 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSignal or 'Noise': Human Reactions to Robot Errors in the Wild
Feb 04, 2026In the real world, robots frequently make errors, yet little is known about people's social responses to errors outside of lab settings. Prior work has shown that social signals are reliable and useful for error management in constrained interactions, but it is unclear if this holds in the real world - especially with a non-social robot in repeated and group interactions with successive or propagated errors. To explore this, we built a coffee robot and conducted a public field deployment ($N = 49$). We found that participants consistently expressed varied social signals in response to errors and other stimuli, particularly during group interactions. Our findings suggest that social signals in the wild are rich (with participants volunteering information about the interaction), but "noisy." We discuss lessons, benefits, and challenges for using social signals in real-world HRI.
ERR@HRI 2.0 Challenge: Multimodal Detection of Errors and Failures in Human-Robot Conversations
Jul 17, 2025The integration of large language models (LLMs) into conversational robots has made human-robot conversations more dynamic. Yet, LLM-powered conversational robots remain prone to errors, e.g., misunderstanding user intent, prematurely interrupting users, or failing to respond altogether. Detecting and addressing these failures is critical for preventing conversational breakdowns, avoiding task disruptions, and sustaining user trust. To tackle this problem, the ERR@HRI 2.0 Challenge provides a multimodal dataset of LLM-powered conversational robot failures during human-robot conversations and encourages researchers to benchmark machine learning models designed to detect robot failures. The dataset includes 16 hours of dyadic human-robot interactions, incorporating facial, speech, and head movement features. Each interaction is annotated with the presence or absence of robot errors from the system perspective, and perceived user intention to correct for a mismatch between robot behavior and user expectation. Participants are invited to form teams and develop machine learning models that detect these failures using multimodal data. Submissions will be evaluated using various performance metrics, including detection accuracy and false positive rate. This challenge represents another key step toward improving failure detection in human-robot interaction through social signal analysis.
Robot Error Awareness Through Human Reactions: Implementation, Evaluation, and Recommendations
Jan 13, 2025



Effective error detection is crucial to prevent task disruption and maintain user trust. Traditional methods often rely on task-specific models or user reporting, which can be inflexible or slow. Recent research suggests social signals, naturally exhibited by users in response to robot errors, can enable more flexible, timely error detection. However, most studies rely on post hoc analysis, leaving their real-time effectiveness uncertain and lacking user-centric evaluation. In this work, we developed a proactive error detection system that combines user behavioral signals (facial action units and speech), user feedback, and error context for automatic error detection. In a study (N = 28), we compared our proactive system to a status quo reactive approach. Results show our system 1) reliably and flexibly detects error, 2) detects errors faster than the reactive approach, and 3) is perceived more favorably by users than the reactive one. We discuss recommendations for enabling robot error awareness in future HRI systems.
ERR@HRI 2024 Challenge: Multimodal Detection of Errors and Failures in Human-Robot Interactions
Jul 08, 2024Despite the recent advancements in robotics and machine learning (ML), the deployment of autonomous robots in our everyday lives is still an open challenge. This is due to multiple reasons among which are their frequent mistakes, such as interrupting people or having delayed responses, as well as their limited ability to understand human speech, i.e., failure in tasks like transcribing speech to text. These mistakes may disrupt interactions and negatively influence human perception of these robots. To address this problem, robots need to have the ability to detect human-robot interaction (HRI) failures. The ERR@HRI 2024 challenge tackles this by offering a benchmark multimodal dataset of robot failures during human-robot interactions (HRI), encouraging researchers to develop and benchmark multimodal machine learning models to detect these failures. We created a dataset featuring multimodal non-verbal interaction data, including facial, speech, and pose features from video clips of interactions with a robotic coach, annotated with labels indicating the presence or absence of robot mistakes, user awkwardness, and interaction ruptures, allowing for the training and evaluation of predictive models. Challenge participants have been invited to submit their multimodal ML models for detection of robot errors and to be evaluated against various performance metrics such as accuracy, precision, recall, F1 score, with and without a margin of error reflecting the time-sensitivity of these metrics. The results of this challenge will help the research field in better understanding the robot failures in human-robot interactions and designing autonomous robots that can mitigate their own errors after successfully detecting them.
Modeling Human Response to Robot Errors for Timely Error Detection
Aug 01, 2022

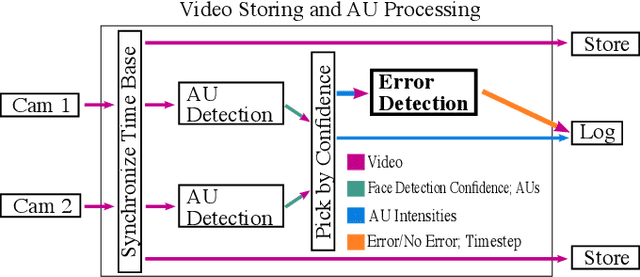
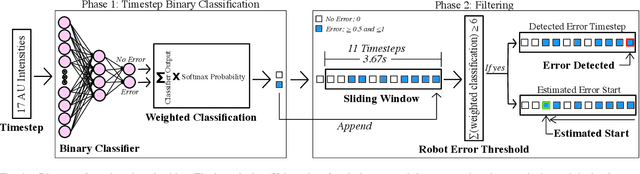
In human-robot collaboration, robot errors are inevitable -- damaging user trust, willingness to work together, and task performance. Prior work has shown that people naturally respond to robot errors socially and that in social interactions it is possible to use human responses to detect errors. However, there is little exploration in the domain of non-social, physical human-robot collaboration such as assembly and tool retrieval. In this work, we investigate how people's organic, social responses to robot errors may be used to enable timely automatic detection of errors in physical human-robot interactions. We conducted a data collection study to obtain facial responses to train a real-time detection algorithm and a case study to explore the generalizability of our method with different task settings and errors. Our results show that natural social responses are effective signals for timely detection and localization of robot errors even in non-social contexts and that our method is robust across a variety of task contexts, robot errors, and user responses. This work contributes to robust error detection without detailed task specifications.
Reconstructing Sinus Anatomy from Endoscopic Video -- Towards a Radiation-free Approach for Quantitative Longitudinal Assessment
Mar 18, 2020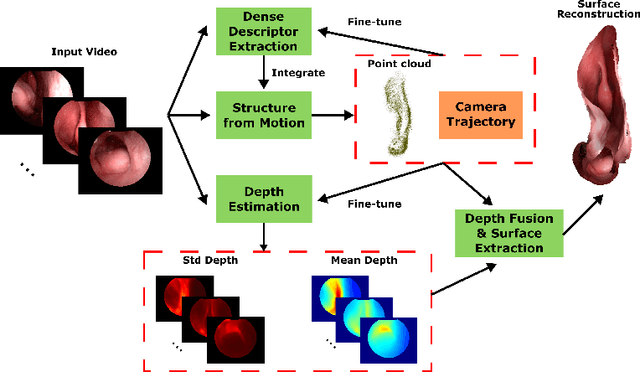
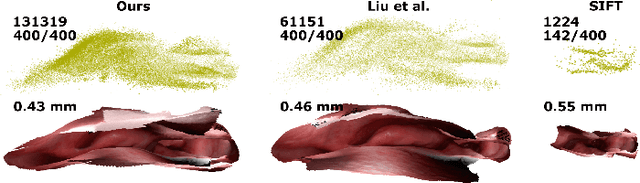
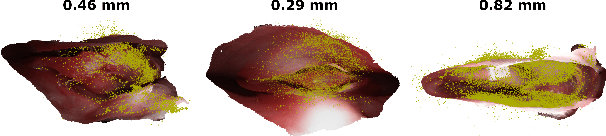
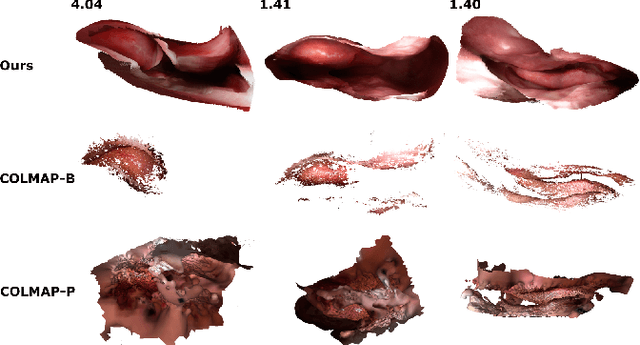
Reconstructing accurate 3D surface models of sinus anatomy directly from an endoscopic video is a promising avenue for cross-sectional and longitudinal analysis to better understand the relationship between sinus anatomy and surgical outcomes. We present a patient-specific, learning-based method for 3D reconstruction of sinus surface anatomy directly and only from endoscopic videos. We demonstrate the effectiveness and accuracy of our method on in and ex vivo data where we compare to sparse reconstructions from Structure from Motion, dense reconstruction from COLMAP, and ground truth anatomy from CT. Our textured reconstructions are watertight and enable measurement of clinically relevant parameters in good agreement with CT. The source code will be made publicly available upon publication.