 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSteering AI-Driven Personalization of Scientific Text for General Audiences
Nov 15, 2024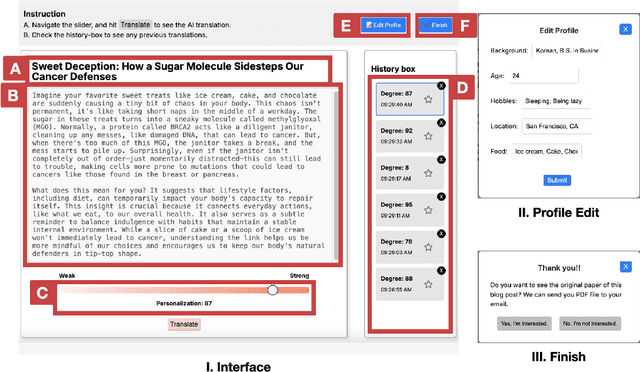
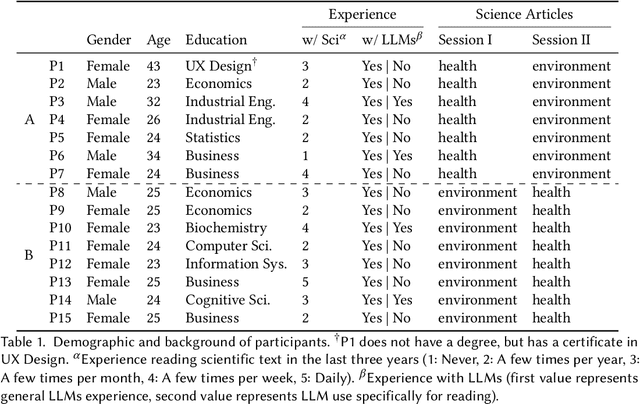

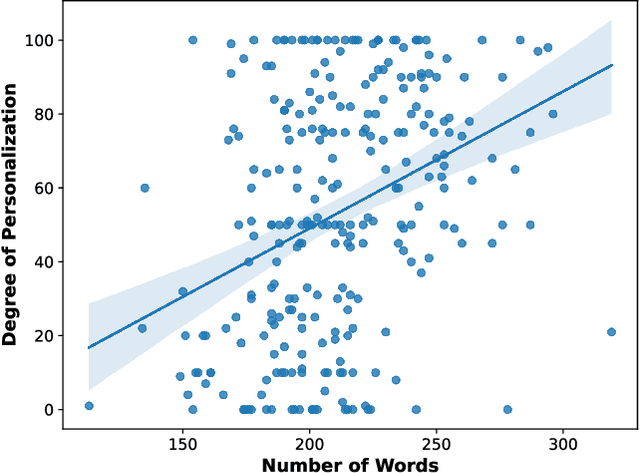
Digital media platforms (e.g., social media, science blogs) offer opportunities to communicate scientific content to general audiences at scale. However, these audiences vary in their scientific expertise, literacy levels, and personal backgrounds, making effective science communication challenging. To address this challenge, we designed TranSlider, an AI-powered tool that generates personalized translations of scientific text based on individual user profiles (e.g., hobbies, location, and education). Our tool features an interactive slider that allows users to steer the degree of personalization from 0 (weakly relatable) to 100 (strongly relatable), leveraging LLMs to generate the translations with given degrees. Through an exploratory study with 15 participants, we investigated both the utility of these AI-personalized translations and how interactive reading features influenced users' understanding and reading experiences. We found that participants who preferred higher degrees of personalization appreciated the relatable and contextual translations, while those who preferred lower degrees valued concise translations with subtle contextualization. Furthermore, participants reported the compounding effect of multiple translations on their understanding of scientific content. Given these findings, we discuss several implications of AI-personalized translation tools in facilitating communication in collaborative contexts.
A Study on Domain Generalization for Failure Detection through Human Reactions in HRI
Mar 10, 2024Machine learning models are commonly tested in-distribution (same dataset); performance almost always drops in out-of-distribution settings. For HRI research, the goal is often to develop generalized models. This makes domain generalization - retaining performance in different settings - a critical issue. In this study, we present a concise analysis of domain generalization in failure detection models trained on human facial expressions. Using two distinct datasets of humans reacting to videos where error occurs, one from a controlled lab setting and another collected online, we trained deep learning models on each dataset. When testing these models on the alternate dataset, we observed a significant performance drop. We reflect on the causes for the observed model behavior and leave recommendations. This work emphasizes the need for HRI research focusing on improving model robustness and real-life applicability.