 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating Associational Biases in Inter-Model Communication of Large Generative Models
Jan 29, 2026Social bias in generative AI can manifest not only as performance disparities but also as associational bias, whereby models learn and reproduce stereotypical associations between concepts and demographic groups, even in the absence of explicit demographic information (e.g., associating doctors with men). These associations can persist, propagate, and potentially amplify across repeated exchanges in inter-model communication pipelines, where one generative model's output becomes another's input. This is especially salient for human-centred perception tasks, such as human activity recognition and affect prediction, where inferences about behaviour and internal states can lead to errors or stereotypical associations that propagate into unequal treatment. In this work, focusing on human activity and affective expression, we study how such associations evolve within an inter-model communication pipeline that alternates between image generation and image description. Using the RAF-DB and PHASE datasets, we quantify demographic distribution drift induced by model-to-model information exchange and assess whether these drifts are systematic using an explainability pipeline. Our results reveal demographic drifts toward younger representations for both actions and emotions, as well as toward more female-presenting representations, primarily for emotions. We further find evidence that some predictions are supported by spurious visual regions (e.g., background or hair) rather than concept-relevant cues (e.g., body or face). We also examine whether these demographic drifts translate into measurable differences in downstream behaviour, i.e., while predicting activity and emotion labels. Finally, we outline mitigation strategies spanning data-centric, training and deployment interventions, and emphasise the need for careful safeguards when deploying interconnected models in human-centred AI systems.
Reimagining Social Robots as Recommender Systems: Foundations, Framework, and Applications
Jan 27, 2026Personalization in social robots refers to the ability of the robot to meet the needs and/or preferences of an individual user. Existing approaches typically rely on large language models (LLMs) to generate context-aware responses based on user metadata and historical interactions or on adaptive methods such as reinforcement learning (RL) to learn from users' immediate reactions in real time. However, these approaches fall short of comprehensively capturing user preferences-including long-term, short-term, and fine-grained aspects-, and of using them to rank and select actions, proactively personalize interactions, and ensure ethically responsible adaptations. To address the limitations, we propose drawing on recommender systems (RSs), which specialize in modeling user preferences and providing personalized recommendations. To ensure the integration of RS techniques is well-grounded and seamless throughout the social robot pipeline, we (i) align the paradigms underlying social robots and RSs, (ii) identify key techniques that can enhance personalization in social robots, and (iii) design them as modular, plug-and-play components. This work not only establishes a framework for integrating RS techniques into social robots but also opens a pathway for deep collaboration between the RS and HRI communities, accelerating innovation in both fields.
ERR@HRI 2.0 Challenge: Multimodal Detection of Errors and Failures in Human-Robot Conversations
Jul 17, 2025The integration of large language models (LLMs) into conversational robots has made human-robot conversations more dynamic. Yet, LLM-powered conversational robots remain prone to errors, e.g., misunderstanding user intent, prematurely interrupting users, or failing to respond altogether. Detecting and addressing these failures is critical for preventing conversational breakdowns, avoiding task disruptions, and sustaining user trust. To tackle this problem, the ERR@HRI 2.0 Challenge provides a multimodal dataset of LLM-powered conversational robot failures during human-robot conversations and encourages researchers to benchmark machine learning models designed to detect robot failures. The dataset includes 16 hours of dyadic human-robot interactions, incorporating facial, speech, and head movement features. Each interaction is annotated with the presence or absence of robot errors from the system perspective, and perceived user intention to correct for a mismatch between robot behavior and user expectation. Participants are invited to form teams and develop machine learning models that detect these failures using multimodal data. Submissions will be evaluated using various performance metrics, including detection accuracy and false positive rate. This challenge represents another key step toward improving failure detection in human-robot interaction through social signal analysis.
Critical Insights about Robots for Mental Wellbeing
Jun 16, 2025Social robots are increasingly being explored as tools to support emotional wellbeing, particularly in non-clinical settings. Drawing on a range of empirical studies and practical deployments, this paper outlines six key insights that highlight both the opportunities and challenges in using robots to promote mental wellbeing. These include (1) the lack of a single, objective measure of wellbeing, (2) the fact that robots don't need to act as companions to be effective, (3) the growing potential of virtual interactions, (4) the importance of involving clinicians in the design process, (5) the difference between one-off and long-term interactions, and (6) the idea that adaptation and personalization are not always necessary for positive outcomes. Rather than positioning robots as replacements for human therapists, we argue that they are best understood as supportive tools that must be designed with care, grounded in evidence, and shaped by ethical and psychological considerations. Our aim is to inform future research and guide responsible, effective use of robots in mental health and wellbeing contexts.
FG 2025 TrustFAA: the First Workshop on Towards Trustworthy Facial Affect Analysis: Advancing Insights of Fairness, Explainability, and Safety (TrustFAA)
Jun 05, 2025With the increasing prevalence and deployment of Emotion AI-powered facial affect analysis (FAA) tools, concerns about the trustworthiness of these systems have become more prominent. This first workshop on "Towards Trustworthy Facial Affect Analysis: Advancing Insights of Fairness, Explainability, and Safety (TrustFAA)" aims to bring together researchers who are investigating different challenges in relation to trustworthiness-such as interpretability, uncertainty, biases, and privacy-across various facial affect analysis tasks, including macro/ micro-expression recognition, facial action unit detection, other corresponding applications such as pain and depression detection, as well as human-robot interaction and collaboration. In alignment with FG2025's emphasis on ethics, as demonstrated by the inclusion of an Ethical Impact Statement requirement for this year's submissions, this workshop supports FG2025's efforts by encouraging research, discussion and dialogue on trustworthy FAA.
GraphAU-Pain: Graph-based Action Unit Representation for Pain Intensity Estimation
May 26, 2025Understanding pain-related facial behaviors is essential for digital healthcare in terms of effective monitoring, assisted diagnostics, and treatment planning, particularly for patients unable to communicate verbally. Existing data-driven methods of detecting pain from facial expressions are limited due to interpretability and severity quantification. To this end, we propose GraphAU-Pain, leveraging a graph-based framework to model facial Action Units (AUs) and their interrelationships for pain intensity estimation. AUs are represented as graph nodes, with co-occurrence relationships as edges, enabling a more expressive depiction of pain-related facial behaviors. By utilizing a relational graph neural network, our framework offers improved interpretability and significant performance gains. Experiments conducted on the publicly available UNBC dataset demonstrate the effectiveness of the GraphAU-Pain, achieving an F1-score of 66.21% and accuracy of 87.61% in pain intensity estimation.
REACT 2025: the Third Multiple Appropriate Facial Reaction Generation Challenge
May 22, 2025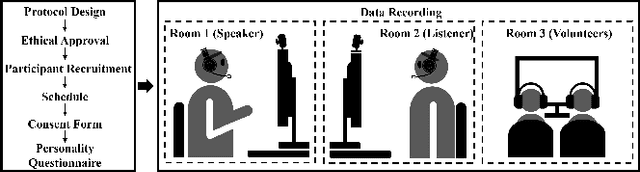

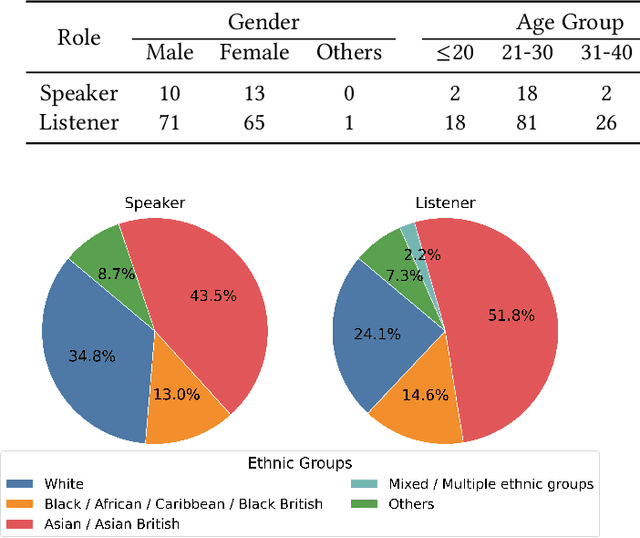
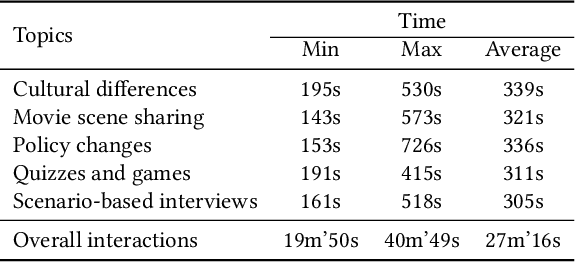
In dyadic interactions, a broad spectrum of human facial reactions might be appropriate for responding to each human speaker behaviour. Following the successful organisation of the REACT 2023 and REACT 2024 challenges, we are proposing the REACT 2025 challenge encouraging the development and benchmarking of Machine Learning (ML) models that can be used to generate multiple appropriate, diverse, realistic and synchronised human-style facial reactions expressed by human listeners in response to an input stimulus (i.e., audio-visual behaviours expressed by their corresponding speakers). As a key of the challenge, we provide challenge participants with the first natural and large-scale multi-modal MAFRG dataset (called MARS) recording 137 human-human dyadic interactions containing a total of 2856 interaction sessions covering five different topics. In addition, this paper also presents the challenge guidelines and the performance of our baselines on the two proposed sub-challenges: Offline MAFRG and Online MAFRG, respectively. The challenge baseline code is publicly available at https://github.com/reactmultimodalchallenge/baseline_react2025
Some Optimizers are More Equal: Understanding the Role of Optimizers in Group Fairness
Apr 21, 2025We study whether and how the choice of optimization algorithm can impact group fairness in deep neural networks. Through stochastic differential equation analysis of optimization dynamics in an analytically tractable setup, we demonstrate that the choice of optimization algorithm indeed influences fairness outcomes, particularly under severe imbalance. Furthermore, we show that when comparing two categories of optimizers, adaptive methods and stochastic methods, RMSProp (from the adaptive category) has a higher likelihood of converging to fairer minima than SGD (from the stochastic category). Building on this insight, we derive two new theoretical guarantees showing that, under appropriate conditions, RMSProp exhibits fairer parameter updates and improved fairness in a single optimization step compared to SGD. We then validate these findings through extensive experiments on three publicly available datasets, namely CelebA, FairFace, and MS-COCO, across different tasks as facial expression recognition, gender classification, and multi-label classification, using various backbones. Considering multiple fairness definitions including equalized odds, equal opportunity, and demographic parity, adaptive optimizers like RMSProp and Adam consistently outperform SGD in terms of group fairness, while maintaining comparable predictive accuracy. Our results highlight the role of adaptive updates as a crucial yet overlooked mechanism for promoting fair outcomes.
Comparing Self-Disclosure Themes and Semantics to a Human, a Robot, and a Disembodied Agent
Apr 08, 2025



As social robots and other artificial agents become more conversationally capable, it is important to understand whether the content and meaning of self-disclosure towards these agents changes depending on the agent's embodiment. In this study, we analysed conversational data from three controlled experiments in which participants self-disclosed to a human, a humanoid social robot, and a disembodied conversational agent. Using sentence embeddings and clustering, we identified themes in participants' disclosures, which were then labelled and explained by a large language model. We subsequently assessed whether these themes and the underlying semantic structure of the disclosures varied by agent embodiment. Our findings reveal strong consistency: thematic distributions did not significantly differ across embodiments, and semantic similarity analyses showed that disclosures were expressed in highly comparable ways. These results suggest that while embodiment may influence human behaviour in human-robot and human-agent interactions, people tend to maintain a consistent thematic focus and semantic structure in their disclosures, whether speaking to humans or artificial interlocutors.
AsyReC: A Multimodal Graph-based Framework for Spatio-Temporal Asymmetric Dyadic Relationship Classification
Apr 07, 2025Dyadic social relationships, which refer to relationships between two individuals who know each other through repeated interactions (or not), are shaped by shared spatial and temporal experiences. Current computational methods for modeling these relationships face three major challenges: (1) the failure to model asymmetric relationships, e.g., one individual may perceive the other as a friend while the other perceives them as an acquaintance, (2) the disruption of continuous interactions by discrete frame sampling, which segments the temporal continuity of interaction in real-world scenarios, and (3) the limitation to consider periodic behavioral cues, such as rhythmic vocalizations or recurrent gestures, which are crucial for inferring the evolution of dyadic relationships. To address these challenges, we propose AsyReC, a multimodal graph-based framework for asymmetric dyadic relationship classification, with three core innovations: (i) a triplet graph neural network with node-edge dual attention that dynamically weights multimodal cues to capture interaction asymmetries (addressing challenge 1); (ii) a clip-level relationship learning architecture that preserves temporal continuity, enabling fine-grained modeling of real-world interaction dynamics (addressing challenge 2); and (iii) a periodic temporal encoder that projects time indices onto sine/cosine waveforms to model recurrent behavioral patterns (addressing challenge 3). Extensive experiments on two public datasets demonstrate state-of-the-art performance, while ablation studies validate the critical role of asymmetric interaction modeling and periodic temporal encoding in improving the robustness of dyadic relationship classification in real-world scenarios. Our code is publicly available at: https://github.com/tw-repository/AsyReC.