 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERR@HRI 2.0 Challenge: Multimodal Detection of Errors and Failures in Human-Robot Conversations
Jul 17, 2025The integration of large language models (LLMs) into conversational robots has made human-robot conversations more dynamic. Yet, LLM-powered conversational robots remain prone to errors, e.g., misunderstanding user intent, prematurely interrupting users, or failing to respond altogether. Detecting and addressing these failures is critical for preventing conversational breakdowns, avoiding task disruptions, and sustaining user trust. To tackle this problem, the ERR@HRI 2.0 Challenge provides a multimodal dataset of LLM-powered conversational robot failures during human-robot conversations and encourages researchers to benchmark machine learning models designed to detect robot failures. The dataset includes 16 hours of dyadic human-robot interactions, incorporating facial, speech, and head movement features. Each interaction is annotated with the presence or absence of robot errors from the system perspective, and perceived user intention to correct for a mismatch between robot behavior and user expectation. Participants are invited to form teams and develop machine learning models that detect these failures using multimodal data. Submissions will be evaluated using various performance metrics, including detection accuracy and false positive rate. This challenge represents another key step toward improving failure detection in human-robot interaction through social signal analysis.
Critical Insights about Robots for Mental Wellbeing
Jun 16, 2025Social robots are increasingly being explored as tools to support emotional wellbeing, particularly in non-clinical settings. Drawing on a range of empirical studies and practical deployments, this paper outlines six key insights that highlight both the opportunities and challenges in using robots to promote mental wellbeing. These include (1) the lack of a single, objective measure of wellbeing, (2) the fact that robots don't need to act as companions to be effective, (3) the growing potential of virtual interactions, (4) the importance of involving clinicians in the design process, (5) the difference between one-off and long-term interactions, and (6) the idea that adaptation and personalization are not always necessary for positive outcomes. Rather than positioning robots as replacements for human therapists, we argue that they are best understood as supportive tools that must be designed with care, grounded in evidence, and shaped by ethical and psychological considerations. Our aim is to inform future research and guide responsible, effective use of robots in mental health and wellbeing contexts.
REACT 2025: the Third Multiple Appropriate Facial Reaction Generation Challenge
May 22, 2025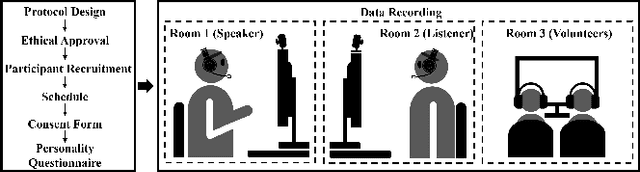

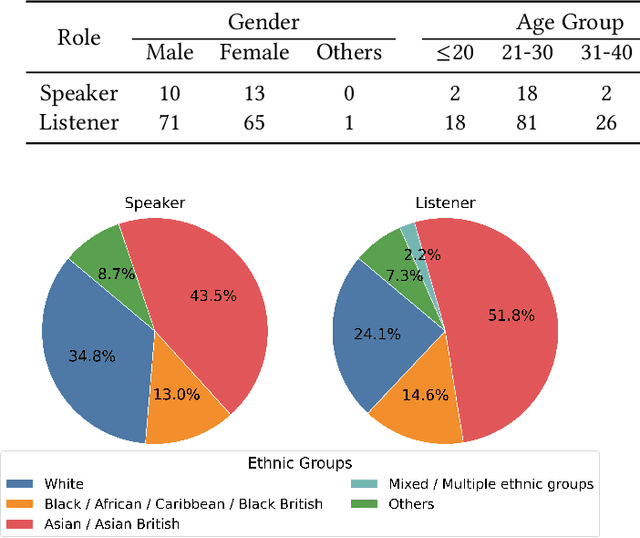
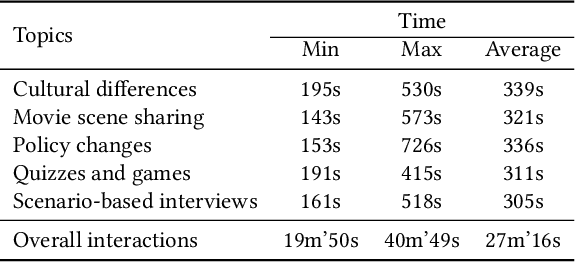
In dyadic interactions, a broad spectrum of human facial reactions might be appropriate for responding to each human speaker behaviour. Following the successful organisation of the REACT 2023 and REACT 2024 challenges, we are proposing the REACT 2025 challenge encouraging the development and benchmarking of Machine Learning (ML) models that can be used to generate multiple appropriate, diverse, realistic and synchronised human-style facial reactions expressed by human listeners in response to an input stimulus (i.e., audio-visual behaviours expressed by their corresponding speakers). As a key of the challenge, we provide challenge participants with the first natural and large-scale multi-modal MAFRG dataset (called MARS) recording 137 human-human dyadic interactions containing a total of 2856 interaction sessions covering five different topics. In addition, this paper also presents the challenge guidelines and the performance of our baselines on the two proposed sub-challenges: Offline MAFRG and Online MAFRG, respectively. The challenge baseline code is publicly available at https://github.com/reactmultimodalchallenge/baseline_react2025
Concerns and Values in Human-Robot Interactions: A Focus on Social Robotics
Jan 10, 2025Robots, as AI with physical instantiation, inhabit our social and physical world, where their actions have both social and physical consequences, posing challenges for researchers when designing social robots. This study starts with a scoping review to identify discussions and potential concerns arising from interactions with robotic systems. Two focus groups of technology ethics experts then validated a comprehensive list of key topics and values in human-robot interaction (HRI) literature. These insights were integrated into the HRI Value Compass web tool, to help HRI researchers identify ethical values in robot design. The tool was evaluated in a pilot study. This work benefits the HRI community by highlighting key concerns in human-robot interactions and providing an instrument to help researchers design robots that align with human values, ensuring future robotic systems adhere to these values in social applications.
"Can you be my mum?": Manipulating Social Robots in the Large Language Models Era
Jan 08, 2025Recent advancements in robots powered by large language models have enhanced their conversational abilities, enabling interactions closely resembling human dialogue. However, these models introduce safety and security concerns in HRI, as they are vulnerable to manipulation that can bypass built-in safety measures. Imagining a social robot deployed in a home, this work aims to understand how everyday users try to exploit a language model to violate ethical principles, such as by prompting the robot to act like a life partner. We conducted a pilot study involving 21 university students who interacted with a Misty robot, attempting to circumvent its safety mechanisms across three scenarios based on specific HRI ethical principles: attachment, freedom, and empathy. Our results reveal that participants employed five techniques, including insulting and appealing to pity using emotional language. We hope this work can inform future research in designing strong safeguards to ensure ethical and secure human-robot interactions.
Social Group Human-Robot Interaction: A Scoping Review of Computational Challenges
Dec 20, 2024Group interactions are a natural part of our daily life, and as robots become more integrated into society, they must be able to socially interact with multiple people at the same time. However, group human-robot interaction (HRI) poses unique computational challenges often overlooked in the current HRI literature. We conducted a scoping review including 44 group HRI papers from the last decade (2015-2024). From these papers, we extracted variables related to perception and behaviour generation challenges, as well as factors related to the environment, group, and robot capabilities that influence these challenges. Our findings show that key computational challenges in perception included detection of groups, engagement, and conversation information, while challenges in behaviour generation involved developing approaching and conversational behaviours. We also identified research gaps, such as improving detection of subgroups and interpersonal relationships, and recommended future work in group HRI to help researchers address these computational challenges
Multimodal Gender Fairness in Depression Prediction: Insights on Data from the USA & China
Aug 07, 2024Social agents and robots are increasingly being used in wellbeing settings. However, a key challenge is that these agents and robots typically rely on machine learning (ML) algorithms to detect and analyse an individual's mental wellbeing. The problem of bias and fairness in ML algorithms is becoming an increasingly greater source of concern. In concurrence, existing literature has also indicated that mental health conditions can manifest differently across genders and cultures. We hypothesise that the representation of features (acoustic, textual, and visual) and their inter-modal relations would vary among subjects from different cultures and genders, thus impacting the performance and fairness of various ML models. We present the very first evaluation of multimodal gender fairness in depression manifestation by undertaking a study on two different datasets from the USA and China. We undertake thorough statistical and ML experimentation and repeat the experiments for several different algorithms to ensure that the results are not algorithm-dependent. Our findings indicate that though there are differences between both datasets, it is not conclusive whether this is due to the difference in depression manifestation as hypothesised or other external factors such as differences in data collection methodology. Our findings further motivate a call for a more consistent and culturally aware data collection process in order to address the problem of ML bias in depression detection and to promote the development of fairer agents and robots for wellbeing.
ERR@HRI 2024 Challenge: Multimodal Detection of Errors and Failures in Human-Robot Interactions
Jul 08, 2024Despite the recent advancements in robotics and machine learning (ML), the deployment of autonomous robots in our everyday lives is still an open challenge. This is due to multiple reasons among which are their frequent mistakes, such as interrupting people or having delayed responses, as well as their limited ability to understand human speech, i.e., failure in tasks like transcribing speech to text. These mistakes may disrupt interactions and negatively influence human perception of these robots. To address this problem, robots need to have the ability to detect human-robot interaction (HRI) failures. The ERR@HRI 2024 challenge tackles this by offering a benchmark multimodal dataset of robot failures during human-robot interactions (HRI), encouraging researchers to develop and benchmark multimodal machine learning models to detect these failures. We created a dataset featuring multimodal non-verbal interaction data, including facial, speech, and pose features from video clips of interactions with a robotic coach, annotated with labels indicating the presence or absence of robot mistakes, user awkwardness, and interaction ruptures, allowing for the training and evaluation of predictive models. Challenge participants have been invited to submit their multimodal ML models for detection of robot errors and to be evaluated against various performance metrics such as accuracy, precision, recall, F1 score, with and without a margin of error reflecting the time-sensitivity of these metrics. The results of this challenge will help the research field in better understanding the robot failures in human-robot interactions and designing autonomous robots that can mitigate their own errors after successfully detecting them.
Past, Present, and Future: A Survey of The Evolution of Affective Robotics For Well-being
Jul 03, 2024Recent research in affective robots has recognized their potential in supporting human well-being. Due to rapidly developing affective and artificial intelligence technologies, this field of research has undergone explosive expansion and advancement in recent years. In order to develop a deeper understanding of recent advancements, we present a systematic review of the past 10 years of research in affective robotics for wellbeing. In this review, we identify the domains of well-being that have been studied, the methods used to investigate affective robots for well-being, and how these have evolved over time. We also examine the evolution of the multifaceted research topic from three lenses: technical, design, and ethical. Finally, we discuss future opportunities for research based on the gaps we have identified in our review -- proposing pathways to take affective robotics from the past and present to the future. The results of our review are of interest to human-robot interaction and affective computing researchers, as well as clinicians and well-being professionals who may wish to examine and incorporate affective robotics in their practices.
Underneath the Numbers: Quantitative and Qualitative Gender Fairness in LLMs for Depression Prediction
Jun 12, 2024Recent studies show bias in many machine learning models for depression detection, but bias in LLMs for this task remains unexplored. This work presents the first attempt to investigate the degree of gender bias present in existing LLMs (ChatGPT, LLaMA 2, and Bard) using both quantitative and qualitative approaches. From our quantitative evaluation, we found that ChatGPT performs the best across various performance metrics and LLaMA 2 outperforms other LLMs in terms of group fairness metrics. As qualitative fairness evaluation remains an open research question we propose several strategies (e.g., word count, thematic analysis) to investigate whether and how a qualitative evaluation can provide valuable insights for bias analysis beyond what is possible with quantitative evaluation. We found that ChatGPT consistently provides a more comprehensive, well-reasoned explanation for its prediction compared to LLaMA 2. We have also identified several themes adopted by LLMs to qualitatively evaluate gender fairness. We hope our results can be used as a stepping stone towards future attempts at improving qualitative evaluation of fairness for LLMs especially for high-stakes tasks such as depression detection.