and risks of applying LLMs to the following three major technical challenges of SAR: 1) natural language dialog; 2) multimodal understanding; 3) LLMs as robot policies.
Designing a Socially Assistive Robot to Support Older Adults with Low Vision
Jan 06, 2024Socially assistive robots (SARs) have shown great promise in supplementing and augmenting interventions to support the physical and mental well-being of older adults. However, past work has not yet explored the potential of applying SAR to lower the barriers of long-term low vision rehabilitation (LVR) interventions for older adults. In this work, we present a user-informed design process to validate the motivation and identify major design principles for developing SAR for long-term LVR. To evaluate user-perceived usefulness and acceptance of SAR in this novel domain, we performed a two-phase study through user surveys. First, a group (n=38) of older adults with LV completed a mailed-in survey. Next, a new group (n=13) of older adults with LV saw an in-clinic SAR demo and then completed the survey. The study participants reported that SARs would be useful, trustworthy, easy to use, and enjoyable while providing socio-emotional support to augment LVR interventions. The in-clinic demo group reported significantly more positive opinions of the SAR's capabilities than did the baseline survey group that used mailed-in forms without the SAR demo.
Expanding the Role of Affective Phenomena in Multimodal Interaction Research
May 18, 2023



In recent decades, the field of affective computing has made substantial progress in advancing the ability of AI systems to recognize and express affective phenomena, such as affect and emotions, during human-human and human-machine interactions. This paper describes our examination of research at the intersection of multimodal interaction and affective computing, with the objective of observing trends and identifying understudied areas. We examined over 16,000 papers from selected conferences in multimodal interaction, affective computing, and natural language processing: ACM International Conference on Multimodal Interaction, AAAC International Conference on Affective Computing and Intelligent Interaction, Annual Meeting of the Association for Computational Linguistics, and Conference on Empirical Methods in Natural Language Processing. We identified 910 affect-related papers and present our analysis of the role of affective phenomena in these papers. We find that this body of research has primarily focused on enabling machines to recognize and express affect and emotion. However, we find limited research on how affect and emotion predictions might be used by AI systems to enhance machine understanding of human social behaviors and cognitive states. Based on our analysis, we discuss directions to expand the role of affective phenomena in multimodal interaction research.
Towards Intercultural Affect Recognition: Audio-Visual Affect Recognition in the Wild Across Six Cultures
Jul 31, 2022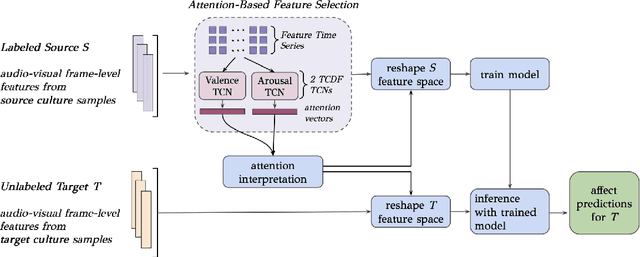

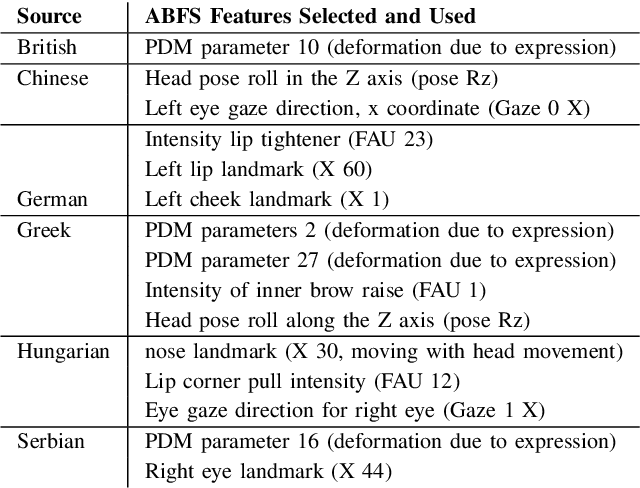
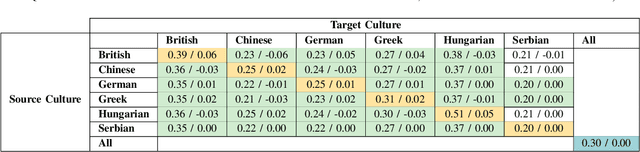
In our multicultural world, affect-aware AI systems that support humans need the ability to perceive affect across variations in emotion expression patterns across cultures. These models must perform well in cultural contexts on which they have not been trained. A standard assumption in affective computing is that affect recognition models trained and used within the same culture (intracultural) will perform better than models trained on one culture and used on different cultures (intercultural). We test this assumption and present the first systematic study of intercultural affect recognition models using videos of real-world dyadic interactions from six cultures. We develop an attention-based feature selection approach under temporal causal discovery to identify behavioral cues that can be leveraged in intercultural affect recognition models. Across all six cultures, our findings demonstrate that intercultural affect recognition models were as effective or more effective than intracultural models. We identify and contribute useful behavioral features for intercultural affect recognition; facial features from the visual modality were more useful than the audio modality in this study's context. Our paper presents a proof-of-concept and motivation for the future development of intercultural affect recognition systems.
Affect-Aware Deep Belief Network Representations for Multimodal Unsupervised Deception Detection
Aug 17, 2021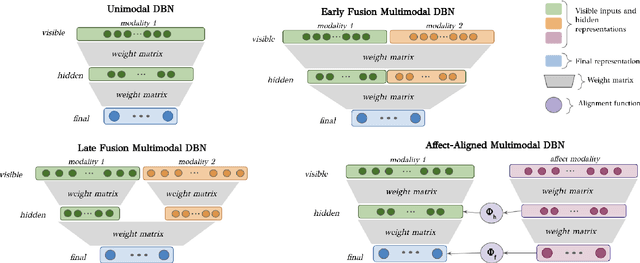
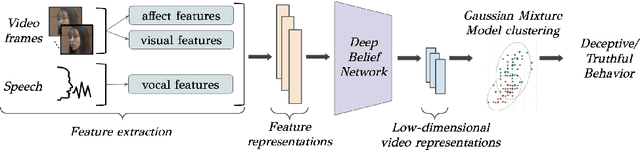
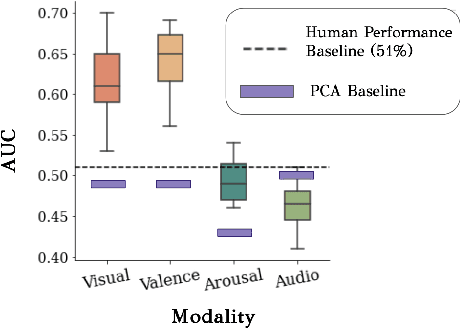
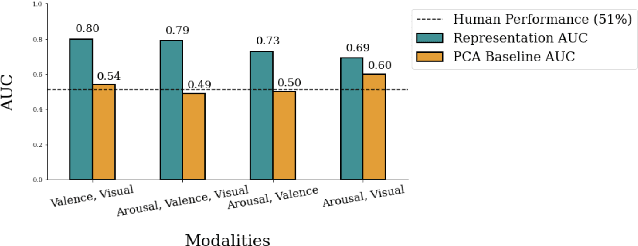
Automated systems that detect the social behavior of deception can enhance human well-being across medical, social work, and legal domains. Labeled datasets to train supervised deception detection models can rarely be collected for real-world, high-stakes contexts. To address this challenge, we propose the first unsupervised approach for detecting real-world, high-stakes deception in videos without requiring labels. This paper presents our novel approach for affect-aware unsupervised Deep Belief Networks (DBN) to learn discriminative representations of deceptive and truthful behavior. Drawing on psychology theories that link affect and deception, we experimented with unimodal and multimodal DBN-based approaches trained on facial valence, facial arousal, audio, and visual features. In addition to using facial affect as a feature on which DBN models are trained, we also introduce a DBN training procedure that uses facial affect as an aligner of audio-visual representations. We conducted classification experiments with unsupervised Gaussian Mixture Model clustering to evaluate our approaches. Our best unsupervised approach (trained on facial valence and visual features) achieved an AUC of 80%, outperforming human ability and performing comparably to fully-supervised models. Our results motivate future work on unsupervised, affect-aware computational approaches for detecting deception and other social behaviors in the wild.
Modeling User Empathy Elicited by a Robot Storyteller
Jul 29, 2021
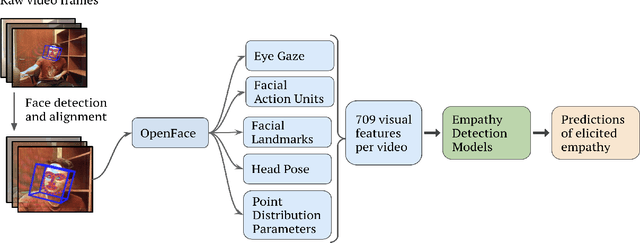
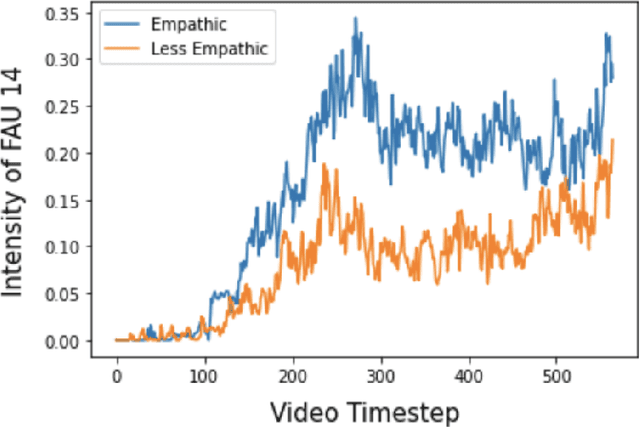
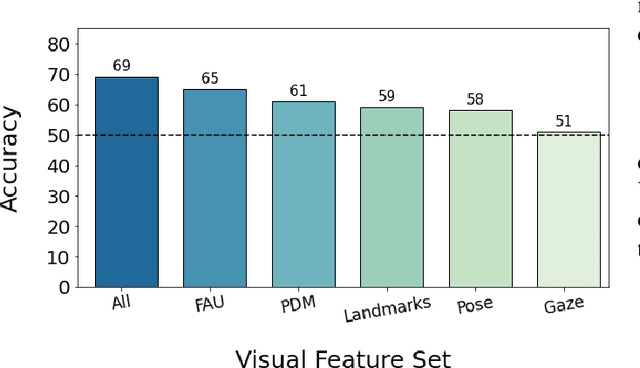
Virtual and robotic agents capable of perceiving human empathy have the potential to participate in engaging and meaningful human-machine interactions that support human well-being. Prior research in computational empathy has focused on designing empathic agents that use verbal and nonverbal behaviors to simulate empathy and attempt to elicit empathic responses from humans. The challenge of developing agents with the ability to automatically perceive elicited empathy in humans remains largely unexplored. Our paper presents the first approach to modeling user empathy elicited during interactions with a robotic agent. We collected a new dataset from the novel interaction context of participants listening to a robot storyteller (46 participants, 6.9 hours of video). After each storytelling interaction, participants answered a questionnaire that assessed their level of elicited empathy during the interaction with the robot. We conducted experiments with 8 classical machine learning models and 2 deep learning models (long short-term memory networks and temporal convolutional networks) to detect empathy by leveraging patterns in participants' visual behaviors while they were listening to the robot storyteller. Our highest-performing approach, based on XGBoost, achieved an accuracy of 69% and AUC of 72% when detecting empathy in videos. We contribute insights regarding modeling approaches and visual features for automated empathy detection. Our research informs and motivates future development of empathy perception models that can be leveraged by virtual and robotic agents during human-machine interactions.
Personalized Affect-Aware Socially Assistive Robot Tutors Aimed at Fostering Social Grit in Children with Autism
Mar 29, 2021
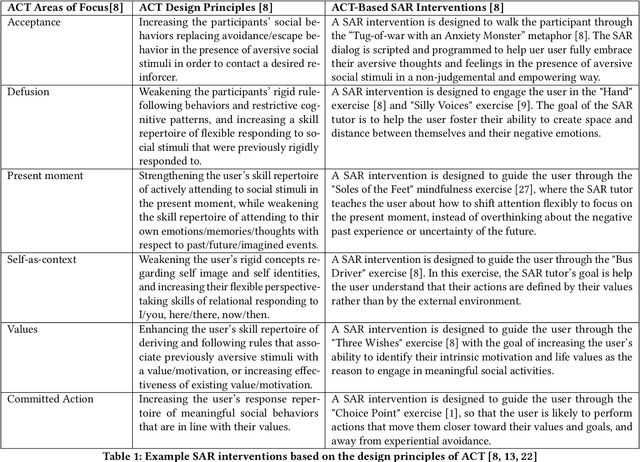
Affect-aware socially assistive robotics (SAR) tutors have great potential to augment and democratize professional therapeutic interventions for children with autism spectrum disorders (ASD) from different socioeconomic backgrounds. However, the majority of research on SAR for ASD has been on teaching cognitive and/or social skills, not on addressing users' emotional needs for real-world social situations. To bridge that gap, this work aims to develop personalized affect-aware SAR tutors to help alleviate social anxiety and foster social grit-the growth mindset for social skill development-in children with ASD. We propose a novel paradigm to incorporate clinically validated Acceptance and Commitment Training (ACT) with personalized SAR interventions. This work paves the way toward developing personalized affect-aware SAR interventions to support the unique and diverse socio-emotional needs and challenges of children with ASD.
Toward Automated Generation of Affective Gestures from Text:A Theory-Driven Approach
Mar 04, 2021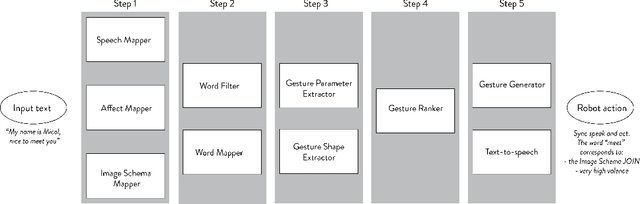
Communication in both human-human and human-robot interac-tion (HRI) contexts consists of verbal (speech-based) and non-verbal(facial expressions, eye gaze, gesture, body pose, etc.) components.The verbal component contains semantic and affective information;accordingly, HRI work on the gesture component so far has focusedon rule-based (mapping words to gestures) and data-driven (deep-learning) approaches to generating speech-paired gestures basedon either semantics or the affective state. Consequently, most ges-ture systems are confined to producing either semantically-linkedor affect-based gesticures. This paper introduces an approach forenabling human-robot communication based on a theory-drivenapproach to generate speech-paired robot gestures using both se-mantic and affective information. Our model takes as input textand sentiment analysis, and generates robot gestures in terms oftheir shape, intensity, and speed.
Unsupervised Audio-Visual Subspace Alignment for High-Stakes Deception Detection
Feb 06, 2021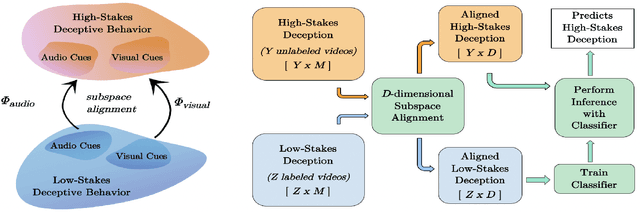
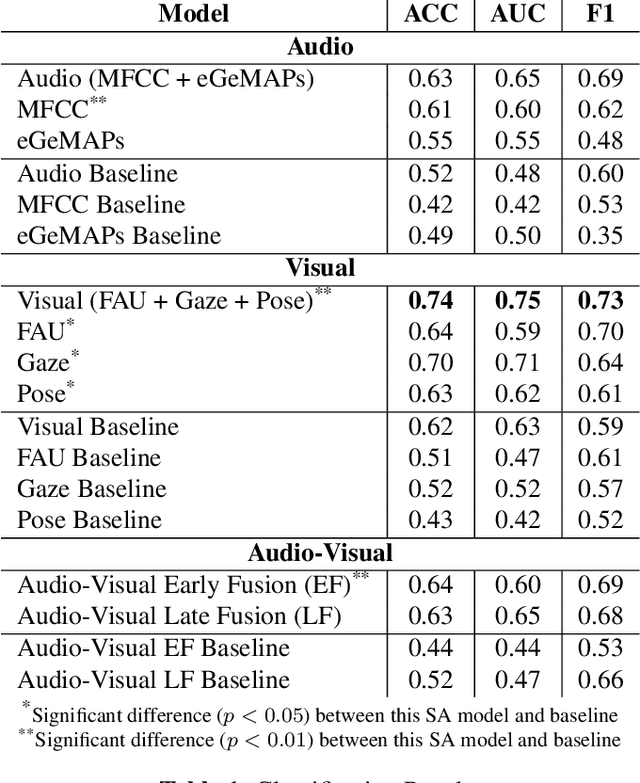
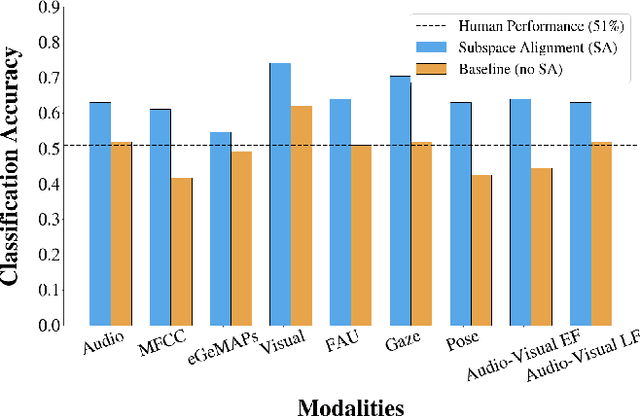
Automated systems that detect deception in high-stakes situations can enhance societal well-being across medical, social work, and legal domains. Existing models for detecting high-stakes deception in videos have been supervised, but labeled datasets to train models can rarely be collected for most real-world applications. To address this problem, we propose the first multimodal unsupervised transfer learning approach that detects real-world, high-stakes deception in videos without using high-stakes labels. Our subspace-alignment (SA) approach adapts audio-visual representations of deception in lab-controlled low-stakes scenarios to detect deception in real-world, high-stakes situations. Our best unsupervised SA models outperform models without SA, outperform human ability, and perform comparably to a number of existing supervised models. Our research demonstrates the potential for introducing subspace-based transfer learning to model high-stakes deception and other social behaviors in real-world contexts with a scarcity of labeled behavioral data.
Toward Personalized Affect-Aware Socially Assistive Robot Tutors in Long-Term Interventions for Children with Autism
Jan 30, 2021
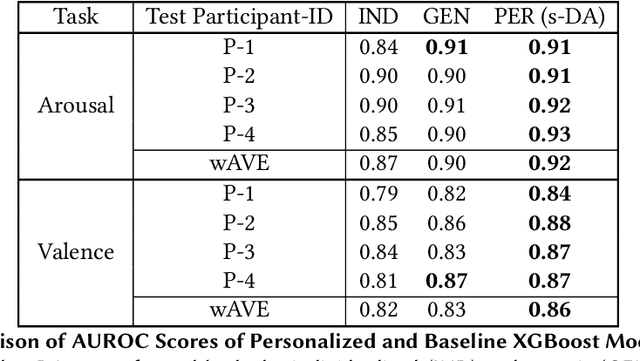

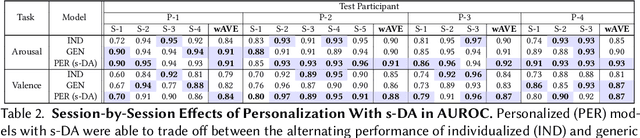
Affect-aware socially assistive robotics (SAR) has shown great potential for augmenting interventions for children with autism spectrum disorders (ASD). However, current SAR cannot yet perceive the unique and diverse set of atypical cognitive-affective behaviors from children with ASD in an automatic and personalized fashion in long-term (multi-session) real-world interactions. To bridge this gap, this work designed and validated personalized models of arousal and valence for children with ASD using a multi-session in-home dataset of SAR interventions. By training machine learning (ML) algorithms with supervised domain adaptation (s-DA), the personalized models were able to trade off between the limited individual data and the more abundant less personal data pooled from other study participants. We evaluated the effects of personalization on a long-term multimodal dataset consisting of 4 children with ASD with a total of 19 sessions, and derived inter-rater reliability (IR) scores for binary arousal (IR = 83%) and valence (IR = 81%) labels between human annotators. Our results show that personalized Gradient Boosted Decision Trees (XGBoost) models with s-DA outperformed two non-personalized individualized and generic model baselines not only on the weighted average of all sessions, but also statistically (p < .05) across individual sessions. This work paves the way for the development of personalized autonomous SAR systems tailored toward individuals with atypical cognitive-affective and socio-emotional needs.