 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCalling for Backup: How Children Navigate Successive Robot Communication Failures
Jan 02, 2026How do children respond to repeated robot errors? While prior research has examined adult reactions to successive robot errors, children's responses remain largely unexplored. In this study, we explore children's reactions to robot social errors and performance errors. For the latter, this study reproduces the successive robot failure paradigm of Liu et al. with child participants (N=59, ages 8-10) to examine how young users respond to repeated robot conversational errors. Participants interacted with a robot that failed to understand their prompts three times in succession, with their behavioral responses video-recorded and analyzed. We found both similarities and differences compared to adult responses from the original study. Like adults, children adjusted their prompts, modified their verbal tone, and exhibited increasingly emotional non-verbal responses throughout successive errors. However, children demonstrated more disengagement behaviors, including temporarily ignoring the robot or actively seeking an adult. Errors did not affect participants' perception of the robot, suggesting more flexible conversational expectations in children. These findings inform the design of more effective and developmentally appropriate human-robot interaction systems for young users.
ERR@HRI 2.0 Challenge: Multimodal Detection of Errors and Failures in Human-Robot Conversations
Jul 17, 2025The integration of large language models (LLMs) into conversational robots has made human-robot conversations more dynamic. Yet, LLM-powered conversational robots remain prone to errors, e.g., misunderstanding user intent, prematurely interrupting users, or failing to respond altogether. Detecting and addressing these failures is critical for preventing conversational breakdowns, avoiding task disruptions, and sustaining user trust. To tackle this problem, the ERR@HRI 2.0 Challenge provides a multimodal dataset of LLM-powered conversational robot failures during human-robot conversations and encourages researchers to benchmark machine learning models designed to detect robot failures. The dataset includes 16 hours of dyadic human-robot interactions, incorporating facial, speech, and head movement features. Each interaction is annotated with the presence or absence of robot errors from the system perspective, and perceived user intention to correct for a mismatch between robot behavior and user expectation. Participants are invited to form teams and develop machine learning models that detect these failures using multimodal data. Submissions will be evaluated using various performance metrics, including detection accuracy and false positive rate. This challenge represents another key step toward improving failure detection in human-robot interaction through social signal analysis.
The Robotability Score: Enabling Harmonious Robot Navigation on Urban Streets
Apr 15, 2025This paper introduces the Robotability Score ($R$), a novel metric that quantifies the suitability of urban environments for autonomous robot navigation. Through expert interviews and surveys, we identify and weigh key features contributing to R for wheeled robots on urban streets. Our findings reveal that pedestrian density, crowd dynamics and pedestrian flow are the most critical factors, collectively accounting for 28% of the total score. Computing robotability across New York City yields significant variation; the area of highest R is 3.0 times more "robotable" than the area of lowest R. Deployments of a physical robot on high and low robotability areas show the adequacy of the score in anticipating the ease of robot navigation. This new framework for evaluating urban landscapes aims to reduce uncertainty in robot deployment while respecting established mobility patterns and urban planning principles, contributing to the discourse on harmonious human-robot environments.
ERR@HRI 2024 Challenge: Multimodal Detection of Errors and Failures in Human-Robot Interactions
Jul 08, 2024Despite the recent advancements in robotics and machine learning (ML), the deployment of autonomous robots in our everyday lives is still an open challenge. This is due to multiple reasons among which are their frequent mistakes, such as interrupting people or having delayed responses, as well as their limited ability to understand human speech, i.e., failure in tasks like transcribing speech to text. These mistakes may disrupt interactions and negatively influence human perception of these robots. To address this problem, robots need to have the ability to detect human-robot interaction (HRI) failures. The ERR@HRI 2024 challenge tackles this by offering a benchmark multimodal dataset of robot failures during human-robot interactions (HRI), encouraging researchers to develop and benchmark multimodal machine learning models to detect these failures. We created a dataset featuring multimodal non-verbal interaction data, including facial, speech, and pose features from video clips of interactions with a robotic coach, annotated with labels indicating the presence or absence of robot mistakes, user awkwardness, and interaction ruptures, allowing for the training and evaluation of predictive models. Challenge participants have been invited to submit their multimodal ML models for detection of robot errors and to be evaluated against various performance metrics such as accuracy, precision, recall, F1 score, with and without a margin of error reflecting the time-sensitivity of these metrics. The results of this challenge will help the research field in better understanding the robot failures in human-robot interactions and designing autonomous robots that can mitigate their own errors after successfully detecting them.
A Study on Domain Generalization for Failure Detection through Human Reactions in HRI
Mar 10, 2024Machine learning models are commonly tested in-distribution (same dataset); performance almost always drops in out-of-distribution settings. For HRI research, the goal is often to develop generalized models. This makes domain generalization - retaining performance in different settings - a critical issue. In this study, we present a concise analysis of domain generalization in failure detection models trained on human facial expressions. Using two distinct datasets of humans reacting to videos where error occurs, one from a controlled lab setting and another collected online, we trained deep learning models on each dataset. When testing these models on the alternate dataset, we observed a significant performance drop. We reflect on the causes for the observed model behavior and leave recommendations. This work emphasizes the need for HRI research focusing on improving model robustness and real-life applicability.
A Systematic Review on Reproducibility in Child-Robot Interaction
Sep 04, 2023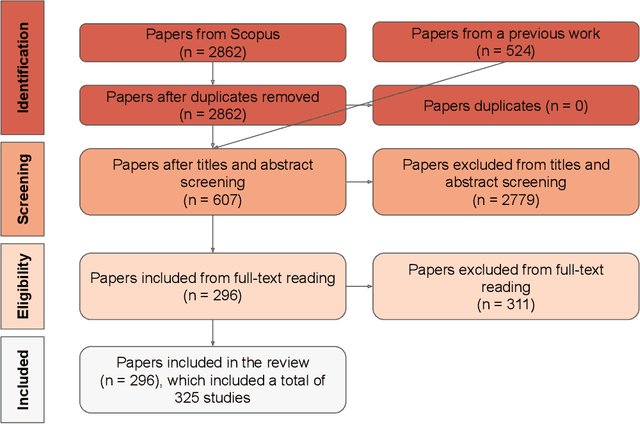
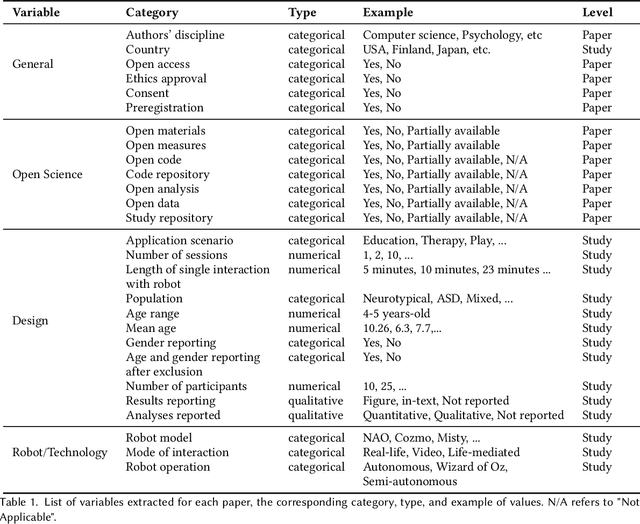
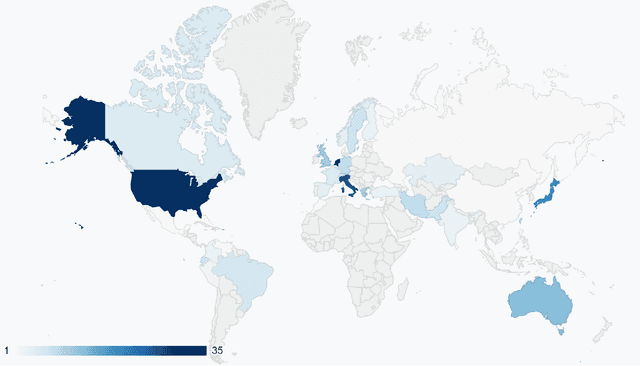
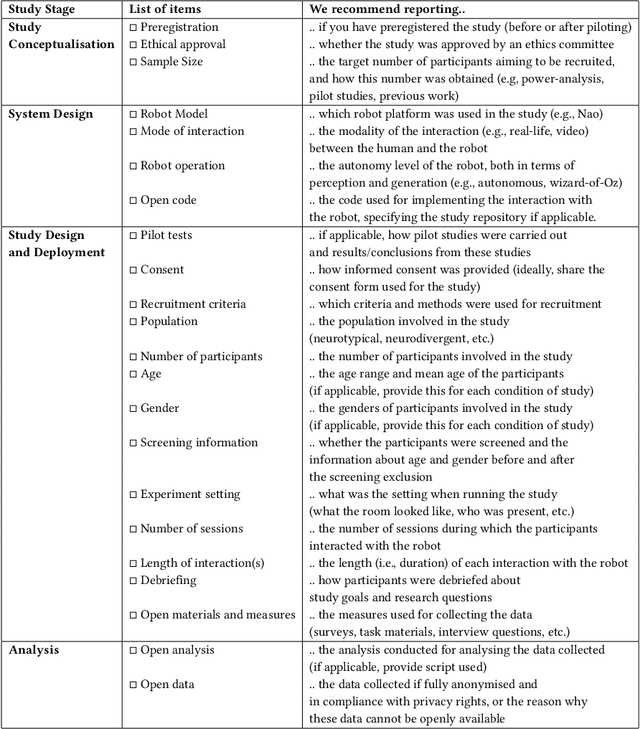
Research reproducibility - i.e., rerunning analyses on original data to replicate the results - is paramount for guaranteeing scientific validity. However, reproducibility is often very challenging, especially in research fields where multi-disciplinary teams are involved, such as child-robot interaction (CRI). This paper presents a systematic review of the last three years (2020-2022) of research in CRI under the lens of reproducibility, by analysing the field for transparency in reporting. Across a total of 325 studies, we found deficiencies in reporting demographics (e.g. age of participants), study design and implementation (e.g. length of interactions), and open data (e.g. maintaining an active code repository). From this analysis, we distill a set of guidelines and provide a checklist to systematically report CRI studies to help and guide research to improve reproducibility in CRI and beyond.
"How Did They Come Across?" Lessons Learned from Continuous Affective Ratings
Jul 07, 2023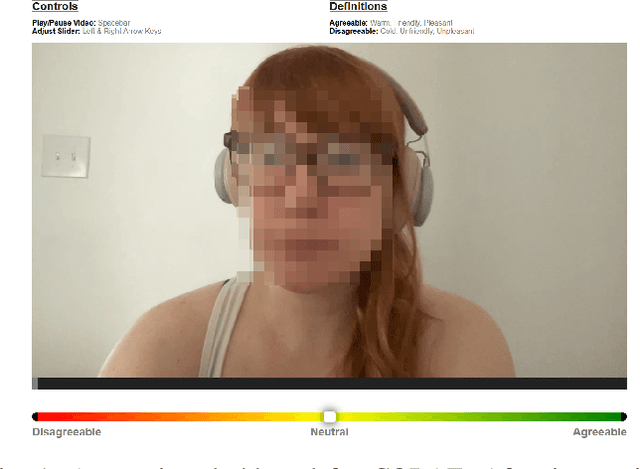
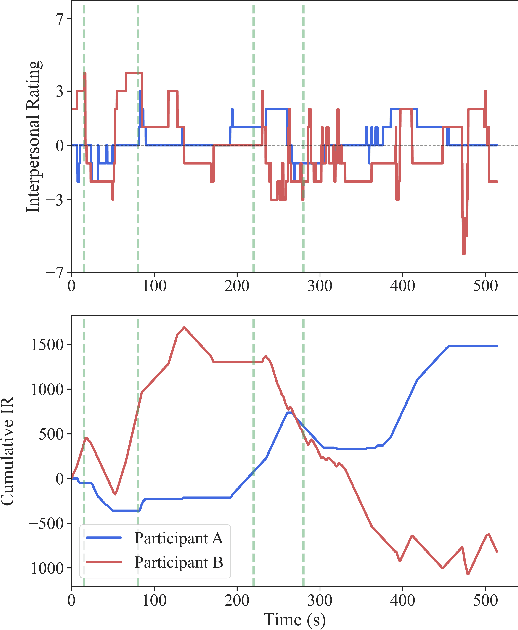

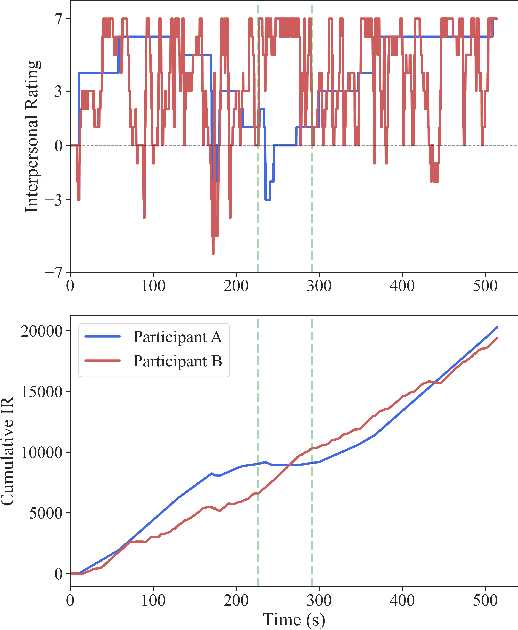
Social distance, or perception of the other, is recognized as a dynamic dimension of an interaction, but yet to be widely explored or understood. Through CORAE, a novel web-based open-source tool for COntinuous Retrospective Affect Evaluation, we collected retrospective ratings of interpersonal perceptions between 12 participant dyads. In this work, we explore how different aspects of these interactions reflect on the ratings collected, through a discourse analysis of individual and social behavior of the interactants. We found that different events observed in the ratings can be mapped to complex interaction phenomena, shedding light on relevant interaction features that may play a role in interpersonal understanding and grounding. This paves the way for better, more seamless human-robot interactions, where affect is interpreted as highly dynamic and contingent on interaction history.
* arXiv admin note: substantial text overlap with arXiv:2306.16629
What Could a Social Mediator Robot Do? Lessons from Real-World Mediation Scenarios
Jun 30, 2023

The use of social robots as instruments for social mediation has been gaining traction in the field of Human-Robot Interaction (HRI). So far, the design of such robots and their behaviors is often driven by technological platforms and experimental setups in controlled laboratory environments. To address complex social relationships in the real world, it is crucial to consider the actual needs and consequences of the situations found therein. This includes understanding when a mediator is necessary, what specific role such a robot could play, and how it moderates human social dynamics. In this paper, we discuss six relevant roles for robotic mediators that we identified by investigating a collection of videos showing realistic group situations. We further discuss mediation behaviors and target measures to evaluate the success of such interventions. We hope that our findings can inspire future research on robot-assisted social mediation by highlighting a wider set of mediation applications than those found in prior studies. Specifically, we aim to inform the categorization and selection of interaction scenarios that reflect real situations, where a mediation robot can have a positive and meaningful impact on group dynamics.
The Bystander Affect Detection (BAD) Dataset for Failure Detection in HRI
Mar 08, 2023



For a robot to repair its own error, it must first know it has made a mistake. One way that people detect errors is from the implicit reactions from bystanders -- their confusion, smirks, or giggles clue us in that something unexpected occurred. To enable robots to detect and act on bystander responses to task failures, we developed a novel method to elicit bystander responses to human and robot errors. Using 46 different stimulus videos featuring a variety of human and machine task failures, we collected a total of 2452 webcam videos of human reactions from 54 participants. To test the viability of the collected data, we used the bystander reaction dataset as input to a deep-learning model, BADNet, to predict failure occurrence. We tested different data labeling methods and learned how they affect model performance, achieving precisions above 90%. We discuss strategies to model bystander reactions and predict failure and how this approach can be used in real-world robotic deployments to detect errors and improve robot performance. As part of this work, we also contribute with the "Bystander Affect Detection" (BAD) dataset of bystander reactions, supporting the development of better prediction models.
Using Social Cues to Recognize Task Failures for HRI: A Review of Current Research and Future Directions
Jan 27, 2023



Robots that carry out tasks and interact in complex environments will inevitably commit errors. Error detection is thus an important ability for robots to master, to work in an efficient and productive way. People leverage social cues from others around them to recognize and repair their own mistakes. With advances in computing and AI, it is increasingly possible for robots to achieve a similar error detection capability. In this work, we review current literature around the topic of how social cues can be used to recognize task failures for human-robot interaction (HRI). This literature review unites insights from behavioral science, human-robot interaction, and machine learning, to focus on three areas: 1) social cues for error detection (from behavioral science), 2) recognizing task failures in robots (from HRI), and 3) approaches for autonomous detection of HRI task failures based on social cues (from machine learning). We propose a taxonomy of error detection based on self-awareness and social feedback. Finally, we leave recommendations for HRI researchers and practitioners interested in developing robots that detect (physical) task errors using social cues from bystanders.