 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Automated Generation of Affective Gestures from Text:A Theory-Driven Approach
Paper and Code
Mar 04, 2021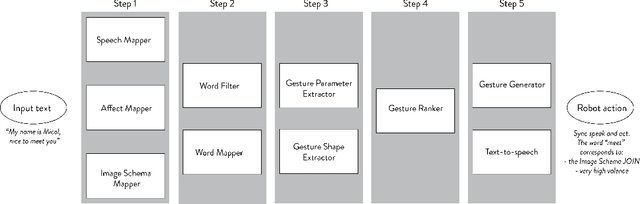
Communication in both human-human and human-robot interac-tion (HRI) contexts consists of verbal (speech-based) and non-verbal(facial expressions, eye gaze, gesture, body pose, etc.) components.The verbal component contains semantic and affective information;accordingly, HRI work on the gesture component so far has focusedon rule-based (mapping words to gestures) and data-driven (deep-learning) approaches to generating speech-paired gestures basedon either semantics or the affective state. Consequently, most ges-ture systems are confined to producing either semantically-linkedor affect-based gesticures. This paper introduces an approach forenabling human-robot communication based on a theory-drivenapproach to generate speech-paired robot gestures using both se-mantic and affective information. Our model takes as input textand sentiment analysis, and generates robot gestures in terms oftheir shape, intensity, and speed.